O RDS é um banco de dados como serviço (DBaaS) que configura e mantém automaticamente seus bancos de dados na nuvem AWS. O usuário tem poder limitado sobre configurações específicas em comparação com a execução do MySQL diretamente no Elastic Compute Cloud (EC2). Mas o RDS é um serviço conveniente, desde que você possa conviver com as instâncias e configurações que ele oferece.
Atualmente, o Amazon RDS oferece suporte a várias versões do MySQL e MariaDB, bem como ao mecanismo de banco de dados Amazon Aurora compatível com MySQL. Ele suporta replicação, mas como você pode esperar de um console web predefinido, existem algumas limitações.
 Amazon RDS Services
Amazon RDS Services Existem algumas compensações ao usar o RDS. Isso pode afetar não apenas a maneira como você gerencia e provisiona suas instâncias de banco de dados, mas também aspectos importantes, como desempenho, segurança e alta disponibilidade.
Neste blog, veremos as diferenças entre usar o RDS e executar o MySQL no EC2, com foco na replicação. Como veremos, decidir entre hospedar o MySQL em uma instância do EC2 ou usar o Amazon RDS não é uma tarefa fácil.
Compensações da plataforma RDS
O maior tamanho de banco de dados que a AWS pode hospedar depende do ambiente de origem, da alocação de dados no banco de dados de origem e da ocupação do sistema.
 Opções do ambiente Amazon RDS
Opções do ambiente Amazon RDS  Classe de instância do Amazon RDS
Classe de instância do Amazon RDS A AWS é dividida em regiões. Cada conta da AWS tem limites, por região, no número de recursos da AWS que podem ser criados. Depois que um limite para um recurso for atingido, as chamadas adicionais para criar esse recurso falharão.
 Regiões da AWS
Regiões da AWS Para instâncias de banco de dados MySQL do Amazon RDS, o limite máximo de armazenamento provisionado restringe o tamanho de uma tabela a um tamanho máximo de 6 TB ao usar espaços de tabela de arquivo por tabela do InnoDB.
O recurso de arquivo por tabela do InnoDB é algo que você deve considerar, mesmo que não esteja procurando migrar um grande banco de dados para a nuvem. Você pode notar que algumas instâncias de banco de dados existentes têm um limite inferior. Por exemplo, instâncias de banco de dados MySQL criadas antes de abril de 2014 têm um limite de tamanho de arquivo e tabela de 2 TB. Esse limite de tamanho de arquivo de 2 TB também se aplica a instâncias de banco de dados ou réplicas de leitura criadas a partir de snapshots de banco de dados obtidos antes de abril de 2014.
Uma das principais diferenças que afeta a maneira como você configura e mantém a replicação de banco de dados é a falta de usuário SUPER. Para resolver essa limitação, a Amazon introduziu procedimentos armazenados que cuidam de várias tarefas do DBA. Abaixo estão os principais procedimentos para gerenciar a replicação do MySQL RDS.
Erro de replicação de salto:
CALL mysql.rds_skip_repl_error;Parar a replicação:
CALL mysql.rds_stop_replication;Iniciar replicação
CALL mysql.rds_start_replication;Configura uma instância RDS como uma réplica de leitura de uma instância MySQL executada fora da AWS.
CALL mysql.rds_set_external_master;Reconfigura uma instância MySQL para não ser mais uma réplica de leitura de uma instância MySQL executada fora da AWS.
CALL mysql.rds_reset_external_master;Importa um certificado. Isso é necessário para habilitar a comunicação SSL e a replicação criptografada.
CALL mysql.rds_import_binlog_ssl_material;Remove um certificado.
CALL mysql.rds_remove_binlog_ssl_material;Altera a posição do log mestre de replicação para o início do próximo log binário no mestre.
CALL mysql.rds_next_master_log;Embora os procedimentos armazenados cuidem de várias tarefas, é uma curva de aprendizado. A falta de privilégio SUPER também pode criar problemas no uso do monitoramento de replicação externa.
