Este é o terceiro de uma série de cinco partes que se aprofunda na maneira como os planos paralelos do modo de linha do SQL Server começam a ser executados. A parte 1 inicializou o contexto de execução zero para a tarefa pai e a parte 2 criou a árvore de verificação de consulta. Agora estamos prontos para iniciar a verificação de consulta, realizar algumas fase inicial processamento e inicie as primeiras tarefas paralelas adicionais.
Inicialização da verificação da consulta
Lembre-se de que apenas a tarefa pai existe agora, e as exchanges (operadoras de paralelismo) têm apenas um lado consumidor. Ainda assim, isso é suficiente para iniciar a execução da consulta, no thread de trabalho da tarefa pai. O processador de consulta inicia a execução iniciando o processo de verificação de consulta por meio de uma chamada para
CQueryScan::StartupQuery . Um lembrete do plano (clique para ampliar):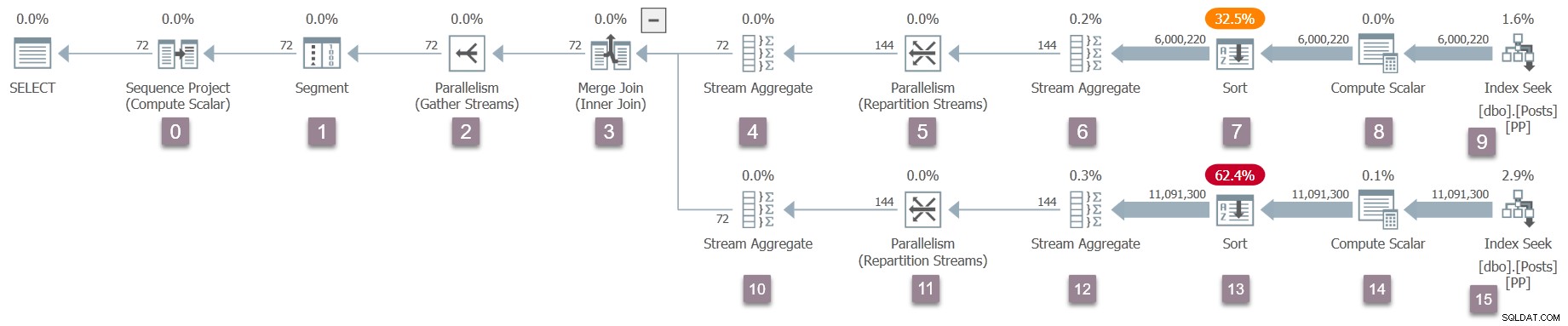
Este é o primeiro ponto no processo até agora que um plano de execução em andamento está disponível (SQL Server 2016 SP1 em diante) em
sys.dm_exec_query_statistics_xml . Não há nada particularmente interessante para ver em tal plano neste momento, porque todos os contadores de transientes são zero, mas o plano está pelo menos disponível . Não há indícios de que as tarefas paralelas ainda não tenham sido criadas ou que as exchanges não tenham um lado produtor. O plano parece “normal” em todos os aspectos. Agências do Plano Paralelo
Como este é um plano paralelo, será útil mostrá-lo dividido em ramificações. Estes estão sombreados abaixo e rotulados como ramos A a D:
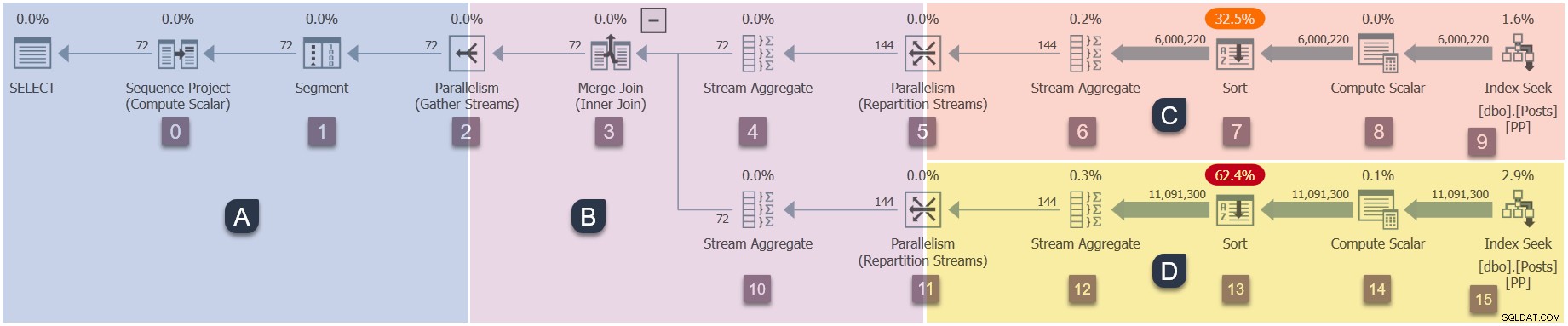
A ramificação A está associada à tarefa pai, sendo executada no encadeamento de trabalho fornecido pela sessão. Trabalhadores paralelos adicionais serão iniciados para executar as tarefas paralelas adicionais contidos nas ramificações B, C e D. Essas ramificações são paralelas, portanto, haverá tarefas e trabalhadores adicionais do DOP em cada uma.
