Por que escolher a replicação MySQL?
Alguns conceitos básicos primeiro sobre a tecnologia de replicação. A replicação do MySQL não é complicada! É fácil de implementar, monitorar e ajustar, pois existem vários recursos que você pode aproveitar - o Google é um deles. O MySQL Replication não contém muitas variáveis de configuração para ajustar. Os erros lógicos de SQL_THREAD e IO_THREAD não são tão difíceis de entender e corrigir. A Replicação MySQL é muito popular hoje em dia e oferece uma maneira simples de implementar a Alta Disponibilidade de banco de dados. Recursos poderosos, como GTID (Global Transaction Identifier) em vez da posição de log binário antiquado, ou replicação semi-síncrona sem perdas o tornam mais robusto.
Como vimos em um post anterior, a latência de rede é um grande desafio ao selecionar uma solução de alta disponibilidade. Usar o MySQL Replication oferece a vantagem de não ser tão sensível à latência. Ele não implementa nenhuma replicação baseada em certificação, diferentemente do Galera Cluster usa técnicas de comunicação de grupo e ordenação de transações para obter a replicação síncrona. Assim, não há necessidade de que todos os nós tenham que certificar um conjunto de gravação e não há necessidade de esperar antes de uma confirmação no outro escravo ou réplica.
Escolher a Replicação MySQL tradicional com abordagem Primária-Secundária assíncrona fornece velocidade quando se trata de lidar com transações de dentro de seu mestre; ele não precisa esperar que os escravos sincronizem ou confirmem transações. A configuração normalmente tem um primário (mestre) e um ou mais secundários (escravos). Portanto, é um sistema de nada compartilhado, onde todos os servidores têm uma cópia completa dos dados por padrão. Claro que existem desvantagens. A integridade dos dados pode ser um problema se seus escravos não conseguirem replicar devido a erros de thread de E/S e SQL ou travamentos. Como alternativa, para resolver problemas de integridade de dados, você pode optar por implementar a Replicação do MySQL sendo semi-síncrona (ou chamada de replicação semi-síncrona sem perdas no MySQL 5.7). Como isso funciona, o mestre tem que esperar até que uma réplica reconheça todos os eventos da transação. Isso significa que ele precisa terminar suas gravações em um log de retransmissão e liberar para o disco antes de enviar de volta ao mestre com uma resposta ACK. Com a replicação semi-síncrona habilitada, os threads ou sessões no mestre precisam aguardar o reconhecimento de uma réplica. Depois de obter uma resposta ACK da réplica, ele pode confirmar a transação. A ilustração abaixo mostra como o MySQL lida com a replicação semi-síncrona.
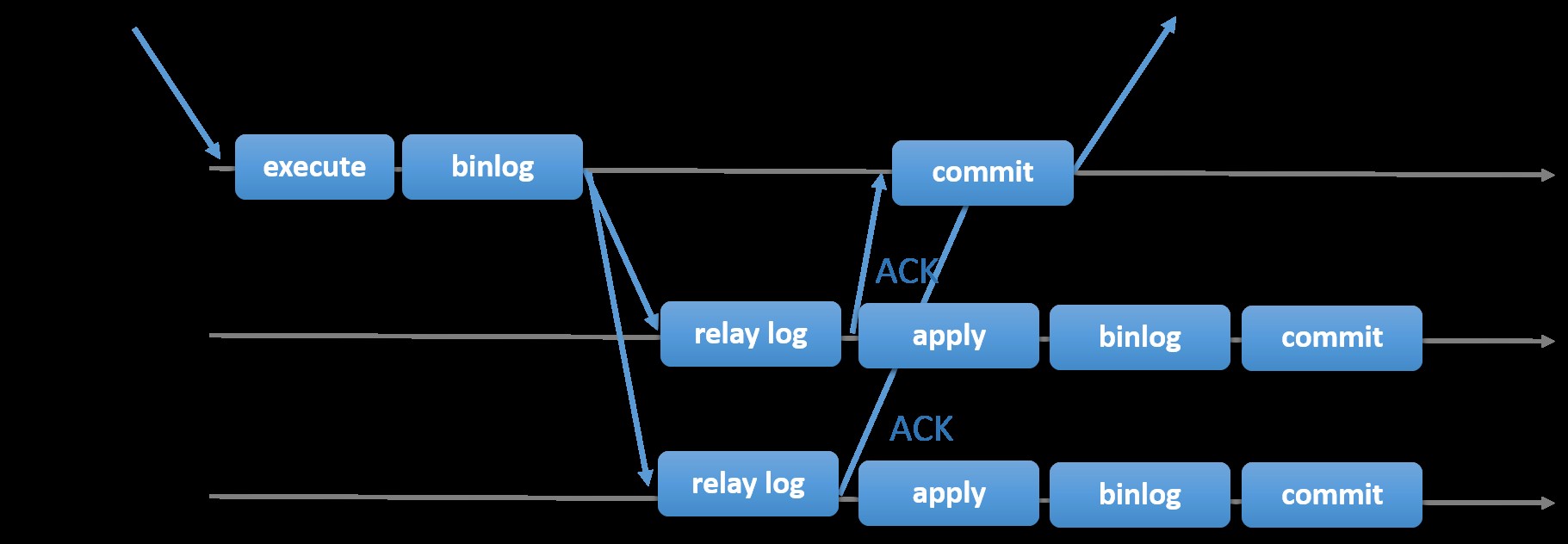 Imagem cortesia da documentação do MySQL
Imagem cortesia da documentação do MySQL Com esta implementação, todas as transações confirmadas já são replicadas para pelo menos um escravo em caso de falha do mestre. Embora semi-síncrono não represente por si só uma solução de alta disponibilidade, mas é um componente para sua solução. É melhor que você conheça suas necessidades e ajuste sua implementação de semi-sincronização de acordo. Portanto, se alguma perda de dados for aceitável, você poderá usar a replicação assíncrona tradicional.
A replicação baseada em GTID é útil para o DBA, pois simplifica a tarefa de fazer um failover, especialmente quando um escravo é apontado para outro mestre ou novo mestre. Isso significa que com um simples MASTER_AUTO_POSITION=1 após definir o host correto e as credenciais de replicação, ele começará a replicar do mestre sem a necessidade de encontrar e especificar as posições x e y do log binário correto. A adição de suporte à replicação paralela também aumenta os threads de replicação, pois adiciona velocidade para processar os eventos do log de retransmissão.
Assim, o MySQL Replication é um componente de ótima escolha em relação a outras soluções de HA, se atender às suas necessidades.
Topologias para replicação MySQL
A implantação do MySQL Replication em um ambiente multicloud com GCP (Google Cloud Platform) e AWS ainda é a mesma abordagem se você precisar replicar no local.
Existem várias topologias que você pode configurar e implementar.
Replicação Mestre com Escravo (Replicação Única)
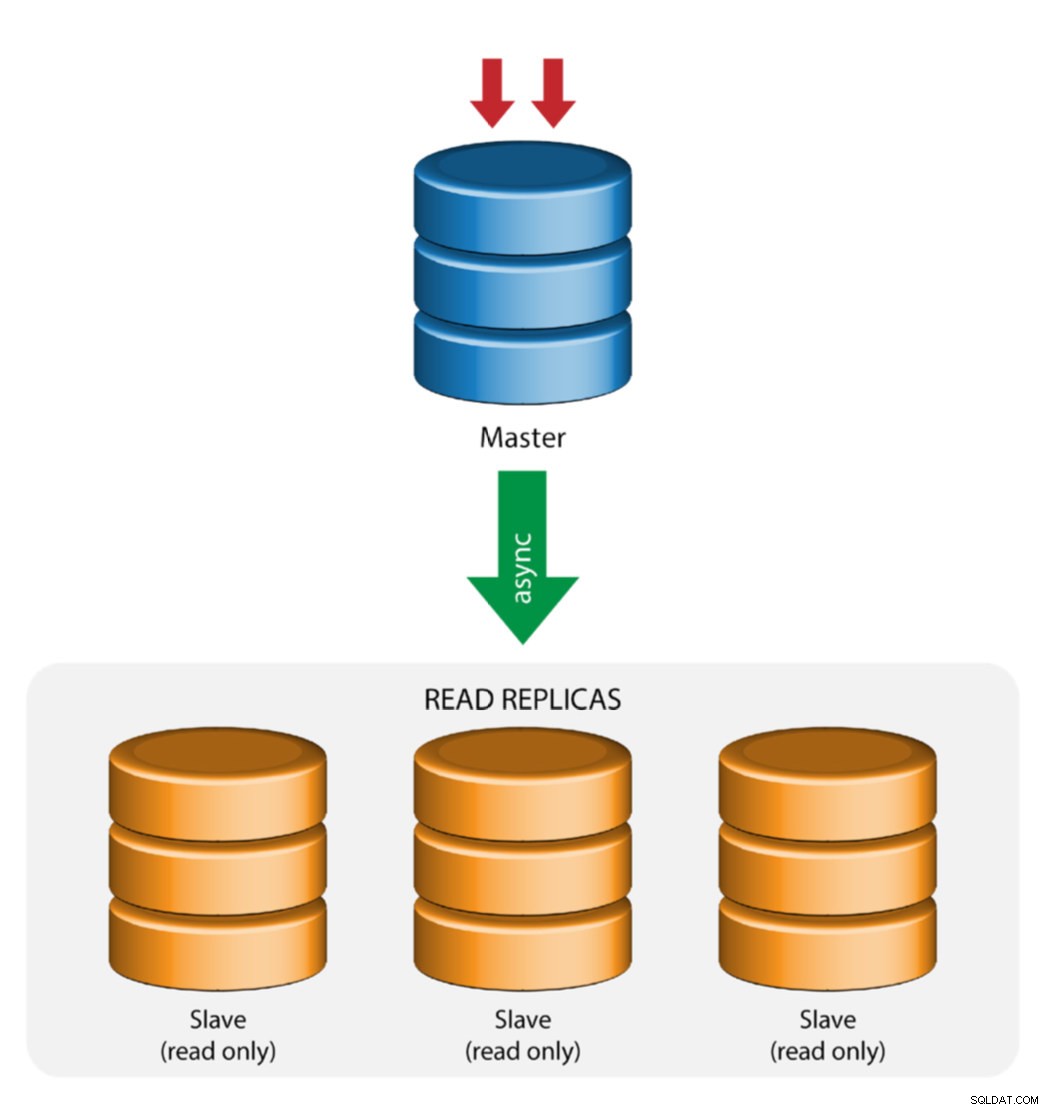
Esta é a topologia de replicação MySQL mais direta. Um mestre recebe gravações, um ou mais escravos replicam do mesmo mestre via replicação assíncrona ou semi-síncrona. Se o mestre designado cair, o escravo mais atualizado deve ser promovido como novo mestre. Os escravos restantes retomam a replicação do novo mestre.
Mestre com Relay Slaves (Replicação de Cadeia)
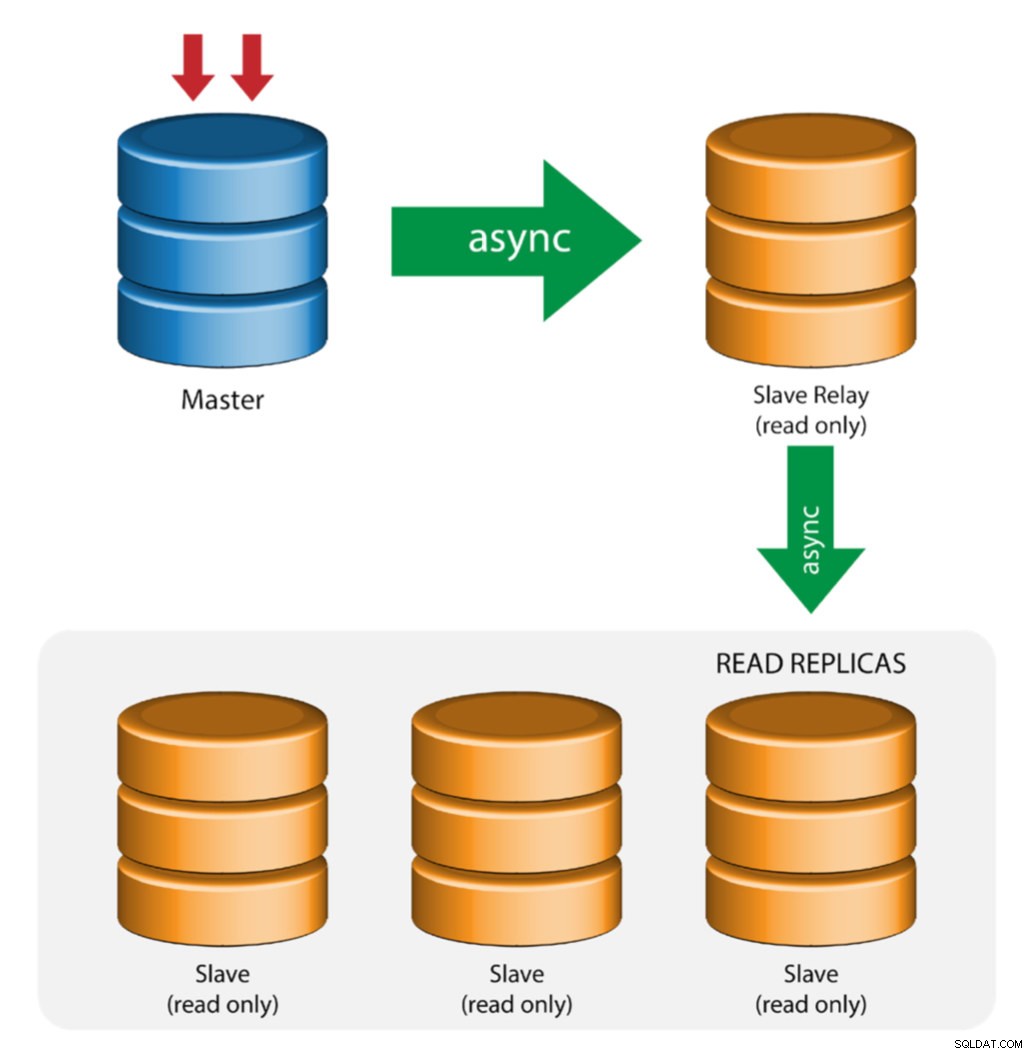
Essa configuração usa um mestre intermediário para atuar como um relé para os outros escravos na cadeia de replicação. Quando há muitos escravos conectados a um mestre, a interface de rede do mestre pode ficar sobrecarregada. Essa topologia permite que as réplicas de leitura extraiam o fluxo de replicação do servidor de retransmissão para descarregar o servidor mestre. No servidor de retransmissão escravo, o registro binário e log_slave_updates devem ser habilitados, de modo que as atualizações recebidas pelo servidor escravo do servidor mestre são registradas no próprio log binário do escravo.
