O Presto é um mecanismo SQL de código aberto, distribuído em paralelo, para processamento de big data. Foi desenvolvido desde o início pelo Facebook. A primeira versão interna ocorreu em 2013 e foi uma solução bastante revolucionária para seus problemas de big data.
Com as centenas de servidores geolocalizados e petabytes de dados, o Facebook começou a procurar uma plataforma alternativa para seus clusters Hadoop. Sua equipe de infraestrutura queria reduzir o tempo necessário para executar trabalhos em lote de análise e simplificar o desenvolvimento de pipeline usando a linguagem de programação amplamente conhecida na organização - SQL.
De acordo com a fundação Presto, “o Facebook usa o Presto para consultas interativas em vários armazenamentos de dados internos, incluindo seu data warehouse de 300 PB. Mais de 1.000 funcionários do Facebook usam o Presto diariamente para executar mais de 30.000 consultas que, no total, varrem mais de um petabyte por dia.”
Embora o Facebook tenha um ambiente de armazenamento de dados excepcional, os mesmos desafios estão presentes em muitas organizações que lidam com big data.
Neste blog, veremos como configurar um ambiente presto básico usando um servidor Docker a partir do arquivo tar. Como fonte de dados, focaremos na fonte de dados MySQL, mas pode ser qualquer outro RDBMS popular.
Executando o Presto no ambiente de Big Data
Antes de começarmos, vamos dar uma olhada rápida em seus principais princípios de arquitetura. O Presto é uma alternativa às ferramentas que consultam o HDFS usando pipelines de trabalhos MapReduce - como o Hive. Ao contrário do Hive Presto não usa MapReduce. O Presto é executado com um mecanismo de execução de consultas para fins especiais com operadores de alto nível e processamento na memória.
Em contraste com o Hive Presto, pode transmitir dados através de todos os estágios ao mesmo tempo, executando blocos de dados simultaneamente. Ele foi projetado para executar consultas analíticas ad-hoc em fontes de dados heterogêneas únicas ou distribuídas. Ele pode acessar uma plataforma Hadoop para consultar bancos de dados relacionais ou outros armazenamentos de dados, como arquivos simples.
O Presto usa o SQL ANSI padrão, incluindo agregações, junções ou funções de janela analítica. SQL é bem conhecido e muito mais fácil de usar comparado ao MapReduce escrito em Java.
Implantando o Presto no Docker
A configuração básica do Presto pode ser implantada com uma imagem do Docker pré-configurada ou tarball do servidor presto.
O servidor docker e os contêineres Presto CLI podem ser facilmente implantados com:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliVocê pode escolher entre duas versões de servidor Presto. Versão comunitária e versão Enterprise da Starburst. Como vamos executá-lo em um ambiente de sandbox de não produção, usaremos a versão do Apache neste artigo.
Pré-requisitos
O Presto é implementado inteiramente em Java e requer que a JVM seja instalada em seu sistema. Ele roda em OpenJDK e Oracle Java. A versão mínima é Java 8u151 ou Java 11.
Para baixar o JAVA JDK visite https://openjdk.java.net/ ou https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Você pode verificar sua versão do Java com
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Instalação do Presto
Para instalar o Presto, vamos baixar o servidor tar e o executável jar do Presto CLI.
O tarball conterá um único diretório de nível superior, presto-server-0.223, que chamaremos de diretório de instalação.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoAlém disso, o Presto precisa de um diretório de dados para armazenar logs, etc.
É recomendável criar um diretório de dados fora do diretório de instalação.
$ mkdir -p ~/data/presto/Este local é o local em que iniciamos nossa solução de problemas.
Configurando o Presto
Antes de iniciarmos nossa primeira instância, precisamos criar vários arquivos de configuração. Comece com a criação de um diretório etc/ dentro do diretório de instalação. Este local conterá os seguintes arquivos de configuração:
etc/
- Propriedades do nó - configuração do ambiente do nó
- Configuração da JVM (jvm.config) - Configuração da máquina virtual Java
- Config Properties(config.properties) -configuração para o servidor Presto
- Propriedades do catálogo - configuração para conectores (fontes de dados)
- Propriedades do registro - Configuração dos registradores
Abaixo, você pode encontrar algumas configurações básicas para executar a sandbox do Presto. Para mais detalhes visite a documentação.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoA estrutura básica etc/ pode ter a seguinte aparência:

O próximo passo é configurar o conector MySQL.
Vamos nos conectar a um dos 3 nós do MariaDB Cluster.