Nossa consulta de exemplo está sendo executada no DOP 2, portanto, a ramificação B receberá duas tarefas adicionais. O mesmo vale para a ramificação C e a ramificação D, totalizando seis Tarefas adicionais. Cada tarefa será executada em seu próprio thread de trabalho em seu próprio contexto de execução.
Dois agendadores (S1 e S2 ) são atribuídos a essa consulta para executar trabalhos paralelos adicionais. Cada trabalhador adicional será executado em um desses dois agendadores. O trabalhador pai pode ser executado em um agendador diferente, portanto, nossa consulta DOP 2 pode usar no máximo três núcleos de processador a qualquer momento.
Para resumir, nosso plano acabará por ter:
- Ramo A (pai)
- Tarefa pai.
- Tópico de trabalho pai.
- Contexto de execução zero.
- Qualquer agendador único disponível para a consulta.
- Ramo B (adicional)
- Duas tarefas adicionais.
- Um thread de trabalho adicional vinculado a cada nova tarefa.
- Dois novos contextos de execução, um para cada nova tarefa.
- Um thread de trabalho é executado no agendador S1 . O outro é executado no agendador S2 .
- Filial C (adicional)
- Duas tarefas adicionais.
- Um thread de trabalho adicional vinculado a cada nova tarefa.
- Dois novos contextos de execução, um para cada nova tarefa.
- Um thread de trabalho é executado no agendador S1 . O outro é executado no agendador S2 .
- Ramo D (adicional)
- Duas tarefas adicionais.
- Um thread de trabalho adicional vinculado a cada nova tarefa.
- Dois novos contextos de execução, um para cada nova tarefa.
- Um thread de trabalho é executado no agendador S1 . O outro é executado no agendador S2 .
A questão é como todas essas tarefas extras, trabalhadores e contextos de execução são criados e quando eles começam a ser executados.
Sequência inicial
A sequência em que tarefas adicionais comece a executar para este plano específico é:
- Ramo A (tarefa pai).
- Ramo C (tarefas paralelas adicionais).
- Ramo D (tarefas paralelas adicionais).
- Ramo B (tarefas paralelas adicionais).
Essa pode não ser a ordem de inicialização que você esperava.
Pode haver um atraso significativo entre cada uma dessas etapas, por razões que exploraremos em breve. O ponto-chave neste estágio é que as tarefas adicionais, trabalhadores e contextos de execução não todos criados de uma vez, e eles não todos começam a ser executados ao mesmo tempo.
O SQL Server poderia ter sido projetado para iniciar todos os bits paralelos extras de uma só vez. Isso pode ser fácil de compreender, mas não seria muito eficiente em geral. Isso maximizaria o número de threads adicionais e outros recursos usados pela consulta e resultaria em muitas esperas paralelas desnecessárias.
Com o design empregado pelo SQL Server, os planos paralelos geralmente usam menos threads de trabalho totais do que (DOP multiplicado pelo número total de ramificações). Isso é alcançado reconhecendo que algumas ramificações podem ser executadas até a conclusão antes que outras ramificações precisem ser iniciadas. Isso pode permitir a reutilização de threads na mesma consulta e geralmente reduz o consumo de recursos em geral.
Vamos agora aos detalhes de como nosso plano paralelo é iniciado.
Abrindo Filial A
A verificação da consulta começa a ser executada com a tarefa pai chamando
Open() no iterador na raiz da árvore. Este é o início da sequência de execução:- Ramo A (tarefa pai).