Usar o relé escravo tem seus problemas:
- log_slave_updates tem alguma penalidade de desempenho.
- O atraso de replicação no servidor de retransmissão escravo gerará atraso em todos os seus escravos.
- As transações não autorizadas no servidor de retransmissão escravo infectarão todos os seus escravos.
- Se um servidor de retransmissão escravo falhar e você não estiver usando o GTID, todos os seus escravos pararão de replicar e eles precisarão ser reinicializados.
Mestre com Mestre Ativo (Replicação Circular)
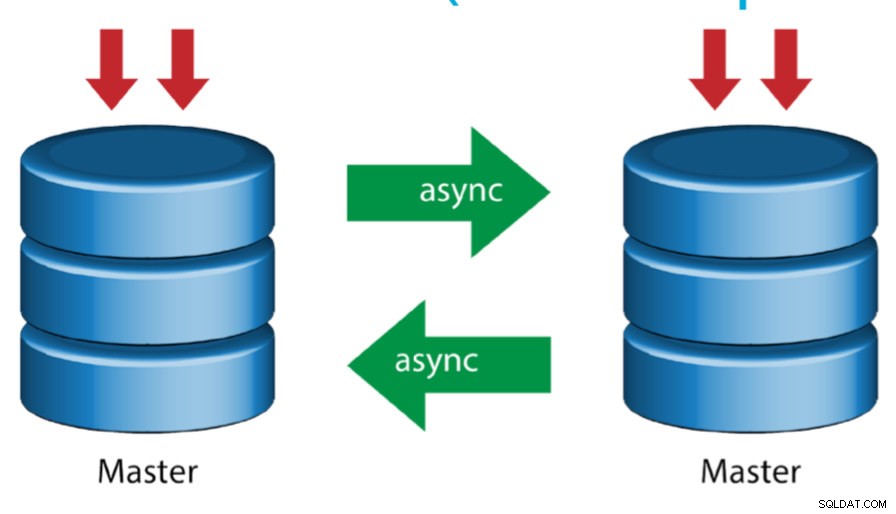
Também conhecida como topologia em anel, esta configuração requer dois ou mais servidores MySQL que atuam como mestre. Todos os mestres recebem gravações e geram logs binários com algumas ressalvas:
- Você precisa definir o deslocamento de incremento automático em cada servidor para evitar colisões de chave primária.
- Não há resolução de conflitos.
- Atualmente, o MySQL Replication não oferece suporte a nenhum protocolo de bloqueio entre mestre e escravo para garantir a atomicidade de uma atualização distribuída em dois servidores diferentes.
- A prática comum é gravar apenas em um mestre e o outro mestre atuar como um nó de espera ativa. Ainda assim, se você tiver escravos abaixo desse nível, precisará alternar para o novo mestre manualmente se o mestre designado falhar.
- O ClusterControl oferece suporte a essa topologia (não recomendamos vários gravadores em uma configuração de replicação). Consulte este blog anterior sobre como implantar com o ClusterControl.
Mestre com mestre de backup (replicação múltipla)
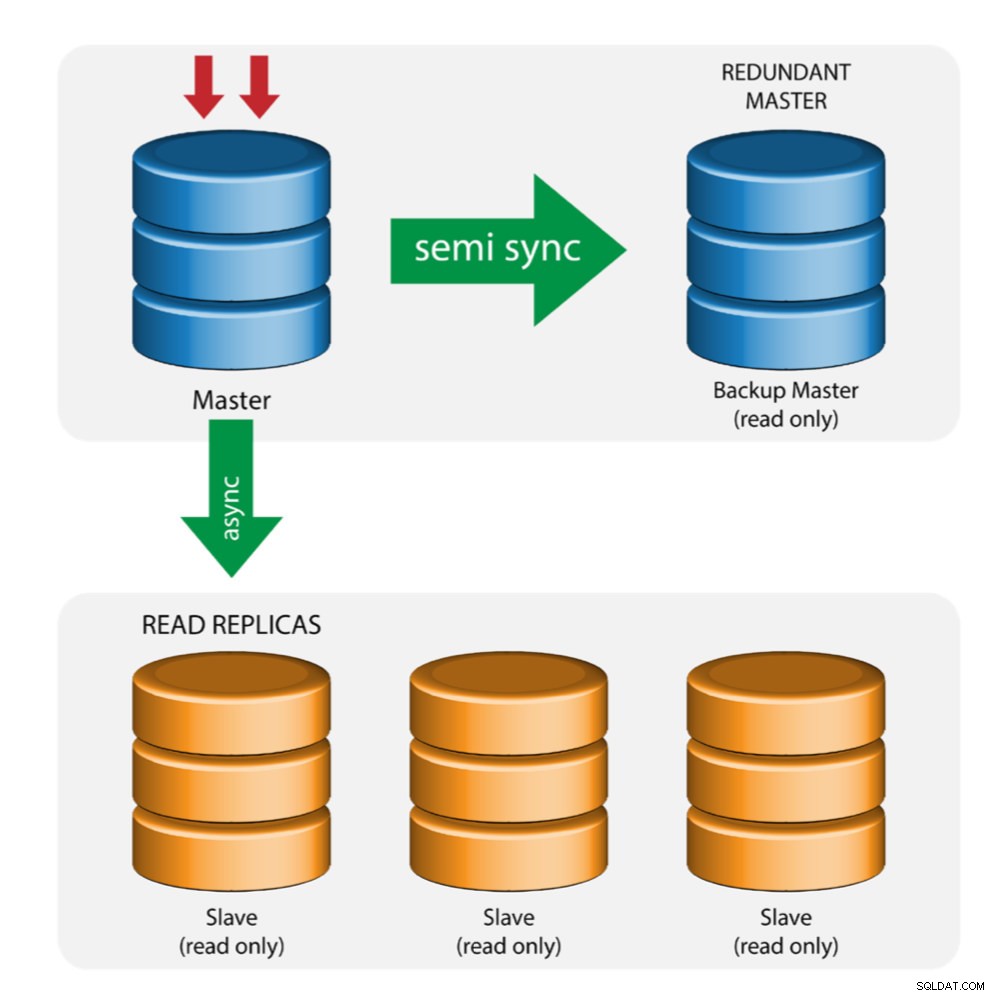
O mestre envia as alterações para um mestre de backup e para um ou mais escravos. A replicação semi-síncrona é usada entre o mestre e o mestre de backup. O mestre envia a atualização para o mestre de backup e aguarda a confirmação da transação. O mestre de backup obtém atualizações, grava em seu log de retransmissão e libera para o disco. O mestre de backup então confirma o recebimento da transação para o mestre e prossegue com a confirmação da transação. A replicação semi-síncrona tem um impacto no desempenho, mas o risco de perda de dados é minimizado.
Essa topologia funciona bem ao realizar o failover mestre caso o mestre fique inativo. O mestre de backup atua como um servidor de espera a quente, pois tem a maior probabilidade de ter dados atualizados quando comparado a outros escravos.
Vários mestres para um único escravo (replicação de várias origens)
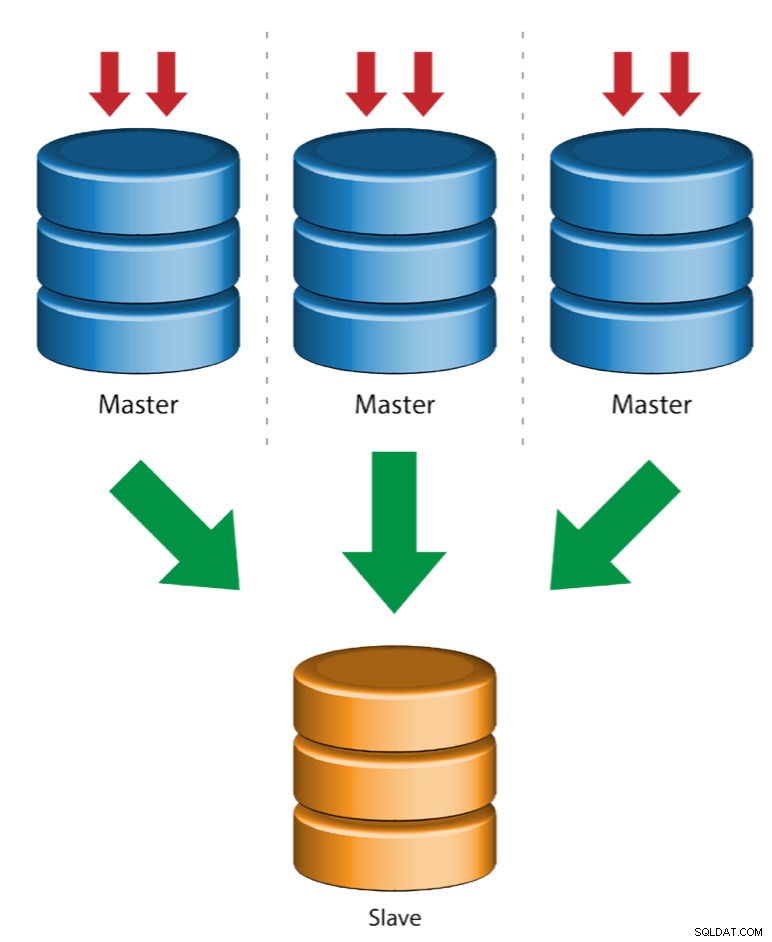
A Replicação de várias origens permite que um escravo de replicação receba transações de várias origens simultaneamente. A replicação de várias origens pode ser usada para fazer backup de vários servidores em um único servidor, para mesclar fragmentos de tabela e consolidar dados de vários servidores em um único servidor.
MySQL e MariaDB têm diferentes implementações de replicação multi-fonte, onde MariaDB deve ter GTID com gtid-domain-id configurado para distinguir as transações de origem, enquanto o MySQL usa um canal de replicação separado para cada mestre do qual o escravo replica. No MySQL, os mestres em uma topologia de replicação de várias origens podem ser configurados para usar replicação baseada em identificador de transação global (GTID) ou replicação baseada em posição de log binário.
Mais informações sobre a replicação de várias fontes do MariaDB podem ser encontradas nesta postagem do blog. Para MySQL, consulte a documentação do MySQL.
Galera com Replication Slave (Replicação Híbrida)
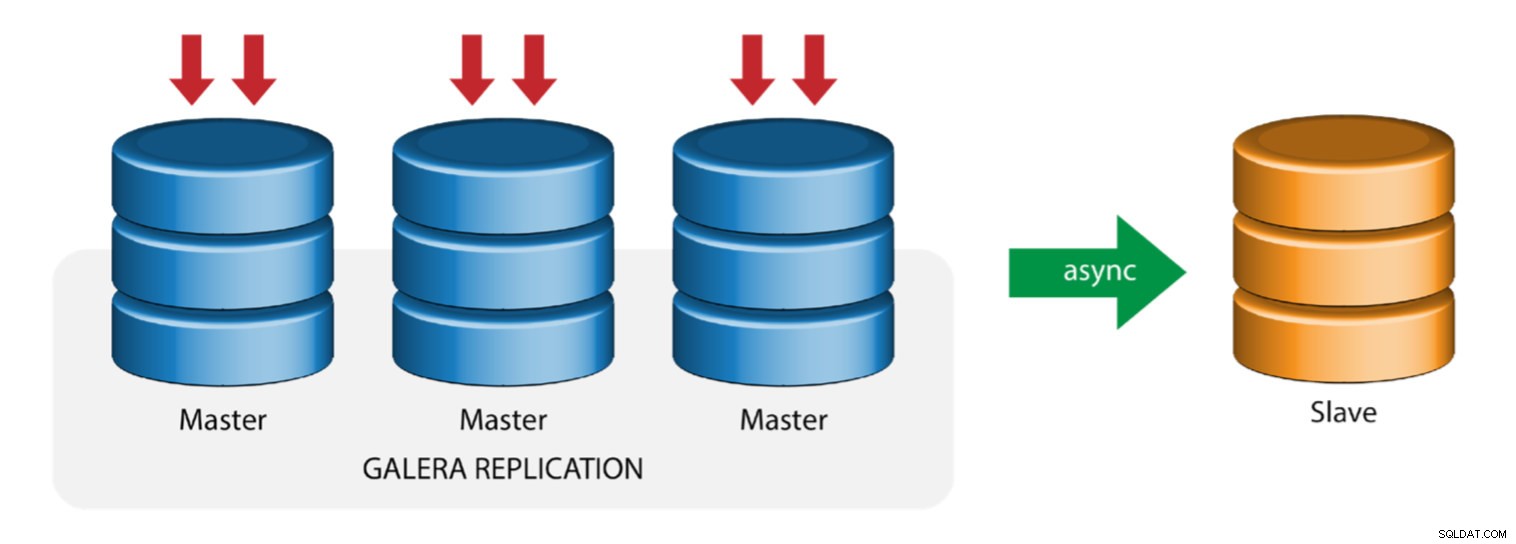
A replicação híbrida é uma combinação da replicação assíncrona do MySQL e da replicação virtualmente síncrona fornecida pelo Galera. A implantação agora é simplificada com a implementação do GTID na replicação do MySQL, onde configurar e executar o failover mestre tornou-se um processo direto no lado escravo.