Atualmente, o Amazon RDS não oferece suporte ao seguinte:
- IDs de transações globais
- Espaço de tabela transportável
- Plugin de autenticação
- Plugin de força de senha
- Filtros de replicação
- Replicação semi-síncrona
Por último, mas não menos importante - acesso ao shell. O Amazon RDS não permite acesso direto ao host a uma instância de banco de dados via Telnet, Secure Shell (SSH) ou Windows Remote Desktop Connection (RDP). Você ainda pode usar o cliente em um host de aplicativo para se conectar ao banco de dados por meio de ferramentas padrão, como o cliente mysql.
Existem outras limitações, conforme descrito na documentação do RDS.
Alta disponibilidade com MySQL no EC2
Para automatizar tarefas de implantação e gerenciamento/manutenção (mantendo o controle), é possível usar o ClusterControl. Assim como no RDS, você tem a conveniência de implantar uma configuração de banco de dados em poucos minutos por meio de uma GUI. Adicionar nós, agendar backups, executar failovers e assim por diante também pode ser feito convenientemente por meio da GUI. Existem opções para operar o MySQL diretamente no EC2 e, assim, manter o controle das opções de alta disponibilidade. Ao seguir esse caminho, é importante entender como aproveitar os diferentes recursos da AWS que estão à sua disposição. Certifique-se de verificar nosso white paper 'DIY Cloud Database'.
