No Stack Overflow, temos algumas tabelas usando índices columnstore clusterizados e funcionam muito bem para a maior parte de nossa carga de trabalho. Mas recentemente nos deparamos com uma situação em que “tempestades perfeitas” – vários processos, todos tentando excluir do mesmo CCI – sobrecarregariam a CPU, pois todos eram amplamente paralelos e lutavam para concluir sua operação. Veja como era no SolarWinds SQL Sentry:
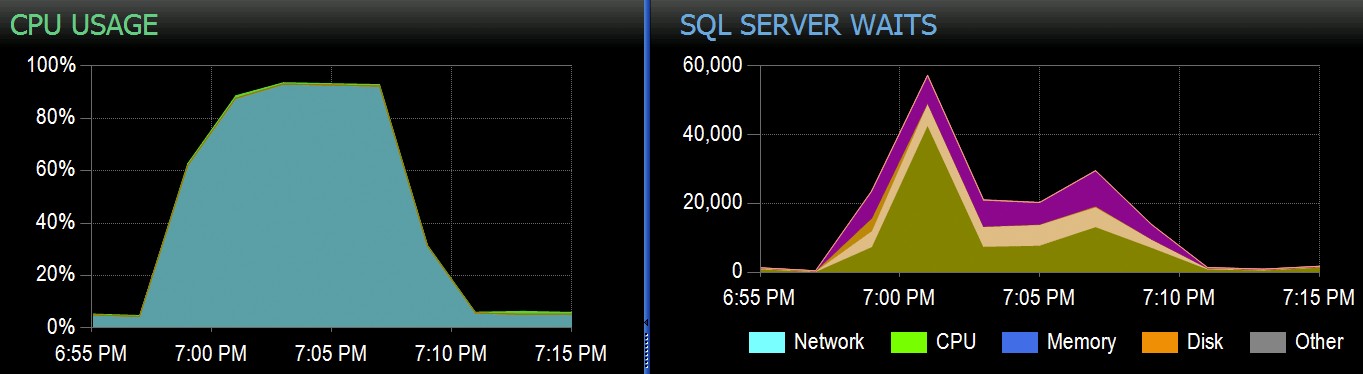
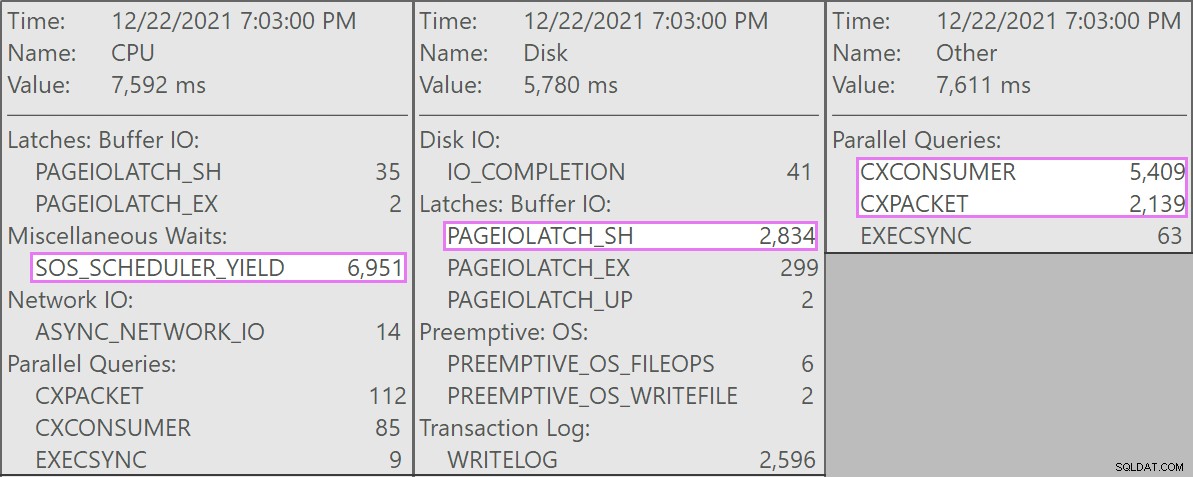
E aqui estão as esperas interessantes associadas a essas consultas:
As consultas concorrentes eram todas desta forma:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
O plano ficou assim:

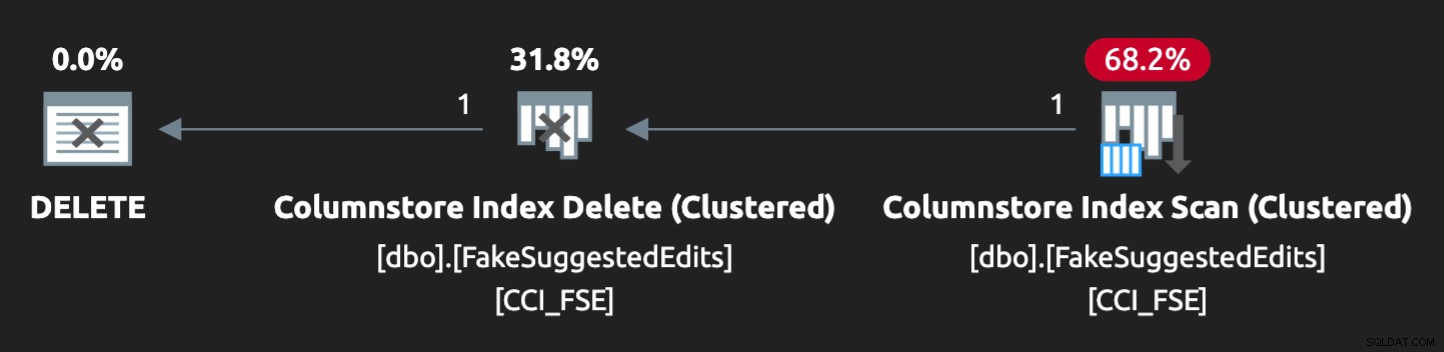
E o aviso na varredura nos avisou sobre algumas E/S residuais bastante extremas:

A tabela tem 1,9 bilhão de linhas, mas tem apenas 32 GB (obrigado, armazenamento colunar!). Ainda assim, essas exclusões de linha única levariam de 10 a 15 segundos cada, com a maior parte desse tempo sendo gasto em
SOS_SCHEDULER_YIELD . Felizmente, como nesse cenário a operação de exclusão pode ser assíncrona, conseguimos resolver o problema com duas alterações (embora eu esteja simplificando muito aqui):
- Limitamos