- Ramo C (tarefas paralelas adicionais).
- Ramo D (tarefas paralelas adicionais).
- Ramo B (tarefas paralelas adicionais).
Estamos executando esta consulta com um plano 'real' solicitado, portanto, o iterador raiz não o operador de projeto de sequência no nó 0. Em vez disso, é o iterador de perfil invisível que registra métricas de tempo de execução em planos de modo de linha.
A ilustração abaixo mostra os iteradores de verificação de consulta no Ramo A do plano, com a posição dos iteradores de criação de perfil invisíveis representados pelos ícones de 'óculos'.
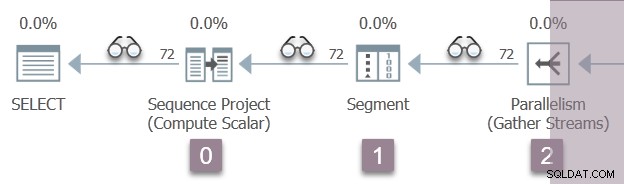
A execução começa com uma chamada para abrir o primeiro criador de perfil,
CQScanProfileNew::Open . Isso define o tempo de abertura para o operador do projeto de sequência filho por meio da API do Query Performance Counter do sistema operacional. Podemos ver esse número em
sys.dm_exec_query_profiles :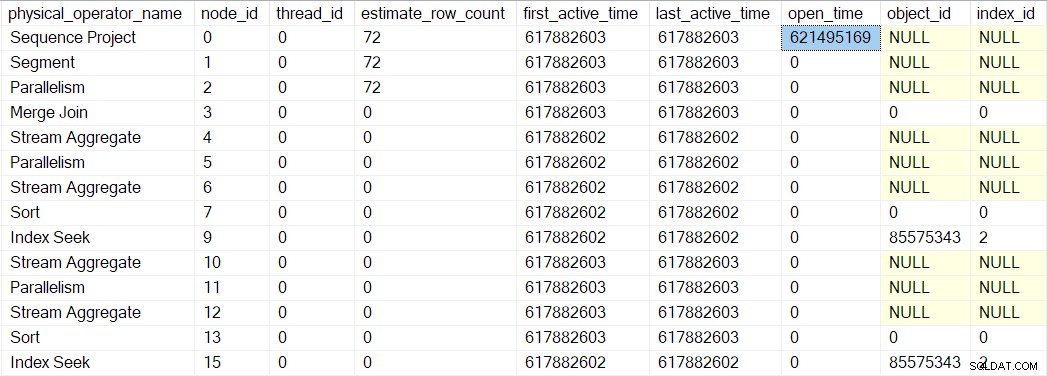
As entradas podem ter os nomes dos operadores listados, mas os dados vêm do profiler acima do operador, não o próprio operador.
Por acaso, um projeto de sequência (
CQScanSeqProjectNew ) não precisa fazer nenhum trabalho quando aberto , então ele não tem um Open() método. O criador de perfil acima do projeto de sequência é chamado, então um tempo aberto para o projeto de sequência é registrado no DMV. O
Open do criador de perfil método não chama Open no projeto de sequência (já que não tem um). Em vez disso, ele chama Open no criador de perfil para o próximo iterador em sequência. Este é o segmento iterador no nó 1. Isso define o tempo de abertura para o segmento, assim como o criador de perfil anterior fez para o projeto de sequência: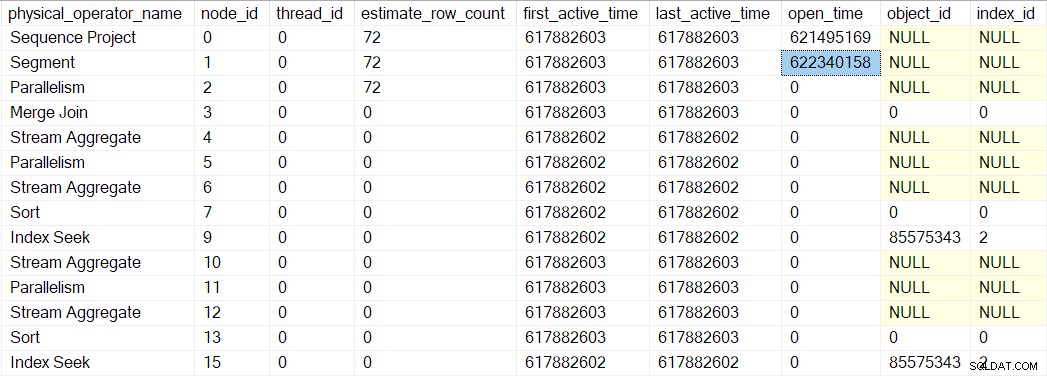
Um iterador de segmento faz tem coisas para fazer quando aberto, então a próxima chamada é para
CQScanSegmentNew::Open . Depois que o segmento tiver feito o que precisa, ele chama o criador de perfil para o próximo iterador em sequência — o consumidor lado da troca de fluxos de coleta no nó 2: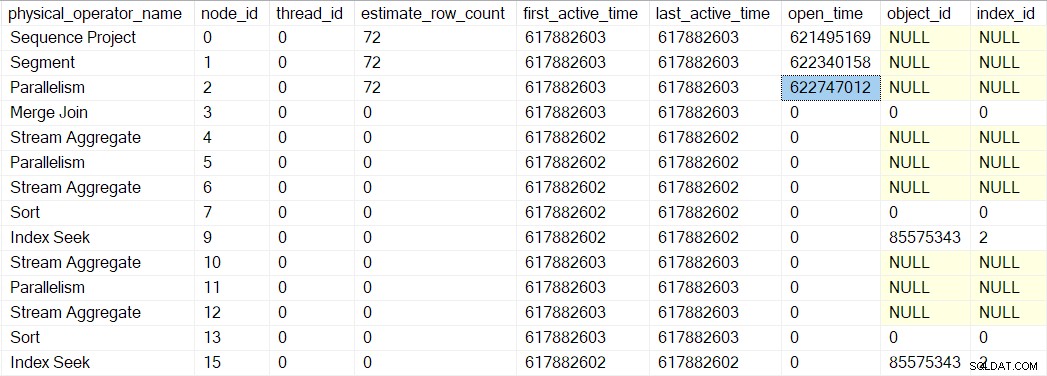
A próxima chamada da árvore de varredura de consulta no processo de abertura é
CQScanExchangeNew::Open , que é onde as coisas começam a ficar mais interessantes. Abrindo a troca de fluxos de coleta