Implantação
O ClusterControl pode automatizar a implantação de diferentes configurações de banco de dados de alta disponibilidade - de replicação mestre-escravo a clusters multimestres. Todos os principais tipos de MySQL são suportados - Oracle MySQL, MariaDB e Percona Server. É necessária alguma configuração inicial de VPC/grupo de segurança, e isso está bem descrito no whitepaper DIY Cloud Database. Observe que conceitos semelhantes se aplicam, seja AWS, Google Cloud ou Azure
 ClusterControl Deploy in EC2
ClusterControl Deploy in EC2 O Galera Cluster é uma boa alternativa a ser considerada ao implantar um serviço MySQL de alta disponibilidade. Ele se estabeleceu como um substituto confiável para as arquiteturas mestre-escravo tradicionais do MySQL, embora não seja um substituto imediato. A maioria dos aplicativos ainda pode ser adaptada para rodar nele. É possível definir segmentos diferentes para bancos de dados que abrangem várias regiões da AWS.
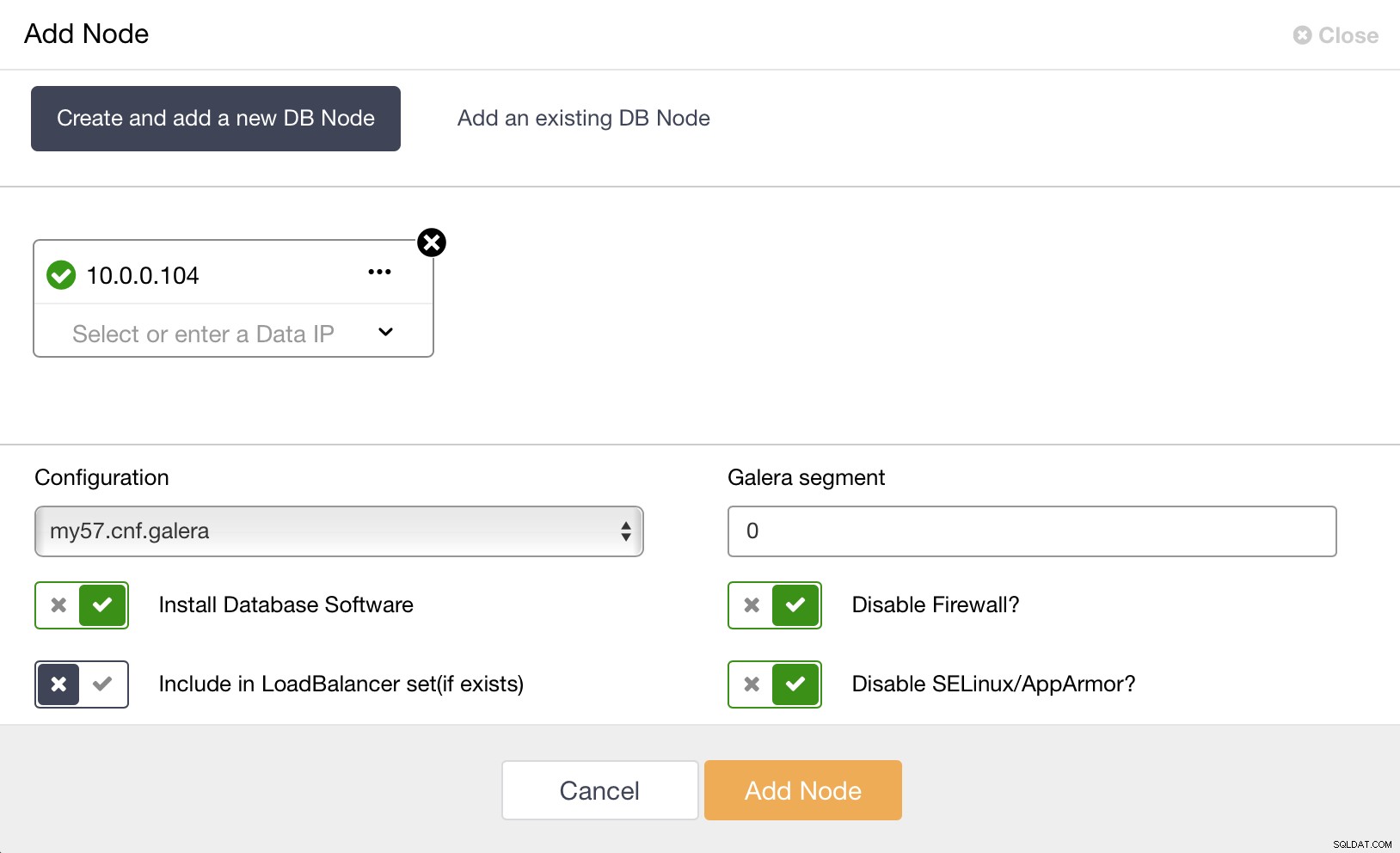 ClusterControl expandir cluster no EC2
ClusterControl expandir cluster no EC2 É possível configurar a 'replicação híbrida' combinando a replicação síncrona dentro de um Galera Cluster e a replicação assíncrona entre o cluster e um ou mais escravos. Opções como atrasar o escravo dão um nível adicional de proteção aos dados.