O desempenho do cluster Galera é tão rápido quanto o nó mais lento. Ter um escravo de replicação assíncrona pode minimizar o impacto no cluster se você enviar consultas do tipo OLAP/relatório de longa execução para o escravo ou se executar trabalhos pesados que exigem bloqueios como mysqldump. O escravo também pode servir como backup ao vivo para recuperação de desastres no local e fora do local.
A replicação híbrida é suportada pelo ClusterControl e você pode implantá-la diretamente da interface do usuário do ClusterControl. Para obter mais informações sobre como fazer isso, leia as postagens do blog - Replicação híbrida com MySQL 5.6 e Replicação híbrida com MariaDB 10.x.
Preparando o GCP e as plataformas da AWS
O problema do "mundo real"
Neste blog, demonstraremos e usaremos a topologia "Multiple Replication" na qual instâncias em duas plataformas de nuvem pública diferentes se comunicarão usando a Replicação MySQL em diferentes regiões e em diferentes zonas de disponibilidade. Esse cenário é baseado em um problema do mundo real em que uma organização deseja arquitetar sua infraestrutura em várias plataformas de nuvem para escalabilidade, redundância, resiliência/tolerância a falhas. Conceitos semelhantes se aplicariam ao MongoDB ou PostgreSQL.
Vamos considerar uma organização dos EUA, com uma filial no sudeste da Ásia. Nosso tráfego é alto na região asiática. A latência deve ser baixa ao atender a gravações e leituras, mas, ao mesmo tempo, a região com base nos EUA também pode extrair registros provenientes do tráfego com base na Ásia.
O fluxo da arquitetura de nuvem
Nesta seção, discutirei o projeto arquitetônico. Primeiro, queremos oferecer uma camada altamente segura para que nossos nós Google Compute e AWS EC2 possam se comunicar, atualizar ou instalar pacotes da Internet, segura, altamente disponível caso uma AZ (zona de disponibilidade) fique inativa, possa replicar e comunicar-se com outra plataforma de nuvem por meio de uma camada segura. Veja a imagem abaixo para ilustração:

Com base na ilustração acima, na plataforma AWS, todos os nós estão sendo executados em diferentes zonas de disponibilidade. Ele tem uma sub-rede privada e pública para a qual todos os nós de computação estão em uma sub-rede privada. Portanto, ele pode sair da Internet para extrair e atualizar seus pacotes de sistema quando necessário. Possui um gateway VPN para o qual deve interagir com o GCP nesse canal, ignorando a Internet, mas por meio de um canal seguro e privado. Igual ao GCP, todos os nós de computação estão em zonas de disponibilidade diferentes, use o NAT Gateway para atualizar os pacotes do sistema quando necessário e use a conexão VPN para interagir com os nós da AWS hospedados em uma região diferente, ou seja, Ásia-Pacífico (Cingapura). Por outro lado, a região baseada nos EUA está hospedada em us-east1. Para acessar os nós, um nó na arquitetura serve como o bastion-node para o qual o usaremos como host de salto e instalaremos o ClusterControl. Isso será abordado mais adiante neste blog.
Configuração de ambientes GCP e AWS
Ao registrar sua primeira conta do GCP, o Google fornece uma conta VPC (Virtual Private Cloud) padrão. Portanto, é melhor criar uma VPC separada do padrão e personalizá-la de acordo com suas necessidades.
Nosso objetivo aqui é colocar os nós de computação em sub-redes privadas ou nós não serão configurados com IPv4 público. Portanto, ambas as nuvens públicas devem ser capazes de se comunicar. Os nós de computação AWS e GCP operam com CIDRs diferentes, conforme mencionado anteriormente. Assim, aqui estão os seguintes CIDR:
Nós de computação da AWS: 172.21.0.0/16
Nós de computação do GCP: 10.142.0.0/20
Nesta configuração da AWS, alocamos três sub-redes que não possuem Gateway de Internet, mas Gateway NAT; e uma sub-rede que possui um Gateway de Internet. Cada uma dessas sub-redes é hospedada individualmente em diferentes zonas de disponibilidade (AZ).
ap-southeast-1a =172.21.1.0/24
ap-sudeste-1b =172.21.8.0/24
ap-sudeste-1c =172.21.24.0/24
No GCP, a sub-rede padrão criada em uma VPC em us-east1, que é 10.142.0.0/20 CIDR, é usada. Portanto, estas são as etapas que você pode seguir para configurar sua plataforma de nuvem multipública.
-
Para este exercício, criei uma VPC na região us-east1 com a seguinte sub-rede de 10.142.0.0/20. Ver abaixo:

-
Reserve um IP estático. Este é o IP que iremos configurar como um Customer Gateway na AWS
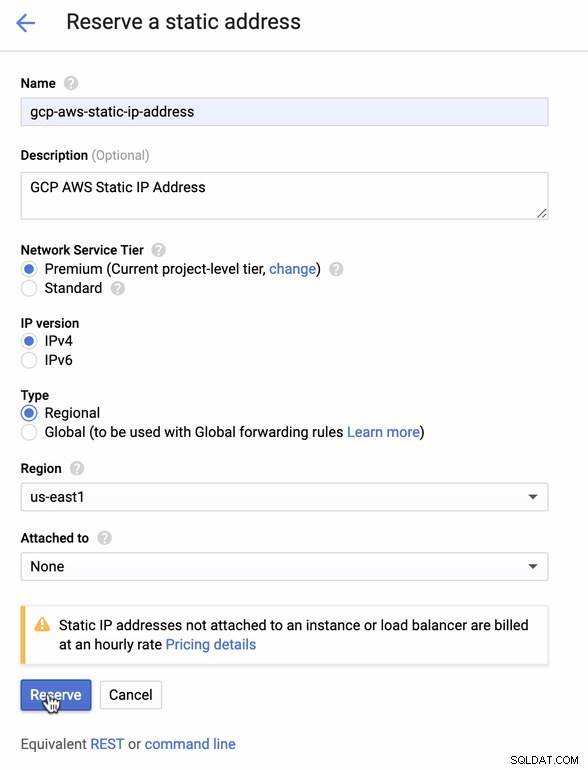
-
Como temos sub-redes instaladas (provisionadas como subnet-us-east1 ), acesse GCP -> Rede VPC -> Redes VPC e selecione a VPC que você criou e acesse as Regras de firewall . Nesta seção, adicione as regras especificando sua entrada e saída. Basicamente, essas são as regras de entrada/saída na AWS ou seu firewall para conexões de entrada e saída. Nesta configuração, abri todos os protocolos TCP do intervalo CIDR definido em minha VPC AWS e GCP para simplificar para os propósitos deste blog. Portanto, esta não é a maneira ideal para a segurança. Veja imagem abaixo:
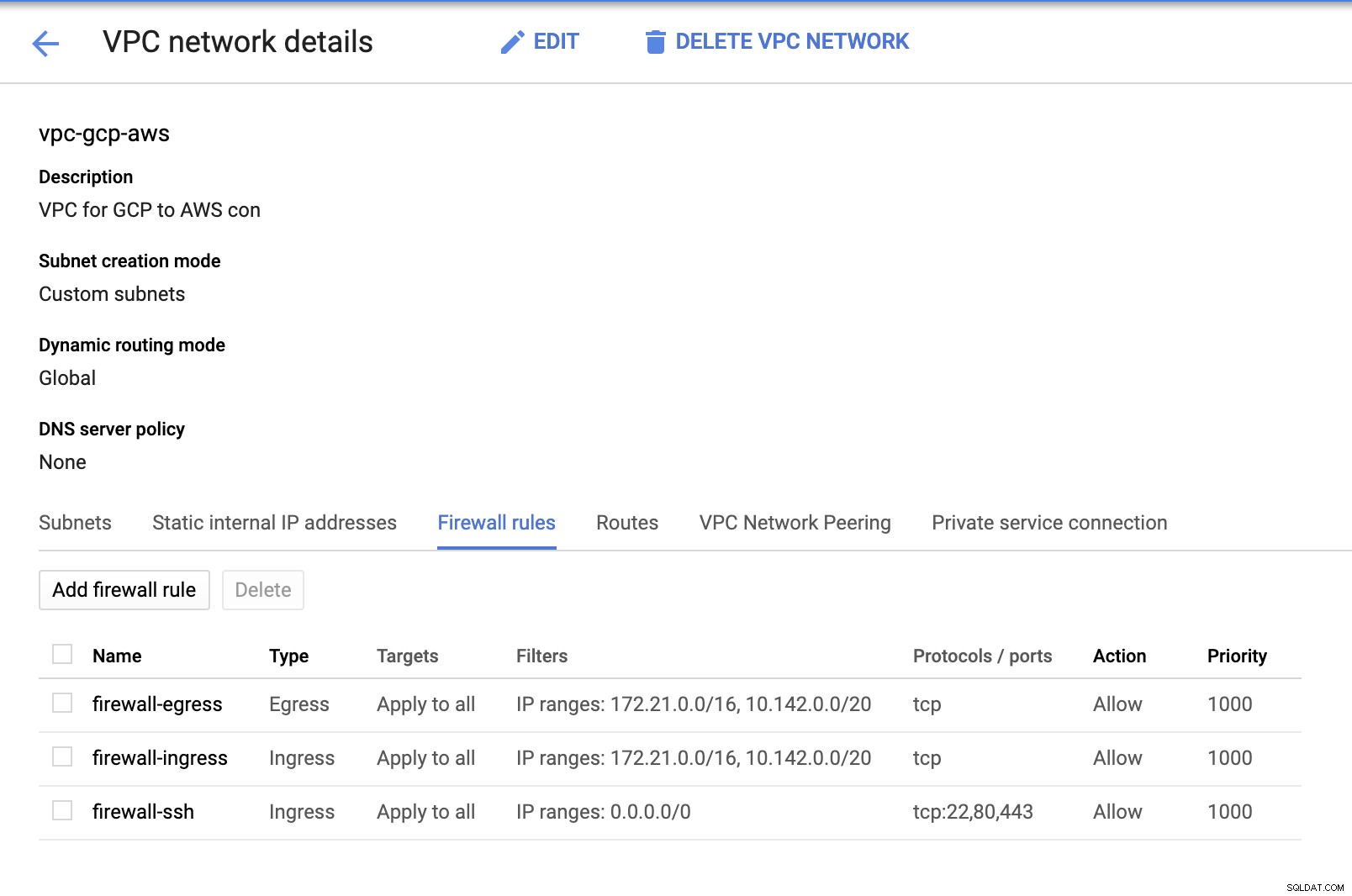
O firewall-ssh aqui será usado para permitir conexões de entrada ssh, HTTP e HTTPS.
-
Agora mude para a AWS e crie uma VPC. Para este blog, usei CIDR (Classless Inter-Domain Routing) 172.21.0.0/16
-
Crie as sub-redes para as quais você deve atribuí-las em cada AZ (Zona de Disponibilidade); e reserve pelo menos uma sub-rede para uma sub-rede pública que manipulará o NAT Gateway, e o restante é para nós EC2.

-
Em seguida, crie sua Tabela de Rotas e certifique-se de que "Destino" e "Destinos" estejam definidos corretamente. Para este blog, criei 2 tabelas de rotas. Um que lidará com os 3 AZ aos quais meus nós de computação serão atribuídos individualmente e será atribuído sem um gateway de Internet, pois não terá IP público. Em seguida, o outro tratará do Gateway NAT e terá um Gateway de Internet que estará na sub-rede pública. Veja imagem abaixo:

e, como mencionado, meu destino de exemplo para rota privada que lida com 3 sub-redes mostra ter um destino de gateway NAT mais um destino de gateway virtual que mencionarei posteriormente nas etapas de entrada.

-
Em seguida, crie um "Gateway da Internet" e atribua-o à VPC que foi criada anteriormente na seção AWS VPC. Este Gateway de Internet só deve ser definido como destino para a sub-rede pública, pois será o serviço que deverá se conectar à Internet. Obviamente, o nome significa como um serviço de gateway da Internet.
-
Em seguida, crie um "Gateway NAT". Ao criar um "Gateway NAT", verifique se você atribuiu seu NAT a uma sub-rede voltada para o público. O NAT Gateway é o seu canal para acessar a Internet a partir de sua sub-rede privada ou nós EC2 que não têm IPv4 público atribuído. Em seguida, crie ou atribua um EIP (IP Elastic), pois, na AWS, apenas os nós de computação que possuem IPv4 público atribuído podem se conectar diretamente à Internet.
-
Agora, em VPC -> Security -> Security Groups (SG) , sua VPC criada terá um SG padrão. Para esta configuração, criei "Regras de entrada" com fontes atribuídas para cada CIDR, ou seja, 10.142.0.0/20 no GCP e 172.21.0.0/16 na AWS. Ver abaixo:

Para "Regras de saída", você pode deixar como está, pois a atribuição de regras a "Regras de entrada" é bilateral, o que significa que também será aberta para "Regras de saída". Observe que essa não é a maneira ideal de definir seu grupo de segurança; mas para facilitar essa configuração, fiz um escopo mais amplo de alcance de portas e fonte também. Além disso, o protocolo é específico apenas para conexões TCP, pois não lidaremos com UDP para este blog.
Além disso, você pode deixar sua VPC -> Segurança -> Network ACLs intocado, desde que não NEGUE nenhuma conexão tcp do CIDR declarado em sua fonte.