Pedindo ao lado do consumidor da troca para abrir:
- Abre uma transação local (aninhada em paralelo) (
CXTransLocal::Open). Todo processo precisa de uma transação de contenção, e tarefas paralelas adicionais não são exceção. Eles não podem compartilhar a transação pai (base) diretamente, então transações aninhadas são usadas. Quando uma tarefa paralela precisa acessar a transação base, ela sincroniza em uma trava e pode encontrarNESTING_TRANSACTION_READONLYouNESTING_TRANSACTION_FULLespera. - Registra o thread de trabalho atual com a porta de troca (
CXPort::Register). - Sincroniza com outros encadeamentos no lado do consumidor da troca (
sqlmin!CXTransLocal::Synchronize). Não há outros tópicos no lado do consumidor de um fluxo de coleta, portanto, é essencialmente um não-op nesta ocasião.
Processamento “Fases iniciais”
A tarefa pai agora atingiu a borda da Filial A. A próxima etapa é particular para planos paralelos de modo de linha:a tarefa pai continua a execução chamando
CQScanExchangeNew::EarlyPhases no iterador de troca de fluxos de coleta no nó 2. Este é um método iterador adicional além do usual Open , GetRow e Close métodos com os quais muitos de vocês estarão familiarizados. EarlyPhases é chamado apenas em planos paralelos de modo de linha. Quero esclarecer algo neste momento:o lado do produtor da troca de fluxos de coleta no nó 2 não foi criado ainda, e não tarefas paralelas adicionais foram criadas. Ainda estamos executando o código para a tarefa pai, usando o único thread em execução no momento.
Nem todos os iteradores implementam
EarlyPhases , porque nem todos eles têm algo especial para fazer neste momento nos planos paralelos do modo de linha. Isso é análogo ao projeto de sequência que não implementa o Open método porque não tem nada a fazer naquele momento. Os principais iteradores com EarlyPhases métodos são:CQScanConcatNew(concatenação).CQScanMergeJoinNew(junção de mesclagem).CQScanSwitchNew(alternar).CQScanExchangeNew(paralelismo).CQScanNew(acesso ao conjunto de linhas, por exemplo, varreduras e buscas).CQScanProfileNew(criadores de perfil invisíveis).CQScanLightProfileNew(criadores de perfil leves invisíveis).