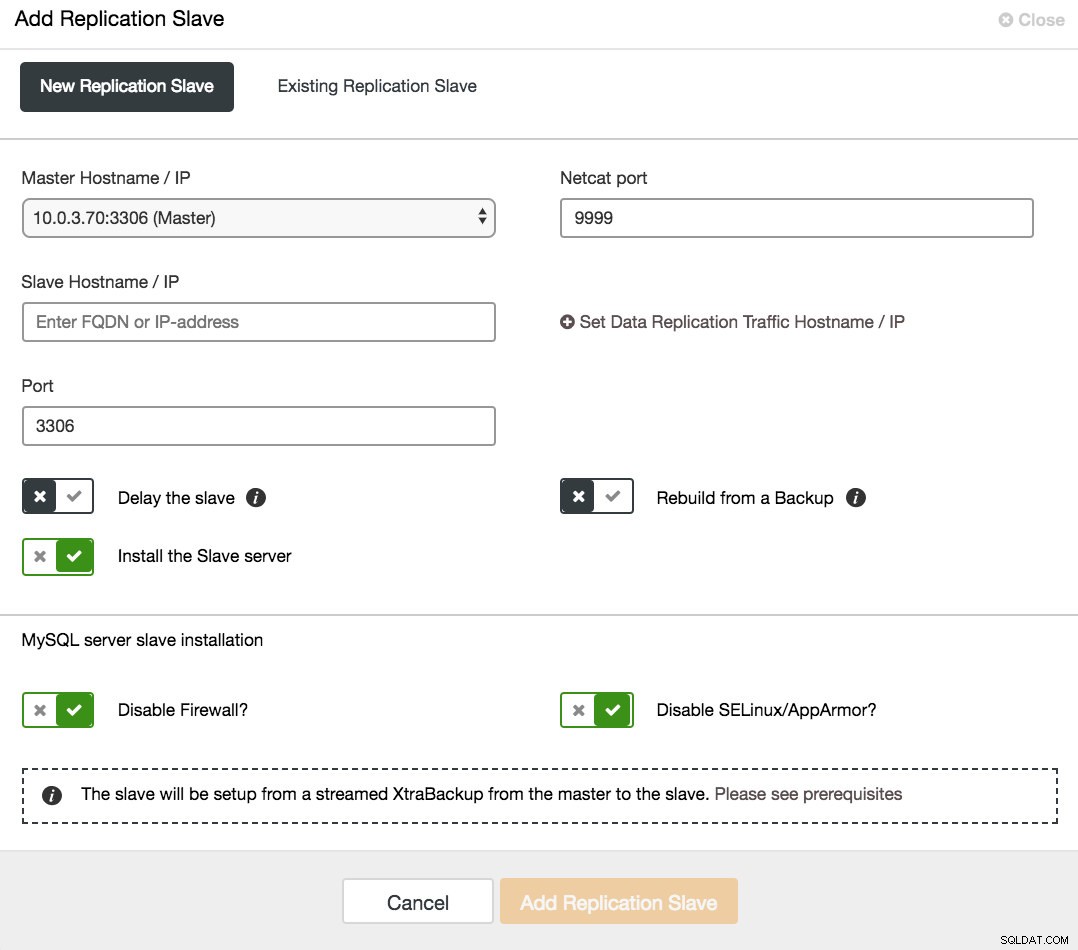 ClusterControl Adicionar replicação no EC2
ClusterControl Adicionar replicação no EC2 Camada proxy
Para obter alta disponibilidade, a implantação de uma configuração altamente disponível não é suficiente. Os aplicativos precisam saber de alguma forma quais nós estão funcionando e quais não estão. Mudanças na topologia, e. mover um mestre para outro host, também precisa ser propagado de alguma forma para evitar erros na camada de aplicação. O ClusterControl oferece suporte a implantações de proxies como HAProxy, MaxScale e ProxySQL. Para HAProxy e ProxySQL, há opções adicionais para implantar instâncias redundantes com Keepalived e VirtualIP.
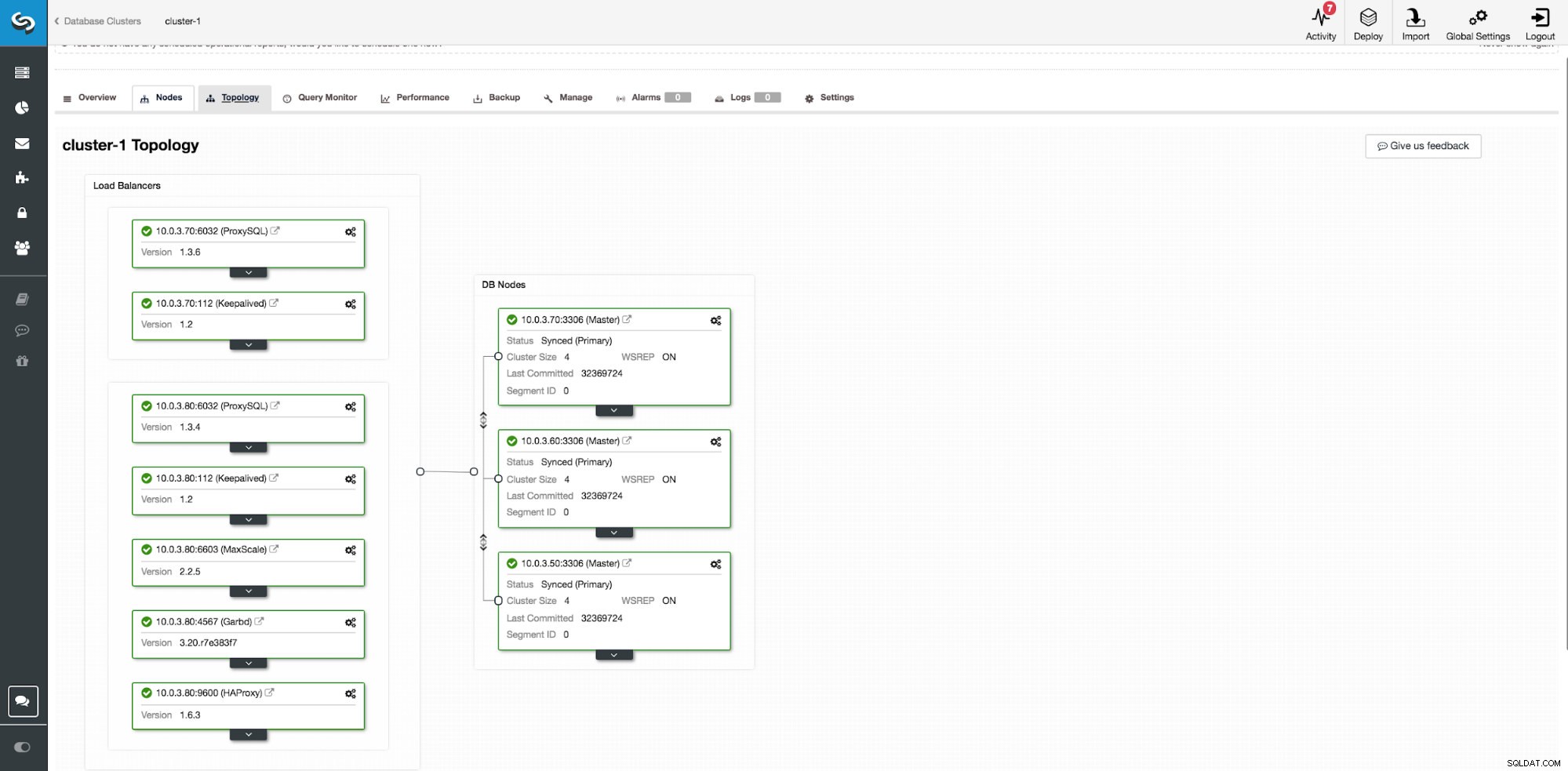 Gerenciador de balanceadores de carga do ClusterControl em nós do EC2
Gerenciador de balanceadores de carga do ClusterControl em nós do EC2 Réplica entre regiões
O Amazon RDS fornece serviços de réplica de leitura. As réplicas entre regiões oferecem a capacidade de dimensionar leituras, pois a AWS tem seus serviços em vários datacenters em todo o mundo. Todas as réplicas de leitura são acessíveis e podem ser usadas para leitura em um número máximo de cinco regiões. Esses nós são independentes e podem ser usados em seu caminho de upgrade ou podem ser promovidos para bancos de dados independentes.