MAXDOPno nível do banco de dados para que essas exclusões não sejam tão paralelas - Melhoramos a serialização dos processos vindos do aplicativo (basicamente, enfileiramos exclusões por meio de um único dispatcher)
Como um DBA, podemos controlar facilmente
MAXDOP , a menos que seja substituído no nível da consulta (outra toca de coelho para outro dia). Não podemos necessariamente controlar o aplicativo nessa medida, especialmente se for distribuído ou não nosso. Como podemos serializar as gravações nesse caso sem alterar drasticamente a lógica do aplicativo? Uma configuração simulada
Não vou tentar criar uma tabela de dois bilhões de linhas localmente - não importa a tabela exata - mas podemos aproximar algo em uma escala menor e tentar reproduzir o mesmo problema.
Vamos fingir que este é o
SuggestedEdits mesa (na realidade, não é). Mas é um exemplo fácil de usar porque podemos extrair o esquema do Stack Exchange Data Explorer. Usando isso como base, podemos criar uma tabela equivalente (com algumas pequenas alterações para facilitar o preenchimento) e lançar um índice columnstore clusterizado nela:CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Para preenchê-lo com 100 milhões de linhas, podemos fazer a junção cruzada de
sys.all_objects e sys.all_columns cinco vezes (no meu sistema, isso produzirá 2,68 milhões de linhas de cada vez, mas YMMV):-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