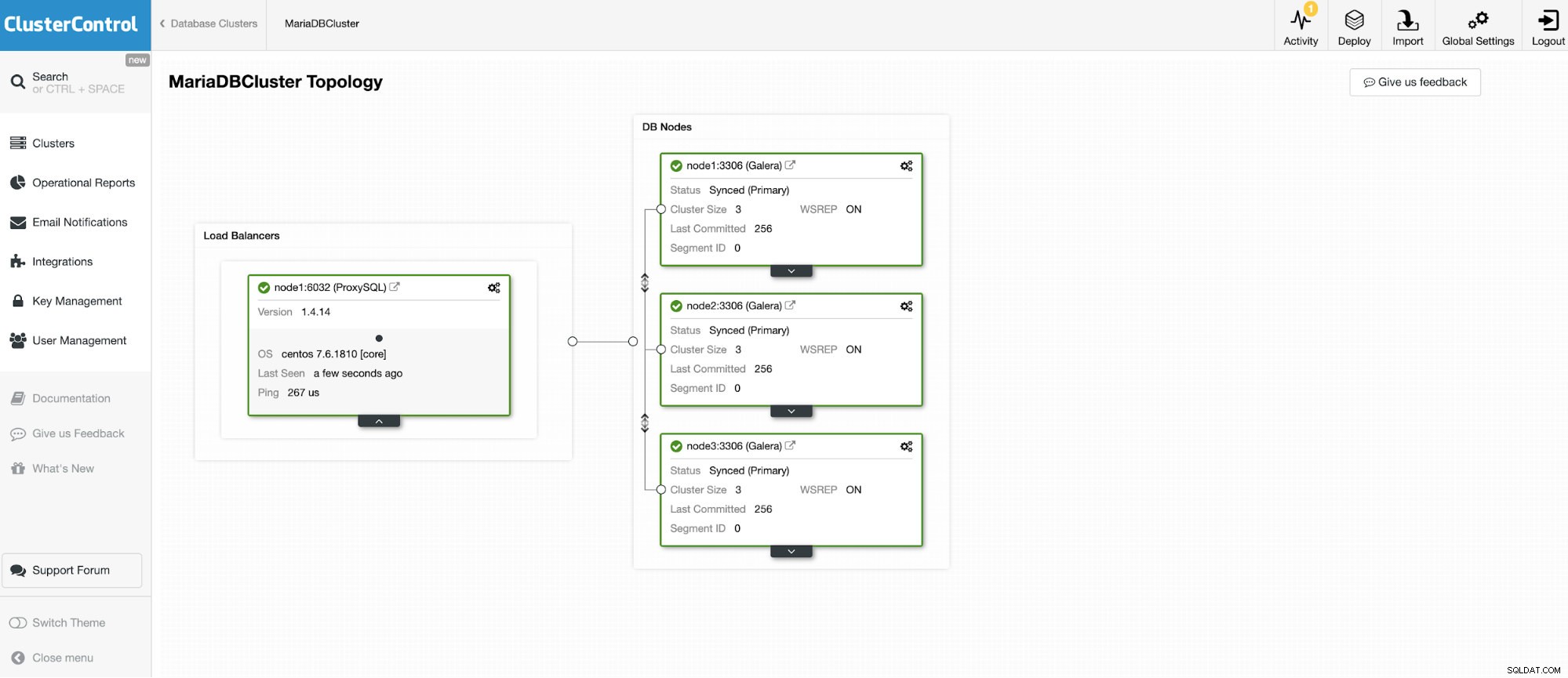
E outra instância autônoma executando o Oracle MySQL 5.7.
O conector MySQL permite consultar e criar tabelas em um banco de dados MySQL externo. Isso pode ser usado para juntar dados entre diferentes sistemas como MariaDB e MySQL da Oracle.
Presto usa conectores plugáveis e a configuração é muito fácil. Para configurar o conector MySQL, crie um arquivo de propriedades de catálogo em etc/catalog chamado, por exemplo, mysql.properties, para montar o conector MySQL como o catálogo mysql. Cada um dos arquivos representando uma conexão com outro servidor. Neste caso, temos dois arquivos:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretExecutando o Presto
Quando tudo estiver definido, é hora de iniciar a instância do Presto. Para iniciar o presto, vá para o diretório bin na instalação do Presto e execute o seguinte:
$ bin/launcher start
Started as 18363Para parar a execução do Presto
$ bin/launcher stopAgora, quando o servidor estiver funcionando, podemos nos conectar ao Presto com CLI e consultar o banco de dados MySQL.