-
Em seguida, definiremos a configuração da VPN que será hospedada na plataforma AWS. Em VPC -> Gateways do cliente , crie o gateway usando o endereço IP estático que foi criado anteriormente na etapa anterior. Dê uma olhada na imagem abaixo:
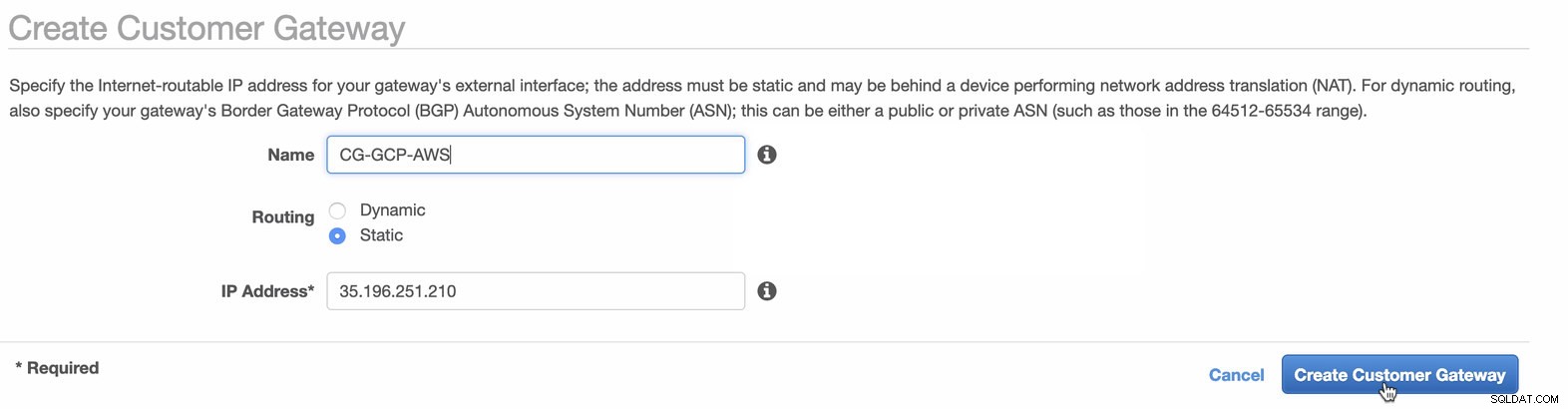
-
Em seguida, crie um Virtual Private Gateway e anexe-o à VPC atual que criamos anteriormente na etapa anterior. Veja imagem abaixo:

-
Agora, crie uma conexão VPN que será usada para a conexão site a site entre AWS e GCP. Ao criar uma conexão VPN, verifique se você selecionou o gateway privado virtual correto e o gateway do cliente que criamos nas etapas anteriores. Veja imagem abaixo:
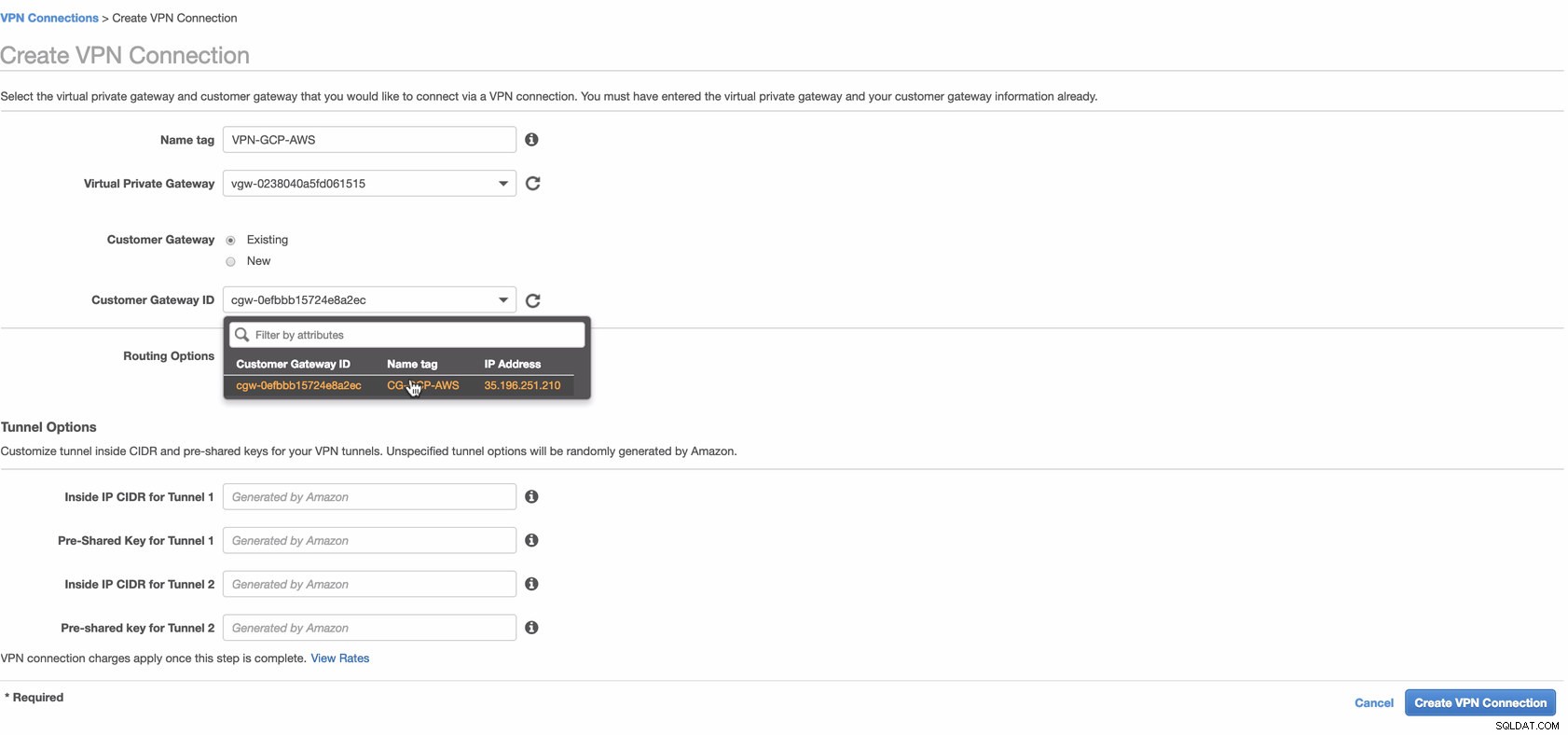
Isso pode levar algum tempo enquanto a AWS está criando sua conexão VPN. Quando sua conexão VPN for provisionada, você pode se perguntar por que, na guia Túnel (depois de selecionar sua conexão VPN), ele mostrará que o Endereço IP externo está para baixo. Isso é normal, pois ainda não há conexão estabelecida do cliente. Dê uma olhada na imagem de exemplo abaixo:

Quando a conexão VPN estiver pronta, selecione sua conexão VPN criada e baixe a configuração. Ele contém suas credenciais necessárias para as etapas a seguir para criar uma conexão VPN site a site com o cliente.
Observação: Caso você tenha configurado sua VPN onde IPSEC ESTÁ ATIVADO mas Status está PARA BAIXO igual a imagem abaixo

isso provavelmente se deve a valores incorretos definidos para os parâmetros específicos ao configurar sua sessão BGP ou roteador de nuvem. Confira aqui para solucionar problemas de sua VPN.
-
Como temos uma conexão VPN pronta hospedada na AWS, vamos criar uma conexão VPN no GCP. Agora, vamos voltar ao GCP e configurar a conexão do cliente lá. No GCP, acesse GCP -> Conectividade híbrida -> VPN . Verifique se você está escolhendo a região correta, que está neste blog, estamos usando us-east1 . Em seguida, selecione o endereço IP estático criado nas etapas anteriores. Veja imagem abaixo:
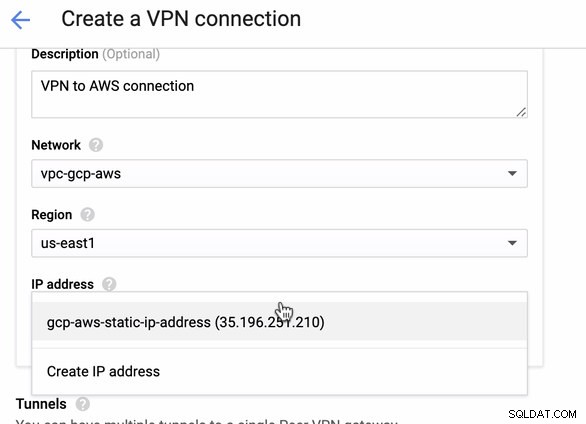
Em seguida, nos Túneis seção, é aqui que você terá que configurar com base nas credenciais baixadas da conexão VPN da AWS que você criou anteriormente. Sugiro verificar este guia útil do Google. Por exemplo, um dos túneis sendo configurados é mostrado na imagem abaixo:
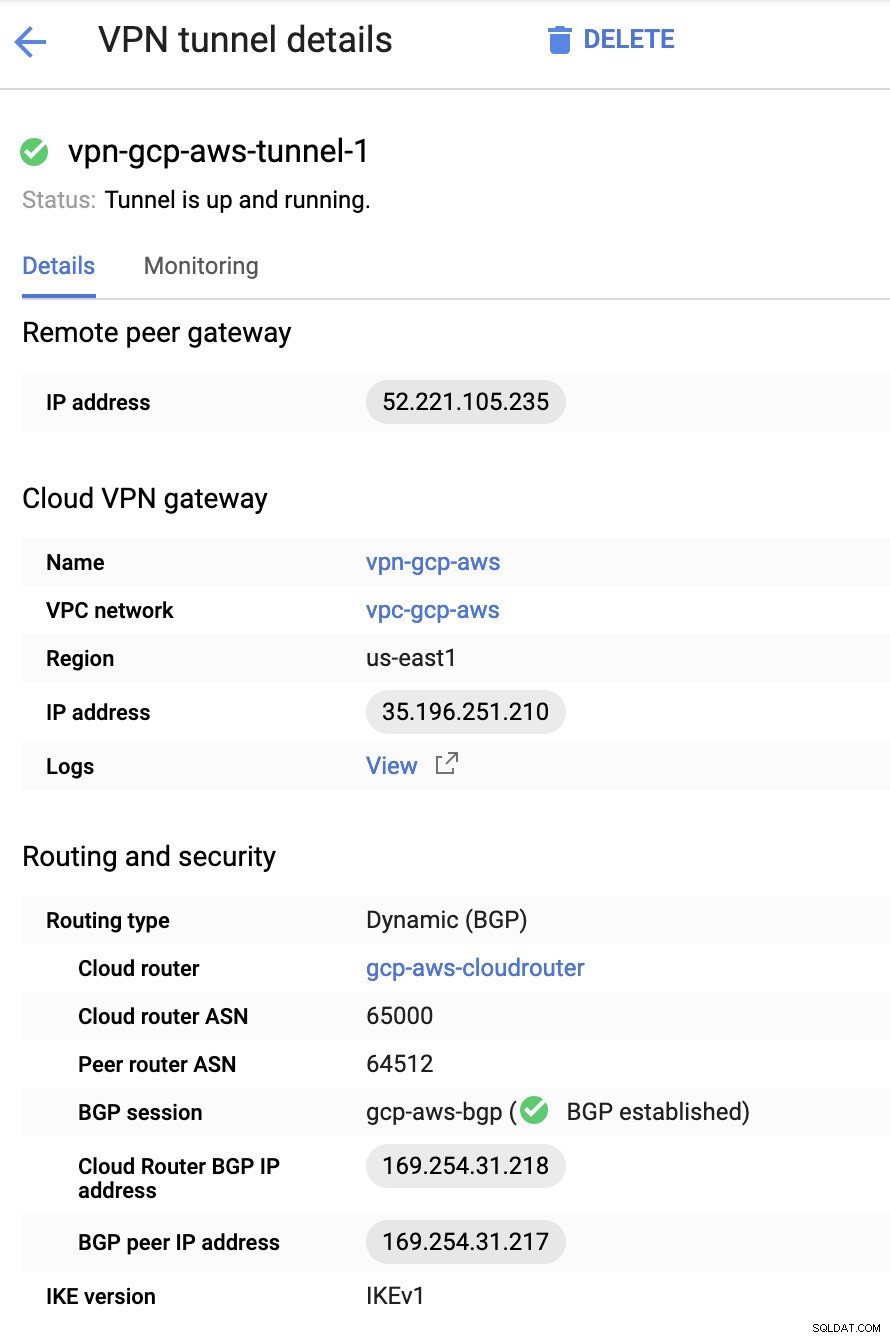
Basicamente, as coisas mais importantes aqui são as seguintes:
- Remote Peer Gateway:Endereço IP - Este é o IP do servidor VPN indicado em Detalhes do túnel -> Endereço IP externo . Isso não deve ser confundido com o IP estático que criamos no GCP. Esse é o gateway do Cloud VPN -> endereço IP embora.
- Cloud router ASN - Por padrão, a AWS usa 65000. Mas provavelmente, você obterá essas informações do arquivo de configuração baixado.
- ASN do roteador de mesmo nível - Este é o ASN do gateway privado virtual que se encontra no arquivo de configuração baixado.
- Endereço IP do Cloud Router BGP - Este é o Gateway do cliente encontrado no arquivo de configuração baixado.
- Endereço IP de peer BGP - Este é o Gateway privado virtual encontrado no arquivo de configuração baixado.