Além disso, a Amazon oferece implantações Multi-AZ baseadas em DRBD, replicação de disco síncrona. Qual é a diferença das réplicas de leitura? A principal diferença é que apenas o mecanismo de banco de dados na instância primária está ativo, o que leva a outras variações de arquitetura.
Ao contrário das réplicas de leitura, as atualizações de versão do mecanismo de banco de dados ocorrem no primário. Outra diferença é que o AWS RDS fará failover automaticamente com DRBD, enquanto as réplicas de leitura (usando replicação assíncrona) exigirão operações manuais de você.
O failover Multi-AZ no RDS usa uma alteração de DNS para apontar para a instância em espera, de acordo com a Amazon, isso deve acontecer dentro de 60 a 120 segundos durante o failover. Como o standby usa os mesmos dados de armazenamento que o primário, provavelmente haverá recuperação de transação/log. Bancos de dados maiores podem gastar uma quantidade significativa de tempo na recuperação do InnoDB, portanto, considere isso em seu plano de DR e cálculo de RTO.
Claro, isso vai com custo adicional. Vejamos alguns exemplos básicos. O custo do host db.t2.medium com 2vCPU, 4 GB de ram é 185,98 USD por mês, o preço dobrará quando você habilitar a réplica Multizone (MZ) para 370,98 UDB. O preço varia de acordo com a região, mas dobrará em MZ.