Então, podemos verificar o espaço:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
São apenas 1,3 GB, mas isso deve ser suficiente:

Imitando nossa exclusão de armazenamento de colunas em cluster
Aqui está uma consulta simples que corresponde aproximadamente ao que nosso aplicativo estava fazendo com a tabela:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
O plano não é uma combinação perfeita, no entanto:
Para que ele fosse paralelo e produzisse uma contenção semelhante em meu laptop escasso, tive que coagir um pouco o otimizador com esta dica:
OPTION (QUERYTRACEON 8649);
Agora, parece certo:

Reproduzindo o problema
Em seguida, podemos criar uma onda de atividade de exclusão simultânea usando SqlStressCmd para excluir 1.000 linhas aleatórias usando 16 e 32 threads:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
Podemos observar a tensão que isso coloca na CPU:
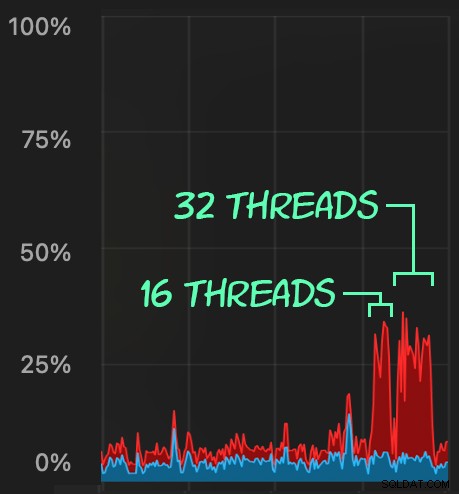
A tensão na CPU dura ao longo dos lotes de cerca de 64 e 130 segundos, respectivamente:
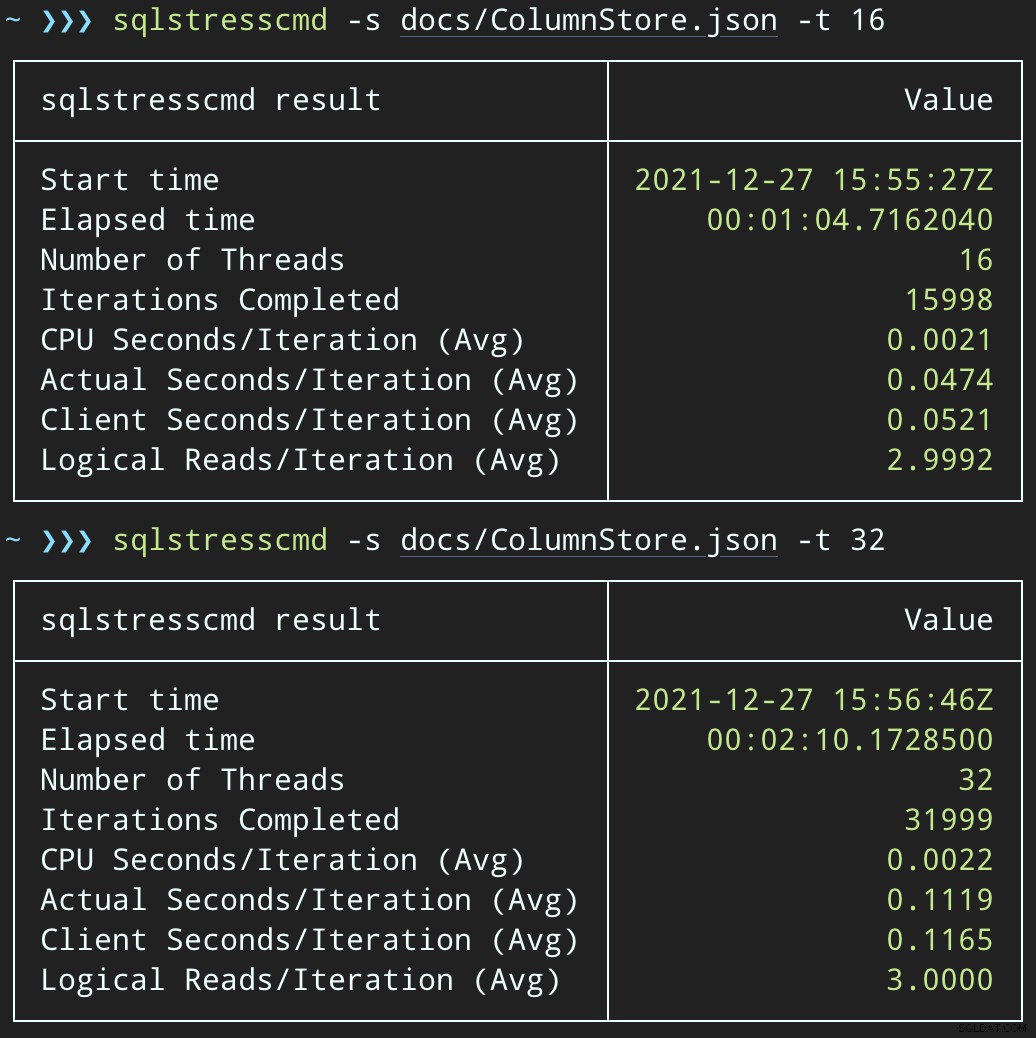
Observação:a saída do SQLQueryStress às vezes está um pouco errada nas iterações, mas confirmei que o trabalho que você solicita é feito com precisão.