Fases iniciais da Filial B
A tarefa principal continua chamando
EarlyPhases em operadores filho além da troca de fluxos de coleta no nó 2. Uma tarefa movendo-se sobre um limite de ramificação pode parecer incomum, mas lembre-se de que o contexto de execução zero contém todo o plano serial, com as trocas incluídas. O processamento de fase inicial é sobre inicializar o paralelismo, então não conta como execução per se . Para ajudá-lo a acompanhar, a imagem abaixo mostra os iteradores no Ramo B do plano:
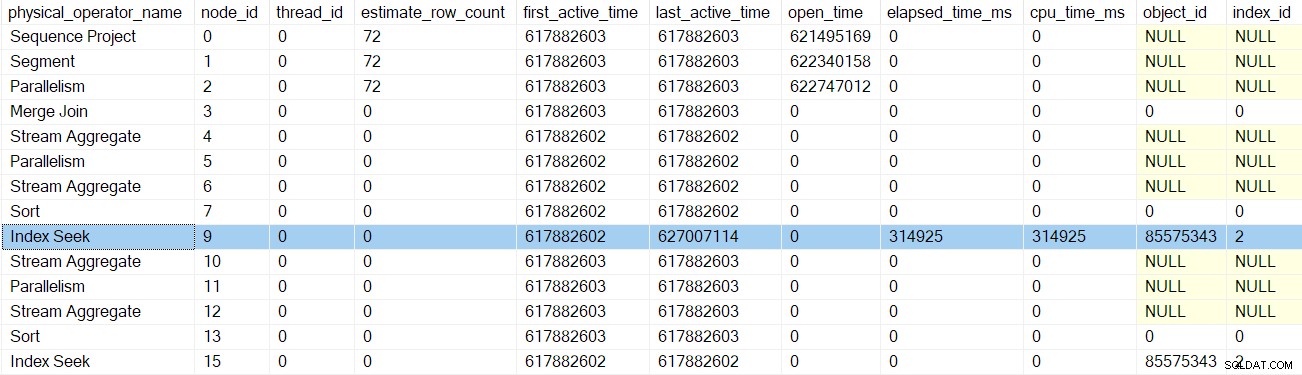
Lembre-se, ainda estamos no contexto de execução zero, então estou me referindo a isso apenas como Filial B por conveniência. Nós não começamos qualquer execução paralela ainda.
A sequência de invocações de código de fase inicial na Filial B é:
CQScanProfileNew::EarlyPhasespara o criador de perfil acima do nó 3.CQScanMergeJoinNew::EarlyPhasesno nó 3 junção de mesclagem .CQScanProfileNew::EarlyPhasespara o criador de perfil acima do nó 4. O nó 4 stream agregado em si não tem um método de fases iniciais.CQScanProfileNew::EarlyPhasesno criador de perfil acima do nó 5.CQScanExchangeNew::EarlyPhasespara os fluxos de partição troca no nó 5.
Observe que estamos processando apenas a entrada externa (superior) para a junção de mesclagem neste estágio. Esta é apenas a sequência iterativa de execução do modo de linha normal. Não é específico para planos paralelos.
Fases iniciais da Filial C
O processamento da fase inicial continua com os iteradores na Filial C:

A sequência de chamadas aqui é:
CQScanProfileNew::EarlyPhasespara o criador de perfil acima do nó 6.CQScanProfileNew::EarlyPhasespara o criador de perfil acima do nó 7.CQScanProfileNew::EarlyPhasesno criador de perfil acima do nó 9.CQScanNew::EarlyPhasespara o índice procure no nó 9.
Não há
EarlyPhases método na agregação ou classificação de fluxo. O trabalho realizado pela computação escalar no nó 8 é diferido (para a classificação), para que não apareça na árvore de verificação de consulta e não tenha um criador de perfil associado. Sobre os horários do criador de perfil
Tarefa pai processamento de fase inicial começou na troca de fluxos de coleta no nó 2. Ele desceu a árvore de varredura de consulta, seguindo a entrada externa (superior) até a junção de mesclagem, até a busca de índice no nó 9. Ao longo do caminho, a tarefa pai chamou as
EarlyPhases método em cada iterador que o suporta. Nenhuma das atividades das fases iniciais foi atualizada até agora a qualquer momento no DMV de criação de perfil. Especificamente, nenhum dos iteradores tocados pelo processamento de fases iniciais teve seu "tempo aberto" definido. Isso faz sentido, porque o processamento da fase inicial está apenas configurando a execução paralela — esses operadores serão abertos para execução posterior.