-
Dê uma olhada no arquivo de configuração de exemplo que tenho abaixo:
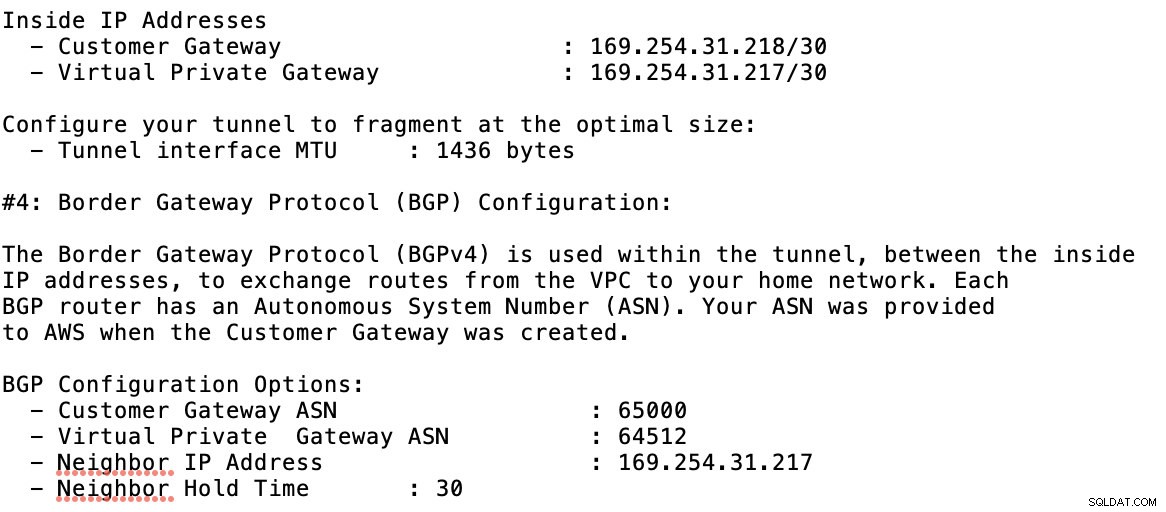
para o qual você deve corresponder a isso ao adicionar seu túnel sob o GCP -> Conectividade híbrida -> VPN configuração de conectividade. Veja a imagem abaixo para a qual criei um roteador de nuvem e uma sessão BGP durante a criação de um túnel de amostra:
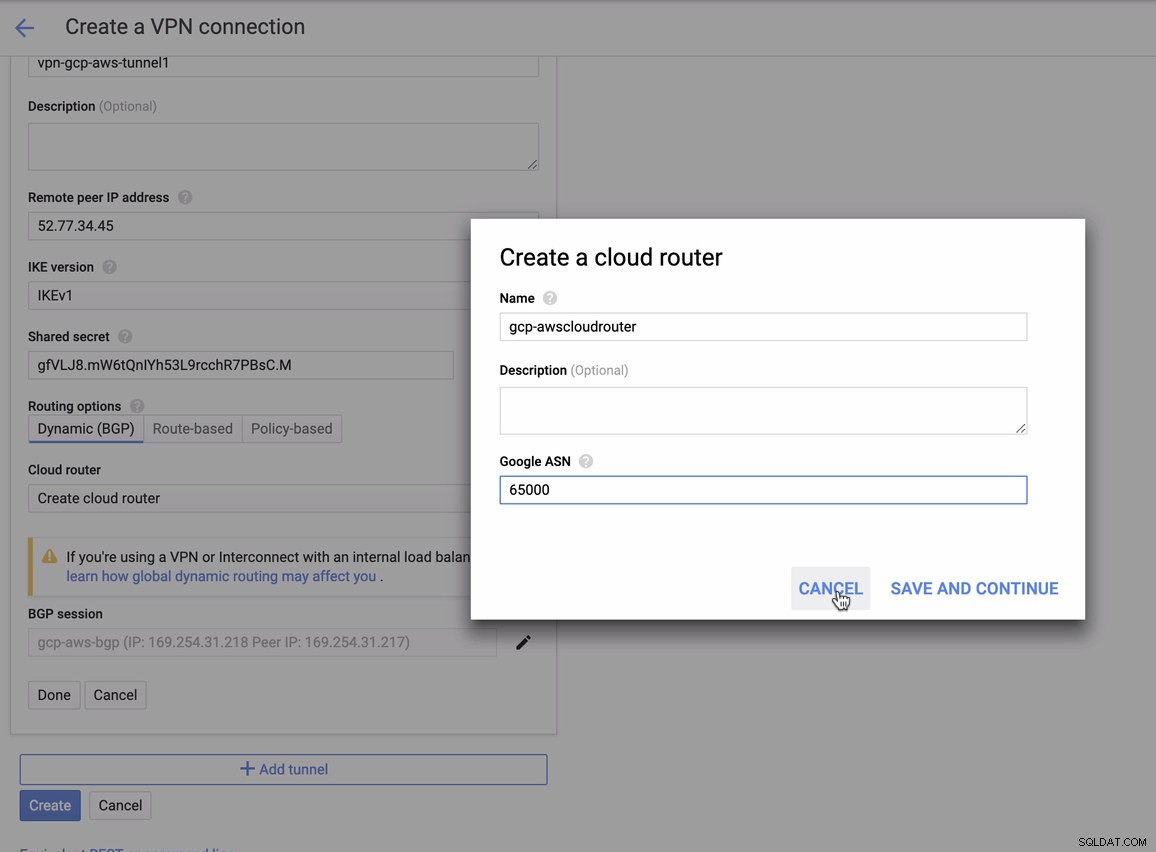
Então sessão BGP como,

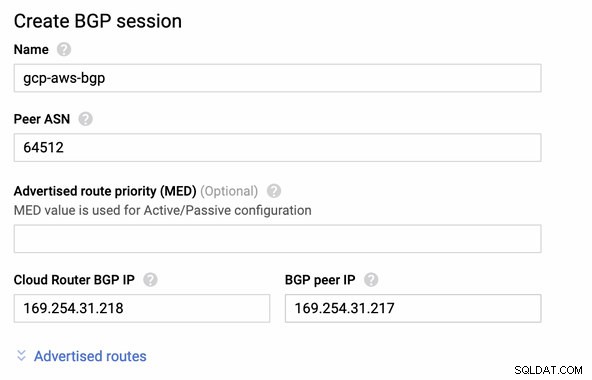
Observação: O arquivo de configuração baixado contém o túnel de configuração IPSec para o qual a AWS também contém dois (2) servidores VPN prontos para sua conexão. Você deve ter que configurar ambos para que você tenha uma configuração alta disponível. Após a configuração correta para ambos os túneis, a conexão AWS VPN na guia Tunnels mostrará que ambos Outside IP Address estão de pé. Veja imagem abaixo:

-
Por fim, como criamos um Gateway de Internet e um Gateway NAT, preencha as sub-redes públicas e privadas corretamente com Destino correto e Destino conforme observado na captura de tela das etapas anteriores. Isso pode ser configurado acessando Serviços -> Rede e entrega de conteúdo -> VPC -> Tabelas de rotas e selecione as tabelas de rotas criadas mencionadas nas etapas anteriores. Veja a imagem abaixo:
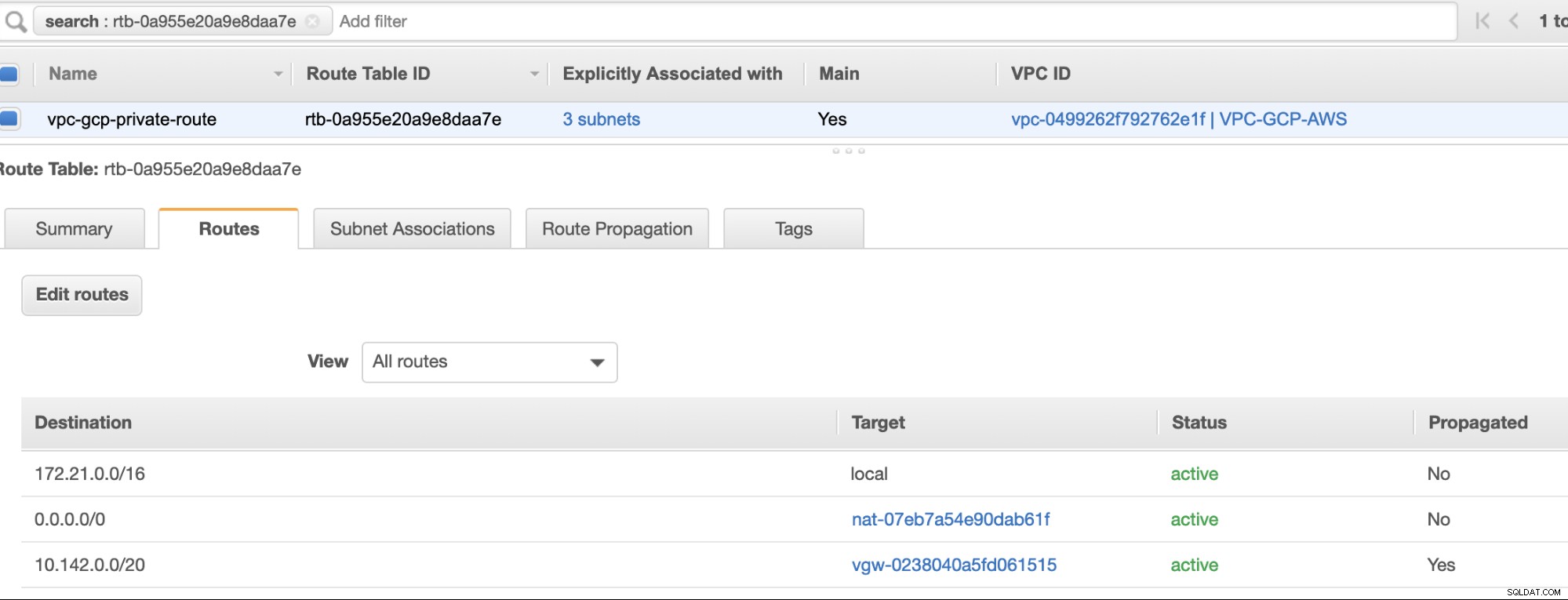
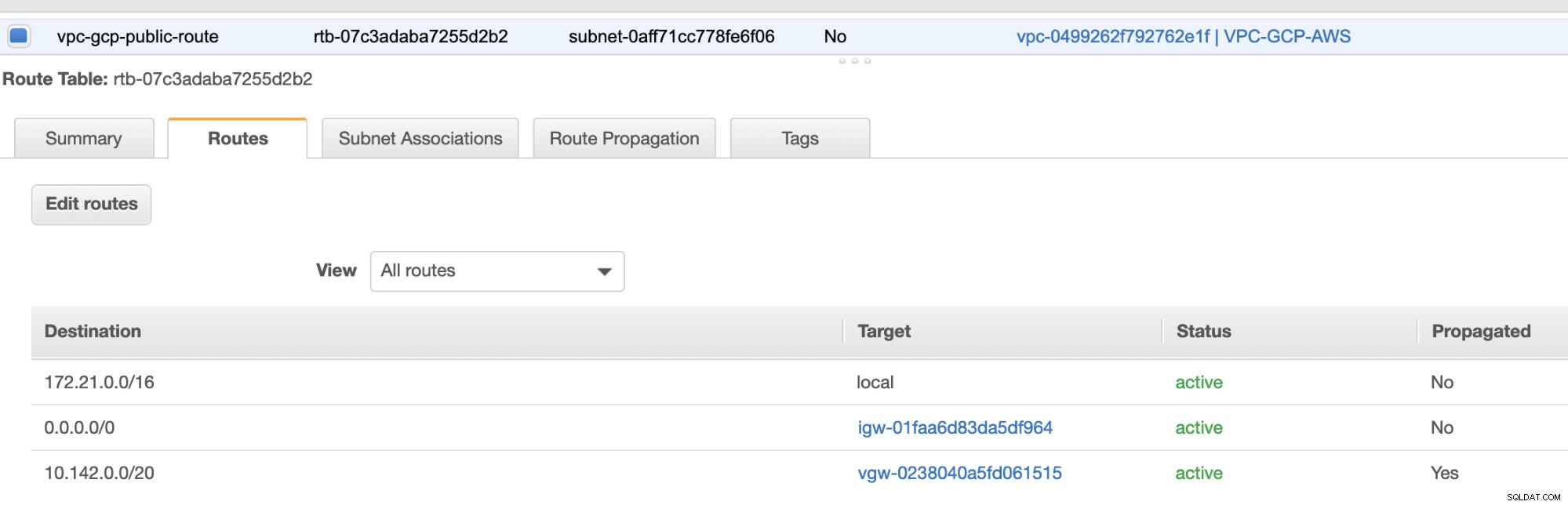
Como você notou, o igw-01faa6d83da5df964 é o Gateway de Internet que criamos e é usado pela rota pública. Enquanto isso, a tabela de rotas privada tem destino e destino definidos como nat-07eb7a54e90dab61f e ambos têm Destino definido como 0.0.0.0/0, pois permitirá diferentes conexões IPv4. Também não se esqueça de definir a Propagação da Rota corretamente para o gateway virtual, conforme visto na captura de tela que tem um destino vgw-0238040a5fd061515 . Basta clicar em Route Propagation e defini-lo como Yes, como na captura de tela abaixo:
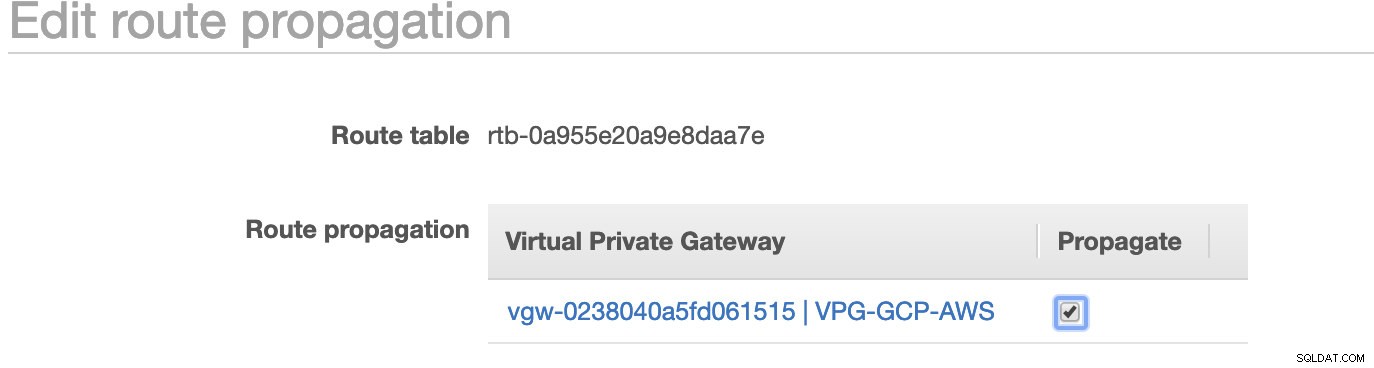
Isso é muito importante para que a conexão das conexões externas do GCP seja roteada para as tabelas de rotas na AWS e não seja necessário mais trabalho manual. Caso contrário, seu GCP não poderá estabelecer conexão com a AWS.