Uma possível solução alternativa:uma fila de exclusão
Inicialmente, pensei em introduzir uma tabela de filas no banco de dados, que poderíamos usar para descarregar a atividade de exclusão:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Tudo o que precisamos é de um gatilho INSTEAD OF para interceptar essas exclusões não autorizadas provenientes do aplicativo e colocá-las na fila para processamento em segundo plano. Infelizmente, você não pode criar um gatilho em uma tabela com um índice columnstore clusterizado:
Msg 35358, Level 16, State 1
CREATE TRIGGER na tabela 'dbo.FakeSuggestedEdits' falhou porque você não pode criar um gatilho em uma tabela com um índice columnstore clusterizado. Considere impor a lógica do gatilho de alguma outra maneira ou, se precisar usar um gatilho, use um índice de heap ou árvore B.
Precisaremos de uma alteração mínima no código do aplicativo, para que ele chame um procedimento armazenado para lidar com a exclusão:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
Este não é um estado permanente; isso é apenas para manter o mesmo comportamento enquanto altera apenas uma coisa no aplicativo. Depois que o aplicativo for alterado e estiver chamando esse procedimento armazenado com êxito em vez de enviar consultas de exclusão ad hoc, o procedimento armazenado poderá ser alterado:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
Testando o impacto da fila
Agora, se alterarmos SqlQueryStress para chamar o procedimento armazenado:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
E envie lotes semelhantes (colocando 16K ou 32K linhas na fila):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
O impacto da CPU é um pouco maior:
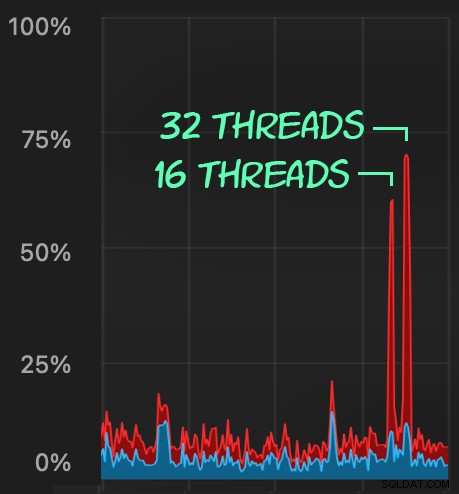
Mas as cargas de trabalho terminam muito mais rapidamente — 16 e 23 segundos, respectivamente:
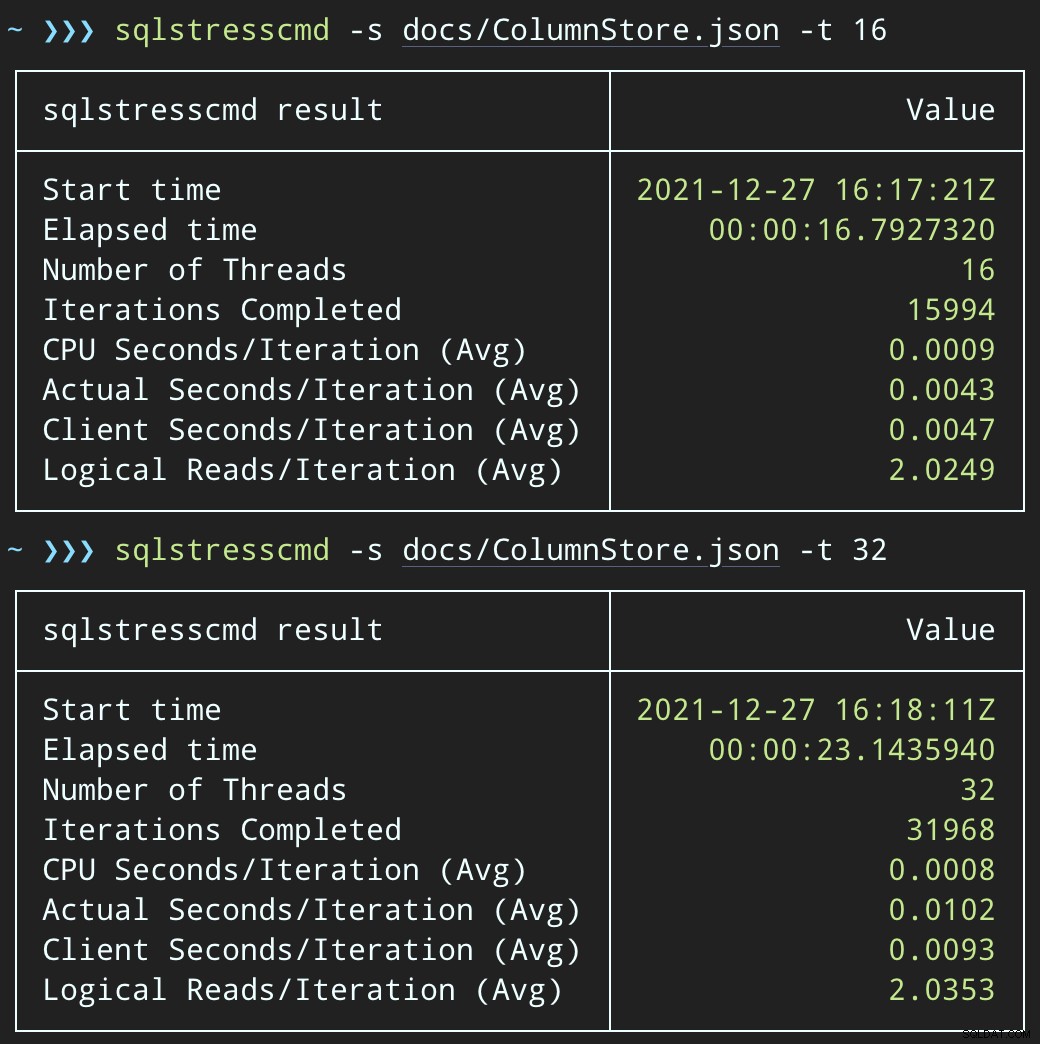
Esta é uma redução significativa na dor que os aplicativos sentirão quando entrarem em períodos de alta simultaneidade.
Ainda temos que executar a exclusão, embora
Ainda temos que processar essas exclusões em segundo plano, mas agora podemos introduzir lotes e ter controle total sobre a taxa e quaisquer atrasos que queremos injetar entre as operações. Aqui está a estrutura básica de um procedimento armazenado para processar a fila (reconhecidamente sem controle transacional totalmente adquirido, tratamento de erros ou limpeza da tabela de filas):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
END Agora, a exclusão de linhas levará mais tempo — a média de 10.000 linhas é de 223 segundos, dos quais aproximadamente 100 é um atraso intencional. Mas nenhum usuário está esperando, então quem se importa? O perfil da CPU é quase zero, e o aplicativo pode continuar