A busca de índice no nó 9 é um nó folha – não tem filhos. A tarefa pai agora começa a retornar das
EarlyPhases aninhadas chamadas, ascendente a árvore de varredura de consulta de volta para a troca de fluxos de coleta. Cada um dos criadores de perfil chama o Contador de desempenho de consulta API na entrada para suas
EarlyPhases método, e eles o chamam novamente na saída. A diferença entre os dois números representa o tempo decorrido para o iterador e todos os seus filhos (já que as chamadas de método são aninhadas). Após o retorno do criador de perfil para a busca de índice, o DMV do criador de perfil mostra o tempo decorrido e de CPU para a busca de índice apenas, bem como um último ativo atualizado Tempo. Observe também que essas informações são registradas em relação à tarefa pai (a única opção agora):
Nenhum dos iteradores anteriores tocados pelas chamadas de fases iniciais têm tempos decorridos ou atualizados os últimos tempos ativos. Esses números só são atualizados quando subimos na árvore.
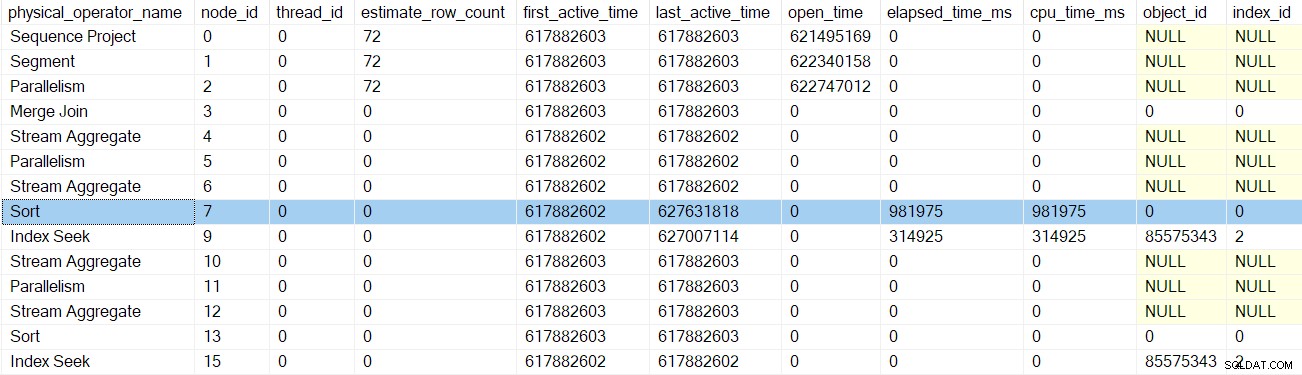
Após o retorno da chamada das fases iniciais do próximo criador de perfil, a classificação os horários são atualizados:
O próximo retorno nos leva além do criador de perfil para o agregado de fluxo no nó 6:
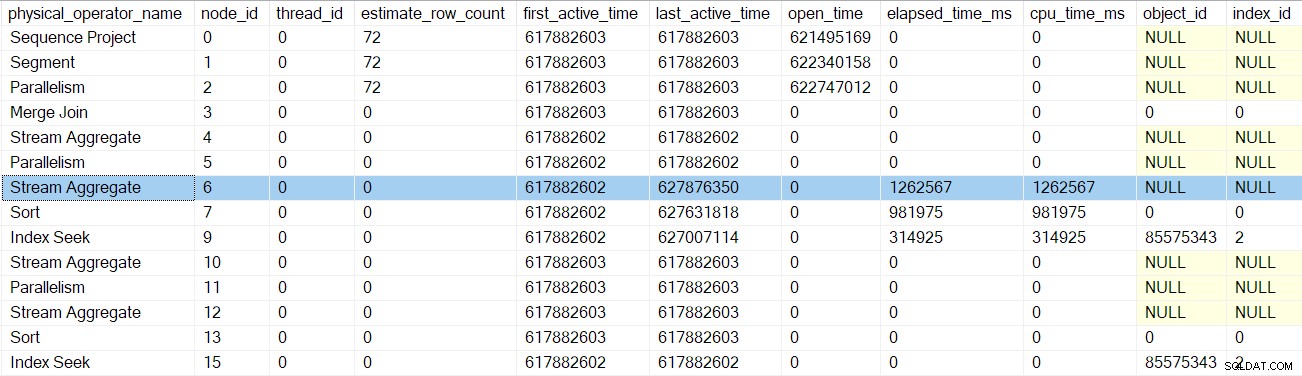
Retornar deste criador de perfil nos leva de volta às
EarlyPhases ligue nos fluxos de partição troca no nó 5 . Lembre-se de que não foi aqui que a sequência de chamadas de fases iniciais começou — essa foi a troca de fluxos de coleta no nó 2. Tarefas paralelas da ramificação C enfileiradas
Além de atualizar os dados de perfil, as chamadas anteriores das fases iniciais não pareciam fazer muito. Isso tudo muda com os fluxos de partição troca no nó 5.