Agora que nossa VPN está ativa, continuaremos configurando nossos nós privados, incluindo o bastion host.
Como configurar os nós do Compute Engine
A configuração dos nós do Compute Engine/EC2 será rápida e fácil, já que toda a configuração está pronta. Não entrarei em detalhes, mas confira as capturas de tela abaixo, pois explica a configuração.
Nós do AWS EC2 :

Nós de computação do GCP :
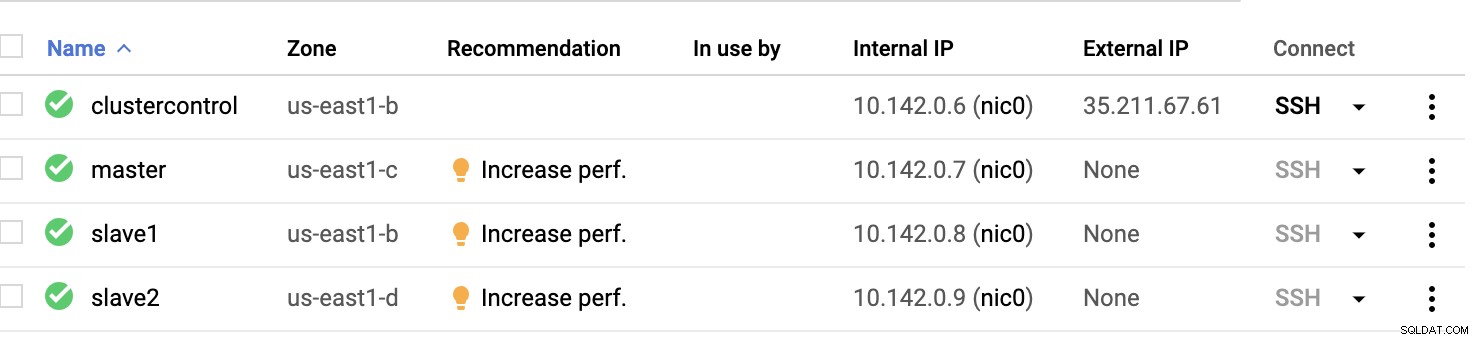
Basicamente, nesta configuração. O host clustercontrol será o Bastion ou Jump Host e para o qual o ClusterControl será instalado. Obviamente, todos os nós aqui não são acessíveis pela Internet. Eles não têm IPv4 externo atribuído e os nós estão se comunicando por meio de um canal muito seguro usando VPN.
Por fim, todos esses nós da AWS ao GCP são configurados com um usuário de sistema uniforme com acesso sudo, necessário em nossa próxima seção. Veja como o ClusterControl pode facilitar sua vida em multicloud e multirregião.
Controle de cluster ao resgate!!!
Manipular vários nós e em diferentes plataformas de nuvem pública, além de uma "Região" diferente, pode ser uma tarefa "realmente dolorosa e assustadora". Como você monitora isso de forma eficaz? ClusterControl atua não apenas como seu canivete suíço, mas também como seu DBA virtual. Agora, vamos ver como o ClusterControl pode facilitar sua vida.
Criando um cluster de múltiplas replicações usando o ClusterControl
Agora vamos tentar criar um cluster de replicação mestre-escravo MariaDB seguindo a topologia "Múltipla Replicação".
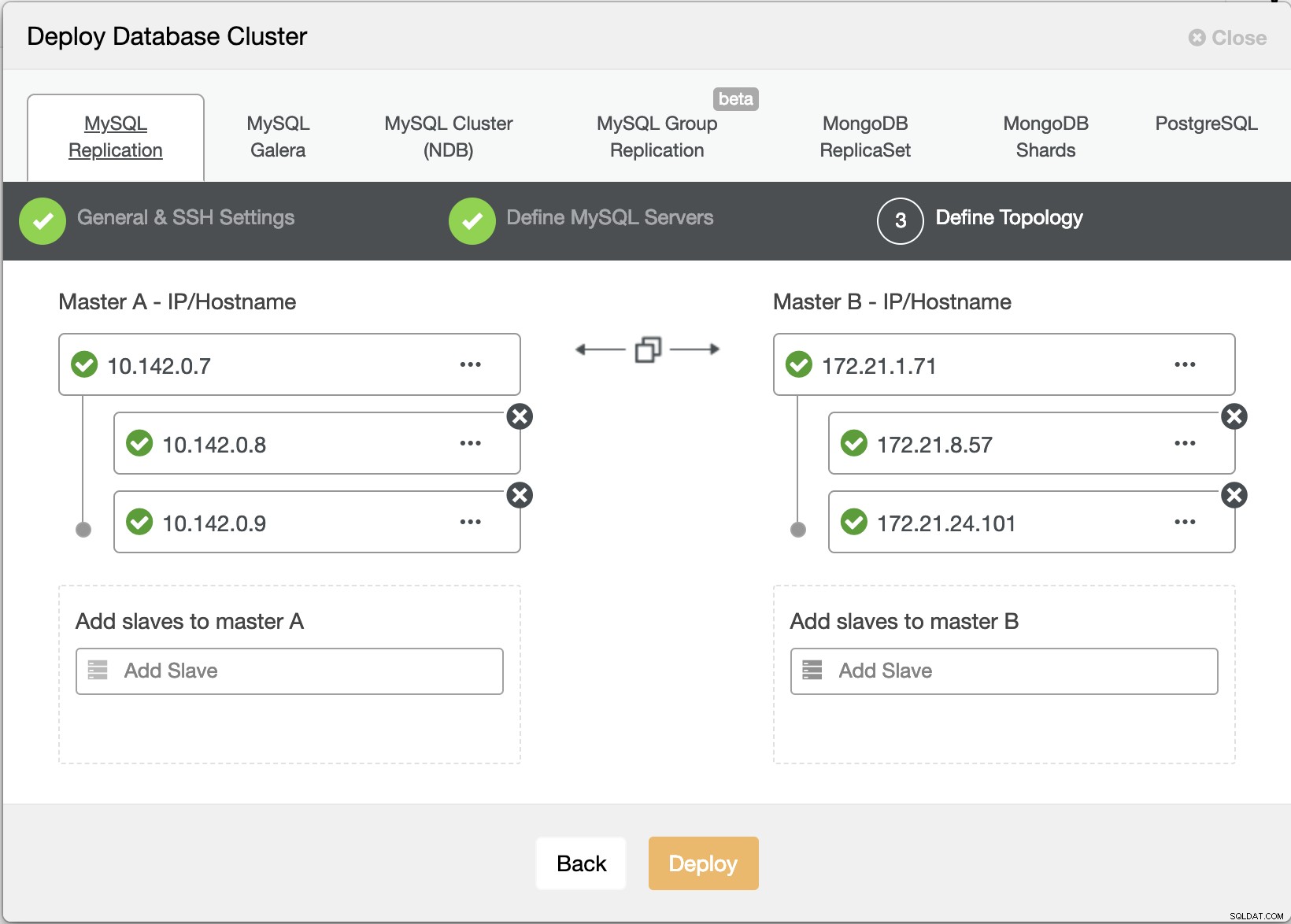 Assistente de implantação do ClusterControl
Assistente de implantação do ClusterControl Atingindo Implantar botão irá instalar pacotes e configurar os nós de acordo. Assim, uma visão lógica de como a topologia ficaria:
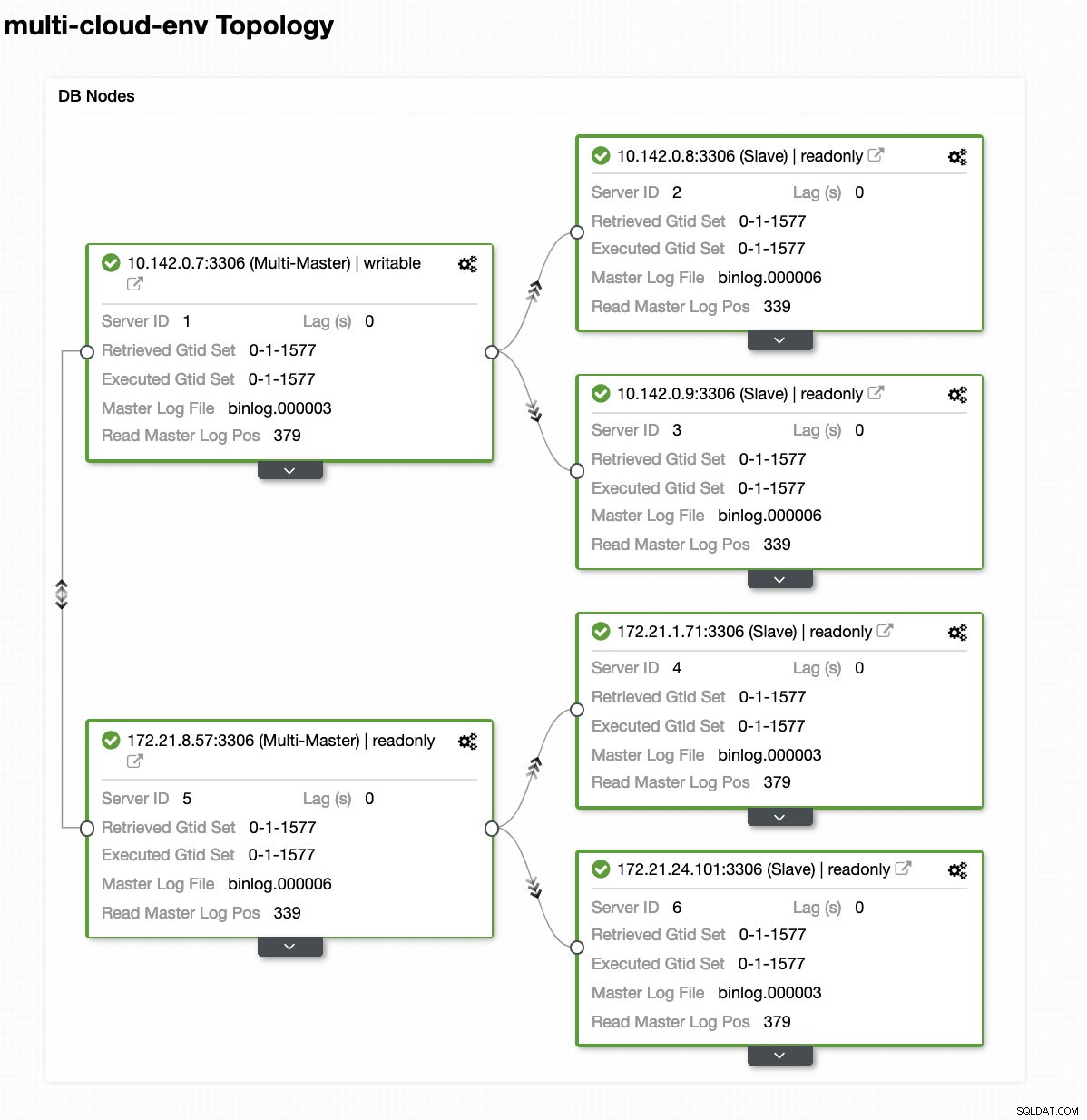
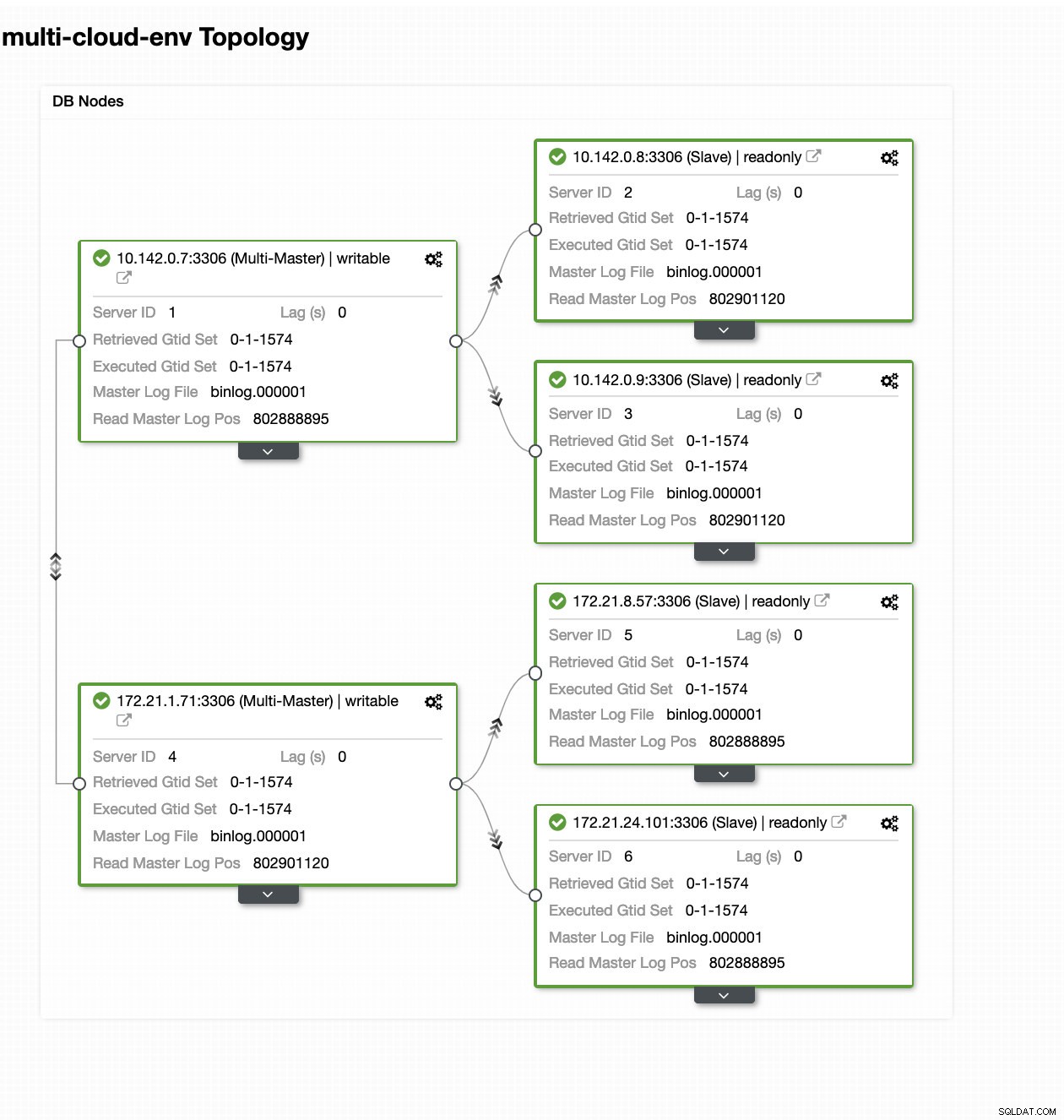 ClusterControl - Visualização de topologia
ClusterControl - Visualização de topologia Os IPs do intervalo 172.21.0.0/16 dos nós estão replicando de seu mestre em execução no GCP.