Para iniciar o console Presto, execute:
./presto --server localhost:8080 --catalog mysql --schema employeesAgora podemos consultar nossos bancos de dados via CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]Ambos os bancos de dados MariaDB cluster e MySQL foram alimentados com banco de dados de funcionários.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlO status da consulta também é visível no console web do Presto:https://localhost:8080/ui/#
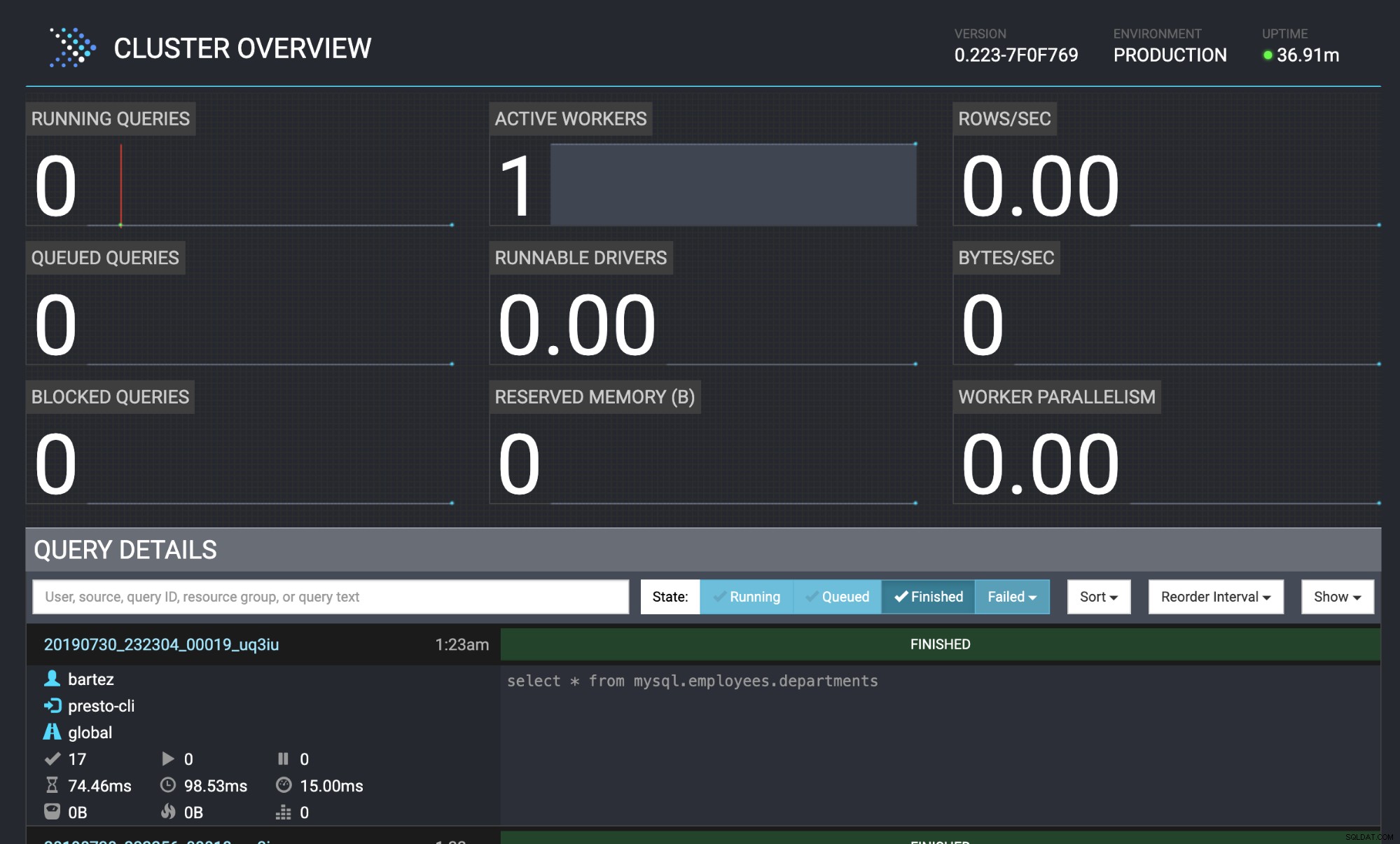 Visão geral do cluster Presto
Visão geral do cluster Presto Conclusão
Muitas empresas conhecidas (como Airbnb, Netflix, Twitter) estão adotando o Presto para desempenho de baixa latência. É sem dúvida um software muito interessante que pode eliminar a necessidade de executar processos pesados de data warehouse ETL. Neste blog, acabamos de dar uma breve olhada no conector MySQL, mas você pode usá-lo para analisar dados de HDFS, armazenamentos de objetos, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB e muitos outros.