Vou descrever o Ramo C com uma quantidade razoável de detalhes para introduzir vários conceitos importantes, que também se aplicarão aos outros ramos paralelos. Cobrir esse terreno uma vez agora significa que a discussão posterior do ramo pode ser mais sucinta.
Tendo concluído o processamento de fase inicial aninhado para sua subárvore (até a busca de índice no nó 9), a troca pode iniciar seu próprio trabalho de fase inicial. Isso começa da mesma forma que abertura a troca de fluxos de coleta no nó 2:
CXTransLocal::Open(abrindo a subtransação paralela local).CXPort::Register(registrando com a porta de troca).
As próximas etapas são diferentes porque a ramificação C contém um bloqueio totalmente iterador (a classificação no nó 7). O processamento da fase inicial nos fluxos de repartição do nó 5 faz o seguinte:
- Chama
CQScanExchangeNew::StartAllProducers. Esta é a primeira vez que encontramos algo referente ao lado do produtor da troca. O nó 5 é a primeira troca neste plano a criar seu lado produtor. - Adquire um mutex para que nenhum outro encadeamento possa enfileirar tarefas ao mesmo tempo.
- Inicia transações aninhadas paralelas para as tarefas do produtor (
CXPort::StartNestedTransactionseReadOnlyXactImp::BeginParallelNestedXact). - Registra as subtransações com o objeto de verificação de consulta pai (
CQueryScan::AddSubXact). - Cria descritores de produtores (
CQScanExchangeNew::PxproddescCreate). - Cria novos contextos de execução do produtor (
CExecContext) derivado do contexto de execução zero. - Atualiza o mapa vinculado de iteradores de plano.
- Define DOP para o novo contexto (
CQueryExecContext::SetDop) para que todas as tarefas saibam qual é a configuração geral do DOP. - Inicializa o cache de parâmetro (
CQueryExecContext::InitParamCache). - Vincula as transações paralelas aninhadas à transação base (
CExecContext::SetBaseXact). - Enfileira os novos subprocessos para execução (
SubprocessMgr::EnqueueMultipleSubprocesses). - Cria novas tarefas paralelas tarefas via
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
A pilha de chamadas da tarefa pai (para aqueles que gostam dessas coisas) nesse momento é:
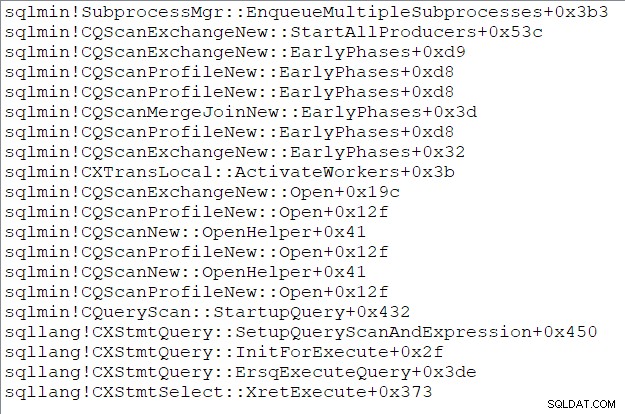
Fim da Parte Três
Agora criamos o lado do produtor da troca de fluxos de repartição no nó 5, criou tarefas paralelas adicionais para executar a Filial C e vinculou tudo de volta ao pai estruturas conforme necessário. A Filial C é a primeira branch para iniciar quaisquer tarefas paralelas. A parte final desta série examinará detalhadamente a abertura da ramificação C e iniciará as tarefas paralelas restantes.