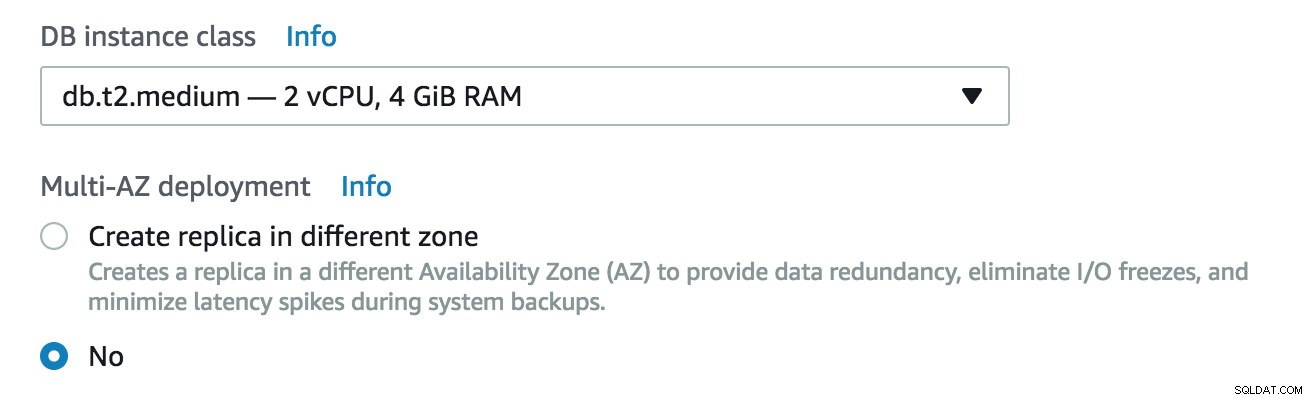
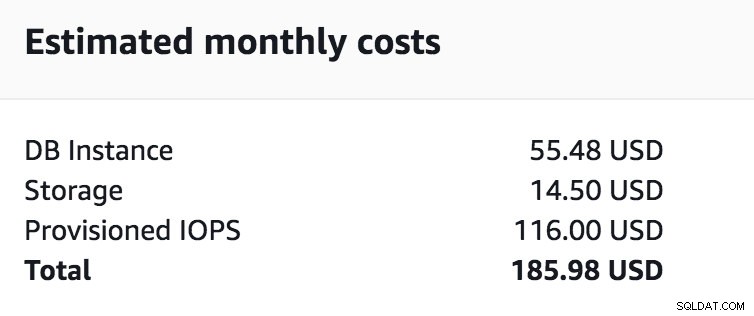
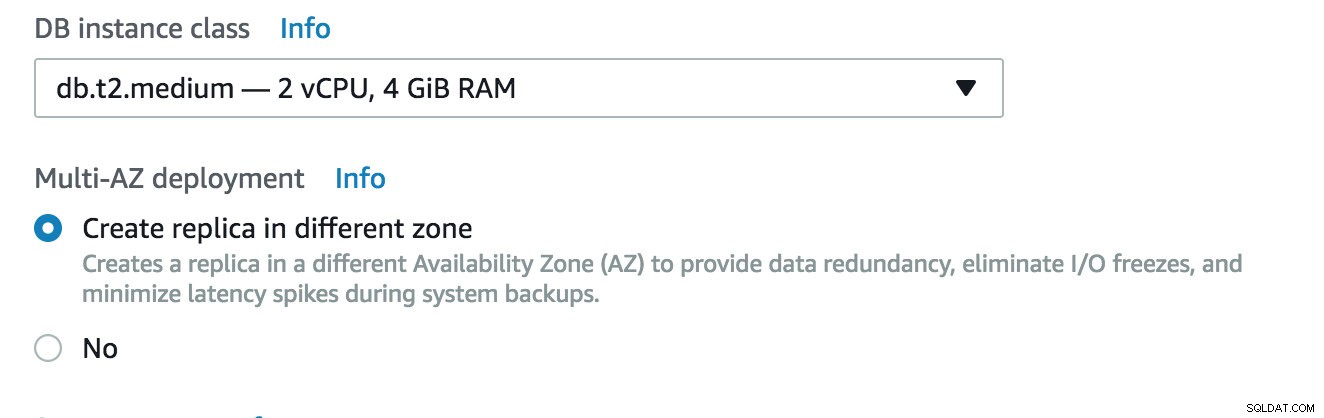
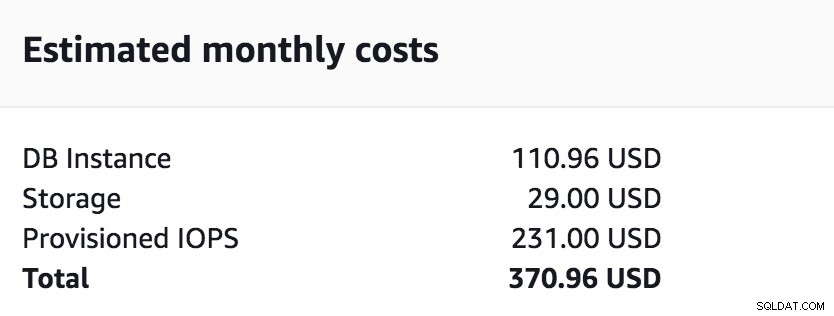 Comparação de custos
Comparação de custos Para obter o mesmo com o EC2, você pode implantar suas máquinas virtuais em diferentes regiões. Cada região da AWS é completamente independente. A configuração da região da AWS pode ser alterada no console, definindo a variável de ambiente EC2_REGION, ou pode ser substituída usando o parâmetro --region com a AWS Command Line Interface. Quando seu conjunto de servidores estiver pronto, você poderá usar o ClusterControl para implantar e monitorar sua replicação. Você também pode configurar manualmente a replicação por meio do console usando comandos padrão.