Agora, que tal tentarmos carregar algumas gravações no mestre? Quaisquer problemas com conectividade ou latência podem gerar atraso de escravo, você poderá detectar isso com o ClusterControl. Veja a imagem abaixo:
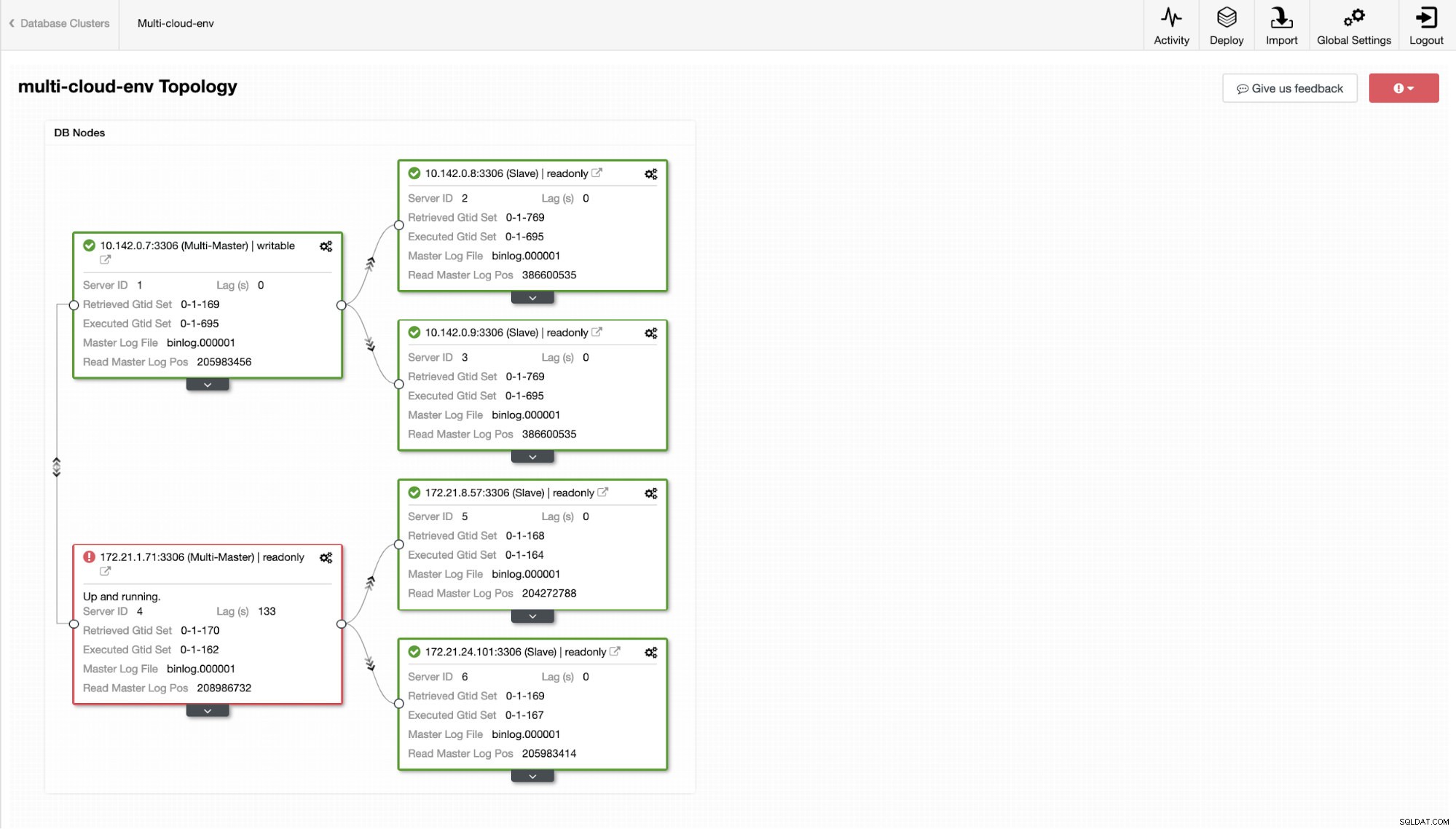
e, como você vê no canto superior direito da captura de tela, fica vermelho, pois indica que problemas foram detectados. Portanto, um alarme estava sendo enviado enquanto esse problema foi detectado. Ver abaixo:
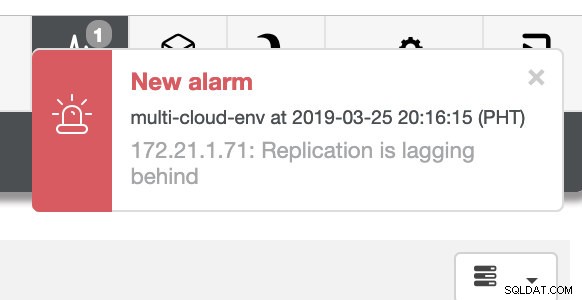
Precisamos cavar nisso. Para monitoramento de baixa granularidade, habilitamos agentes nas instâncias de banco de dados. Vamos dar uma olhada no Painel.
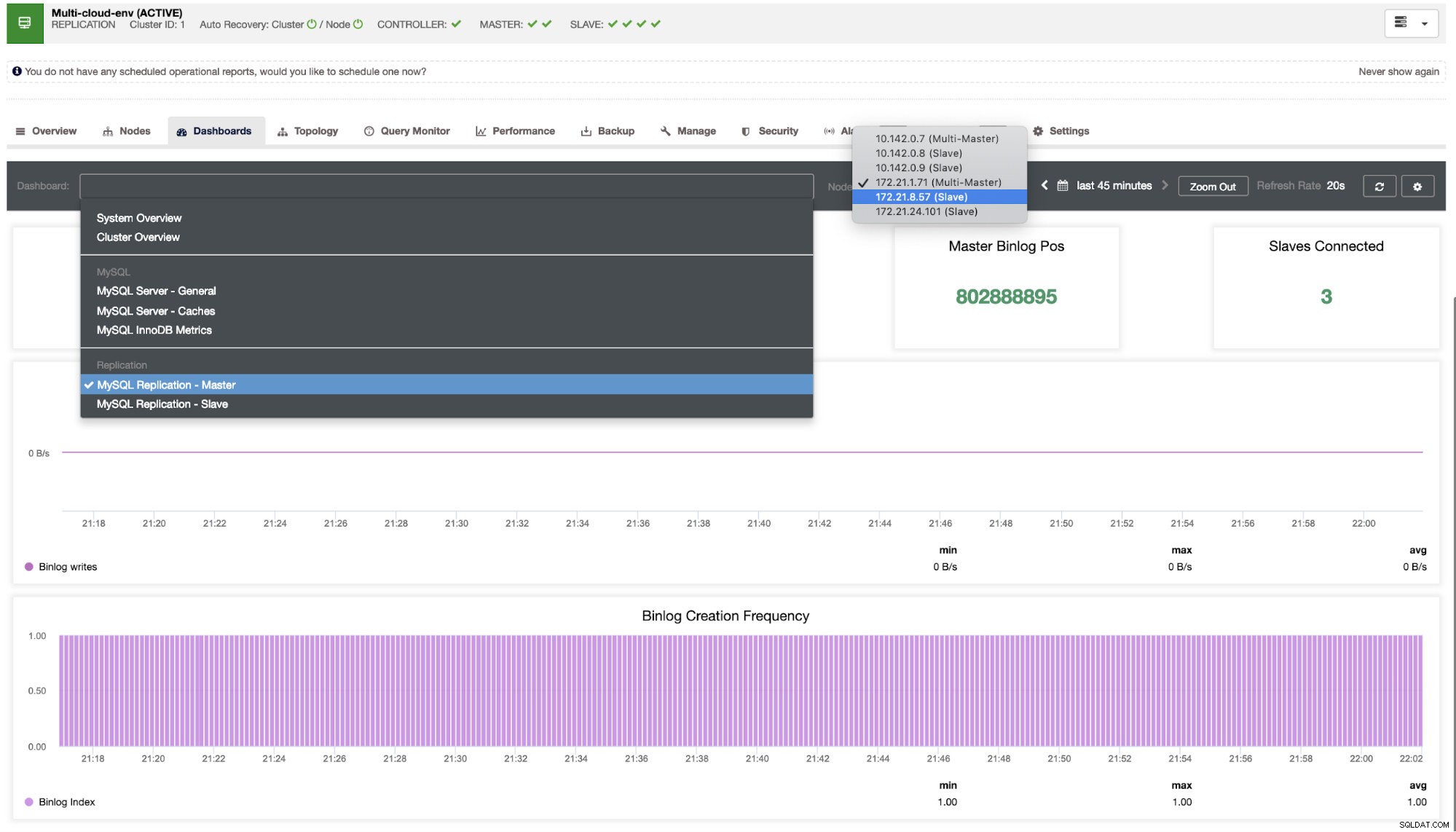
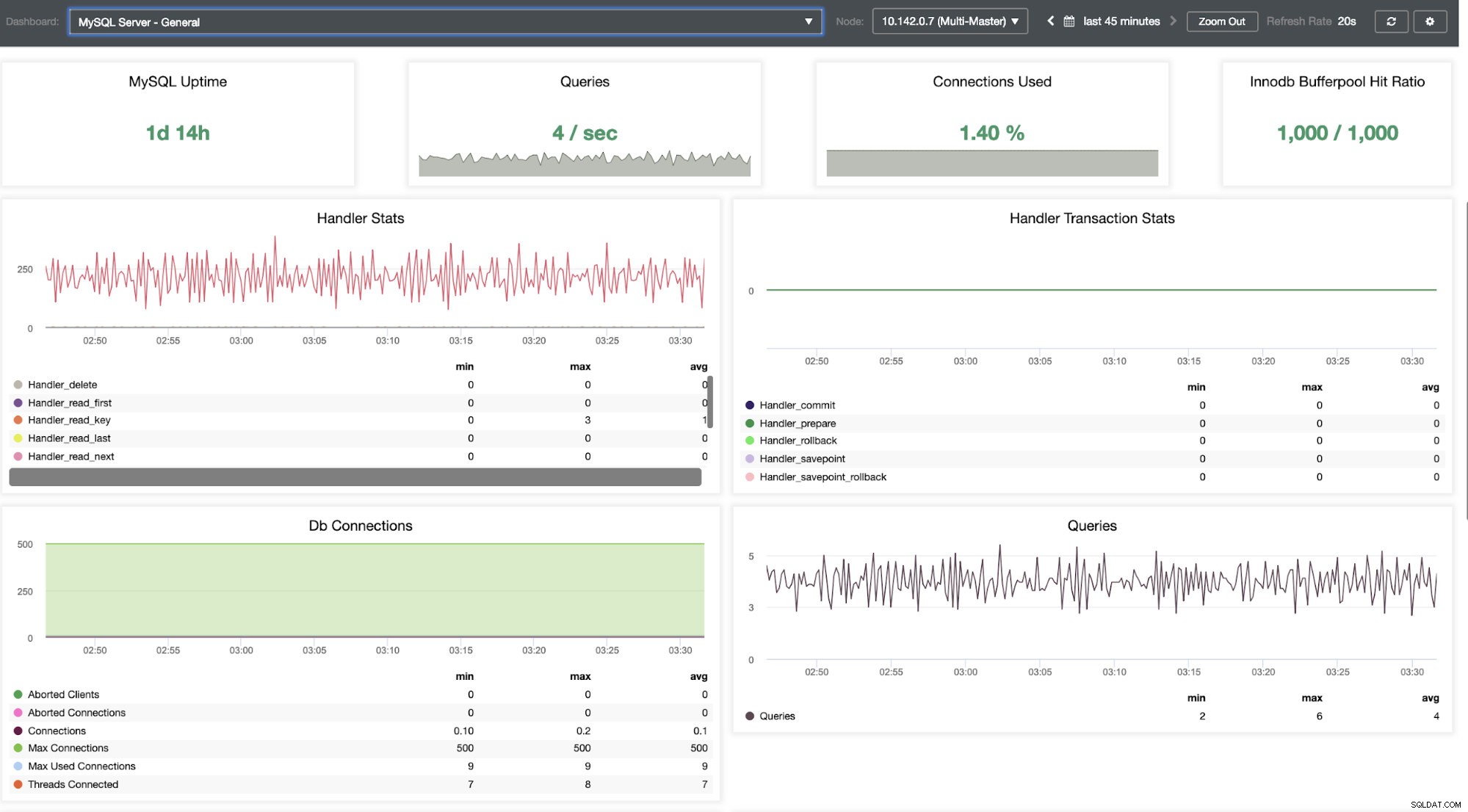
Ele oferece uma experiência super suave em termos de monitoramento de seus nós.