adicionando itens na fila tão simultâneos quanto desejar, com quase zero conflito com o trabalho em segundo plano. Ao processar 10.000 linhas, adicionei outras 16 mil linhas à fila e usei a mesma CPU de antes — levando apenas um segundo a mais do que quando o trabalho não estava em execução:
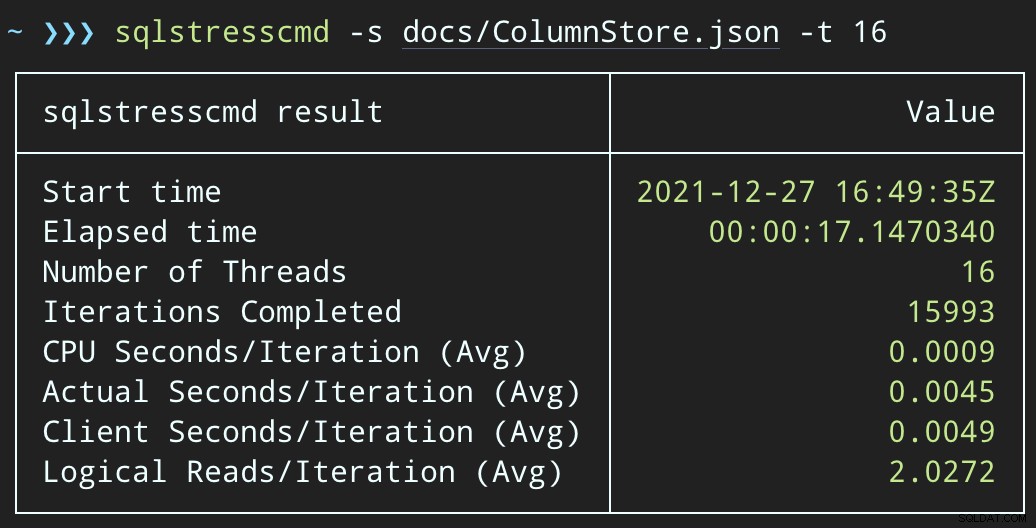
E o plano agora se parece com isso, com linhas estimadas/reais muito melhores:
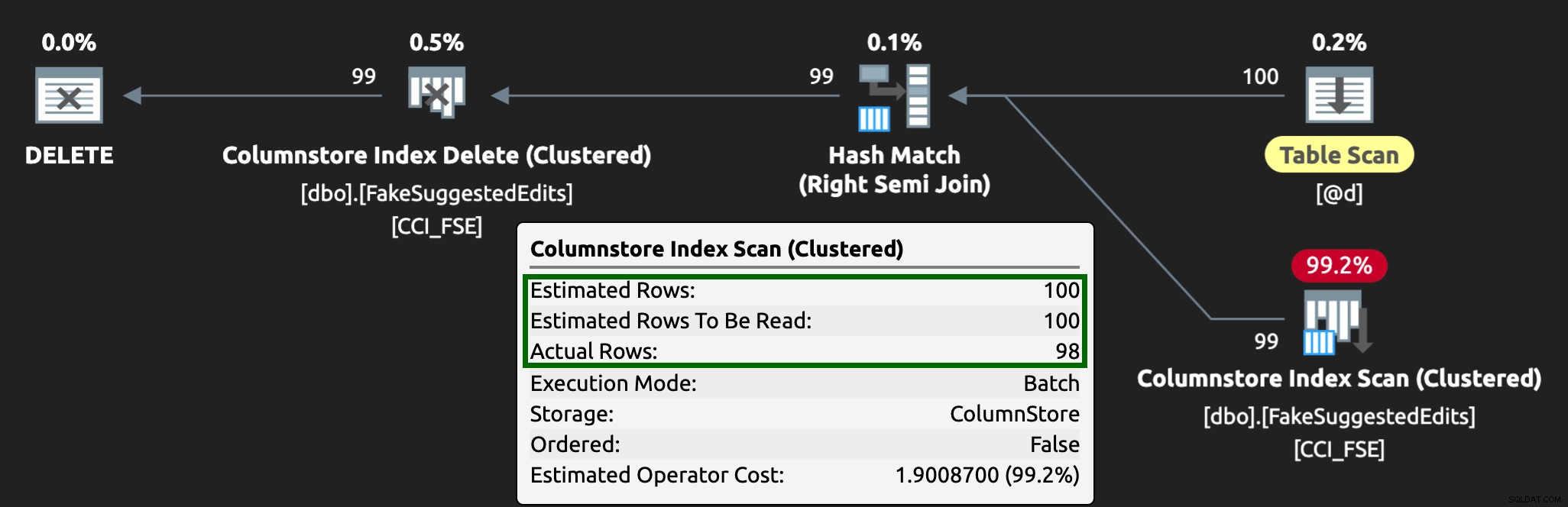
Eu posso ver essa abordagem de tabela de filas sendo uma maneira eficaz de lidar com alta simultaneidade de DML, mas requer pelo menos um pouco de flexibilidade com os aplicativos que enviam DML - essa é uma razão pela qual eu realmente gosto que os aplicativos chamem procedimentos armazenados, pois eles nos dão muito mais controle mais próximo dos dados.
Outras opções
Se você não puder alterar as consultas de exclusão provenientes do aplicativo — ou, se não puder adiar as exclusões para um processo em segundo plano — considere outras opções para reduzir o impacto das exclusões:
- Um índice não clusterizado nas colunas de predicado para dar suporte a pesquisas de ponto (podemos fazer isso isoladamente sem alterar o aplicativo)
- Usar apenas exclusões reversíveis (ainda requer alterações no aplicativo)
Será interessante ver se essas opções oferecem benefícios semelhantes, mas vou guardá-las para um post futuro.