Replicação de tecnologia cruzada
É possível configurar a replicação entre uma instância de banco de dados MySQL ou MariaDB do Amazon RDS e uma instância MySQL ou MariaDB externa ao Amazon RDS. Isso é feito usando o método de replicação padrão no mysql, por meio de logs binários. Para habilitar logs binários, você precisa modificar a configuração my.cnf. Sem acesso ao shell, essa tarefa se tornou impossível no RDS. É feito de uma forma não tão óbvia. Você tem duas opções. Uma é habilitar backups - defina backups automatizados em sua instância de banco de dados do Amazon RDS com retenção superior a 0. Ou habilite a replicação para um servidor escravo pré-compilado. Ambas as tarefas habilitarão logs binários que você poderá usar posteriormente para sua replicação.
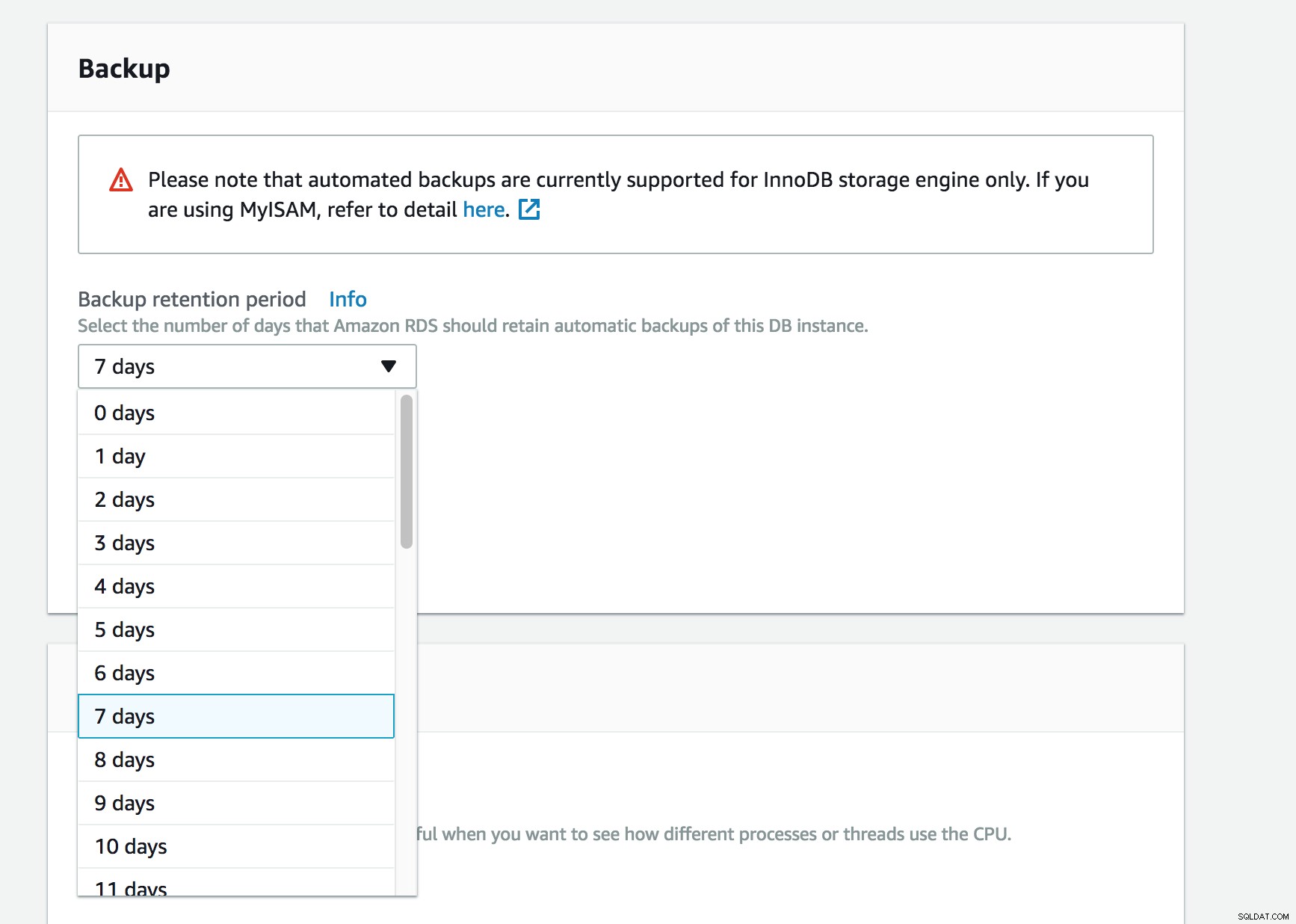 Ativar logs binários via backup RDS
Ativar logs binários via backup RDS Mantenha os logs binários em sua instância mestre até verificar se eles foram aplicados na réplica. Essa manutenção garante que você possa restaurar sua instância mestre em caso de falha.
Outro roadblock pode ser permissões. As permissões necessárias para iniciar a replicação em uma instância de banco de dados do Amazon RDS são restritas e não estão disponíveis para o usuário mestre do Amazon RDS. Por isso, você deve usar os comandos mysql.rds_set_external_master e mysql.rds_start_replication do Amazon RDS para configurar a replicação entre o banco de dados ativo e o banco de dados do Amazon RDS.
Monitore eventos de failover para a instância do Amazon RDS que é sua réplica. Se ocorrer um failover, a instância de banco de dados que é sua réplica poderá ser recriada em um novo host com um endereço de rede diferente. Para obter informações sobre como monitorar eventos de failover, consulte Usar a notificação de eventos do Amazon RDS.