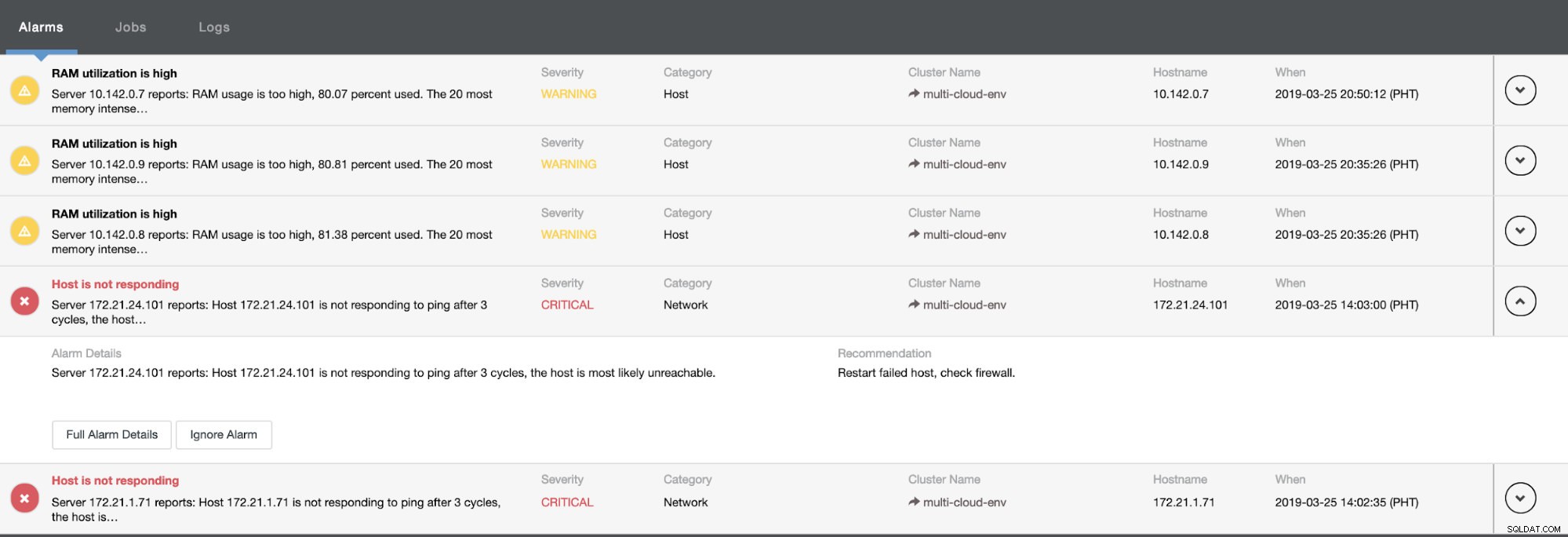
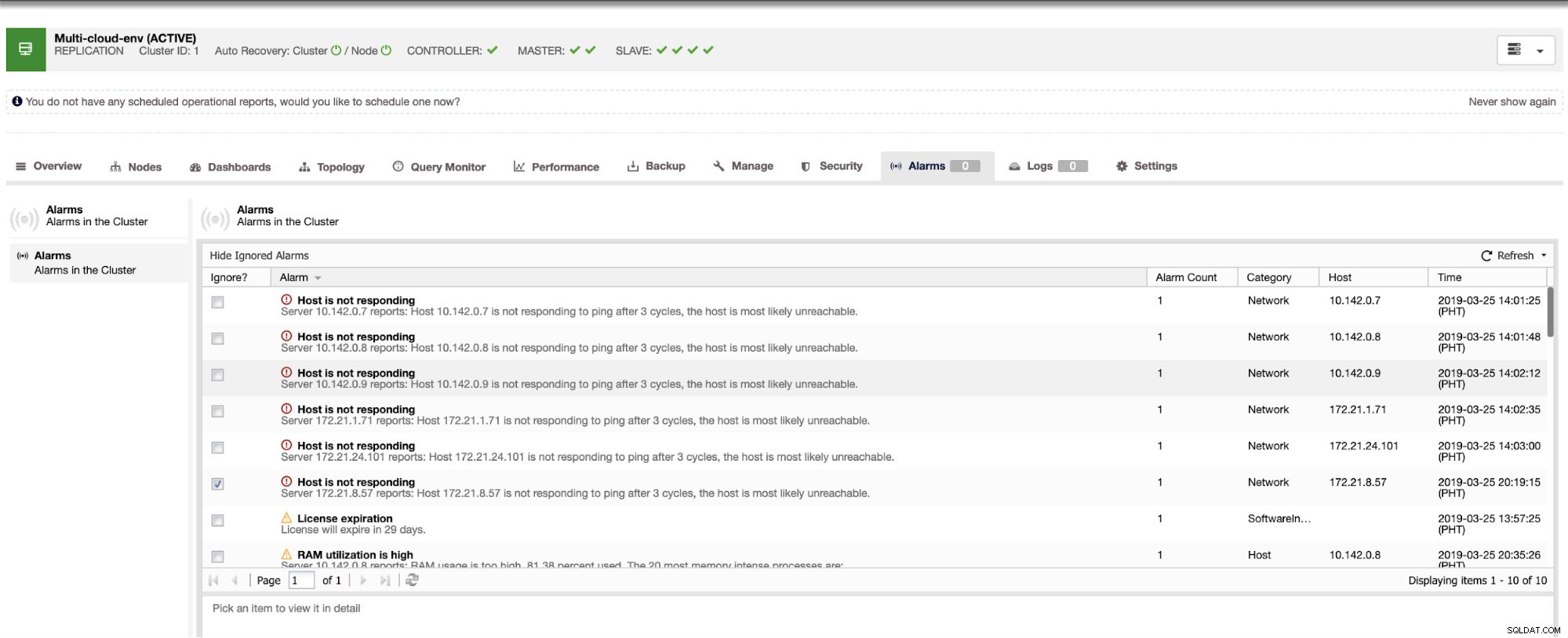
Ele nos diz que a utilização é alta ou o host não está respondendo. Embora isso tenha sido apenas um ping falha de resposta, você pode ignorar o alerta para impedir que você o bombardeie. Portanto, você pode 'des-ignorá-lo' se necessário indo para Cluster -> Alarms no Clustercontrol. Ver abaixo:
Gerenciando falhas e realizando failover
Digamos que o nó mestre us-east1 falhou ou exija uma grande revisão por causa da atualização do sistema ou do hardware. Digamos que esta seja a topologia agora (veja a imagem abaixo):
Vamos tentar desligar o host 10.142.0.7 que é o mestre na região us-east1. Veja as capturas de tela abaixo como o ClusterControl reage a isso:
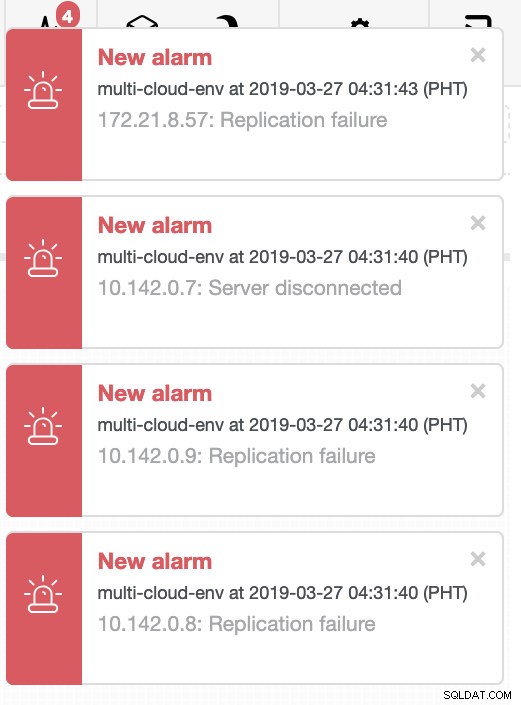
O ClusterControl envia alarmes assim que detecta anomalias no cluster. Em seguida, ele tenta fazer um failover para um novo mestre escolhendo o candidato certo (veja a imagem abaixo):

Em seguida, ele separou o mestre com falha que já foi retirado do cluster (veja a imagem abaixo):
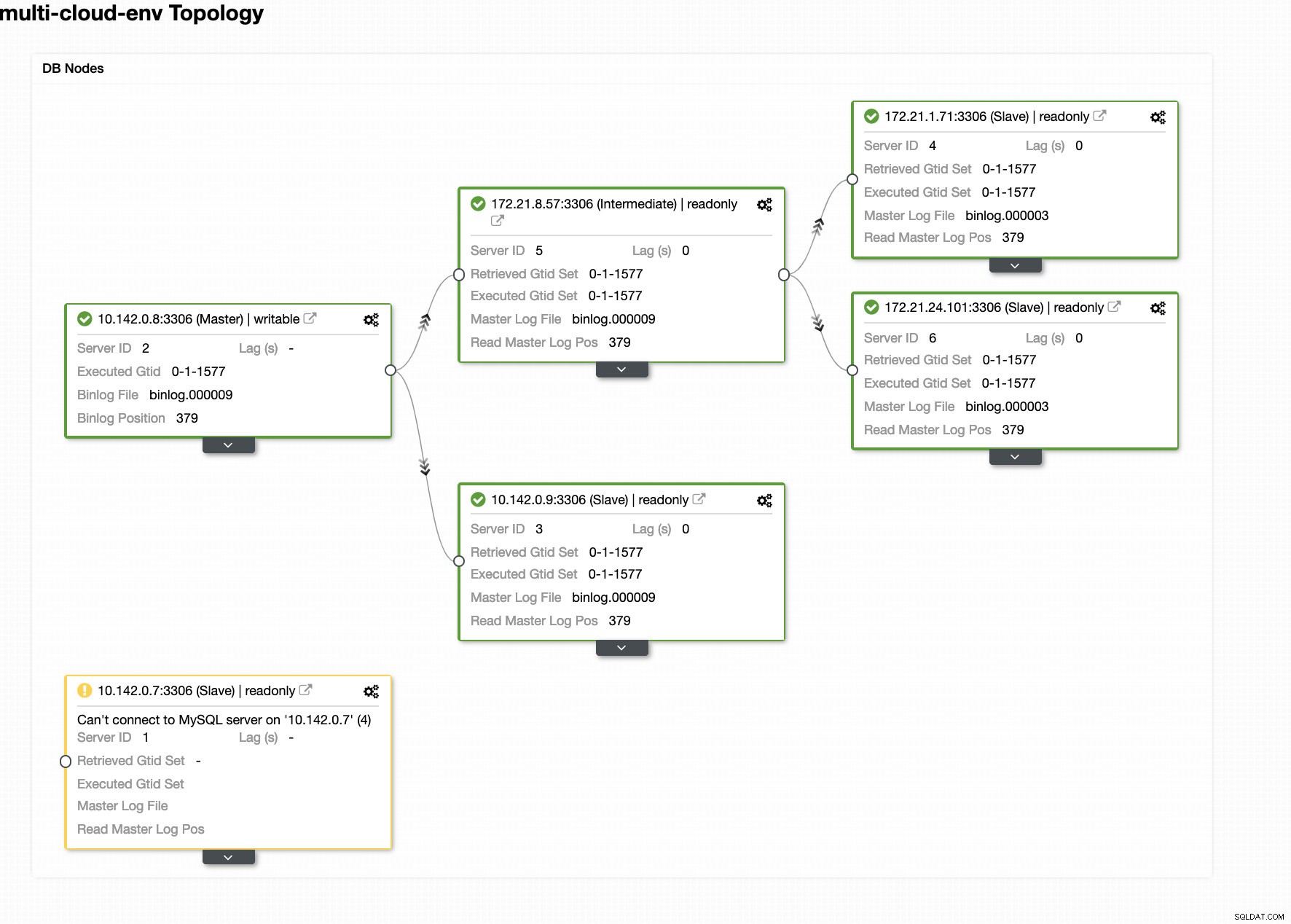
Este é apenas um vislumbre do que o ClusterControl pode fazer, existem outros ótimos recursos, como backups, monitoramento de consultas, implantação/gerenciamento de balanceadores de carga e muito mais!
Conclusão
Gerenciar sua configuração de replicação MySQL em uma multicloud pode ser complicado. Muito cuidado deve ser tomado para proteger nossa configuração, então esperamos que este blog dê uma ideia sobre como definir sub-redes e proteger os nós do banco de dados. Após a segurança, há uma série de coisas para gerenciar e é aí que o ClusterControl pode ser muito útil.
Experimente agora e deixe-nos saber como foi. Você pode entrar em contato conosco aqui a qualquer momento.