No exemplo abaixo, veremos como habilitar a replicação do RDS para um banco de dados externo localizado em uma instância do EC2.
Você deve ter os logs binários habilitados, usamos um escravo RDS aqui.
Especifique o número de horas para reter logs binários.
mysql -h RDS_MASTER -u<username> -u<password>
call mysql.rds_set_configuration('binlog retention hours', 7);No RDS MASTER, crie o usuário de replicação com os seguintes comandos:
CREATE USER 'repl'@'ec2DBslave' IDENTIFIED BY 's3cr3tp4SSw0rd';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'ec2DBslave';No RDS SLAVE, execute os comandos:
mysql -u<username> -u<password> -h RDS_SLAVE
call mysql.rds_stop_replication;
SHOW SLAVE STATUS; Exec_Master_Log_Pos, Relay_Master_Log_File.No RDS SLAVE, execute mysqldump com o seguinte formato:
mysqldump -u<username> -u<password> -h RDS_SLAVE --routines --triggers --single-transaction --databases DB1 DB2 DB3 > mysqldump.sqlImporte o dump do banco de dados para o banco de dados externo:
mysql -u<username> -u<password> -h ec2DBslave
tee import_database.log;
source mysqldump.sql;CHANGE MASTER TO
MASTER_HOST='RDS_MASTER',
MASTER_USER='repl',
MASTER_PASSWORD='s3cr3tp4SSw0rd',
MASTER_LOG_FILE='<Relay_Master_Log_File>',
MASTER_LOG_POS=<Exec_Master_Log_Pos>;Crie um filtro de replicação para ignorar tabelas criadas pela AWS apenas no RDS
CHANGE REPLICATION FILTER REPLICATE_WILD_IGNORE_TABLE = ('mysql.rds\_%');Iniciar replicação
START SLAVE;Verifique o status da replicação
SHOW SLAVE STATUS;É isso por enquanto. Gerenciar o MySQL na AWS é um grande tópico. Deixe-nos saber seus pensamentos na seção de comentários abaixo.