Suponha que você esteja projetando um aplicativo de banco de dados SQL Server para o CEO de uma empresa e precise exibir o quinto funcionário mais bem pago da empresa.
O que você faria? Uma solução é escrever uma consulta como esta:
SELECT EmployeeName FROM Employees ORDER BY Salary DESC OFFSET 4 ROWS FETCH FIRST 1 ROWS ONLY;
A consulta acima parece complicada, principalmente se você precisar classificar todos os funcionários. Nesse caso, uma solução é listar os funcionários por ordem decrescente de salário e depois tomar o índice do funcionário como posto. No entanto, as coisas ficam complicadas se os vários funcionários tiverem o mesmo salário. Como você os classificaria?
Felizmente, o SQL Server vem com funções de classificação internas que podem ser usadas para classificar registros de várias maneiras. Neste artigo, apresentaremos as funções de classificação do SQL Server em detalhes, ilustrando-as com os exemplos.
Existem quatro tipos diferentes de função de classificação no SQL Server:
- Classificação()
- Dense_Rank()
- Número da linha()
- Ntile()
É importante mencionar que todas as funções de classificação no SQL Server requerem a cláusula ORDER BY.
Antes de examinarmos cada uma das funções de classificação em detalhes, primeiro, vamos criar dados fictícios que usaremos neste artigo para explicar a função de classificação. Execute o seguinte script:
CREATE DATABASE Showroom
Use Showroom
CREATE TABLE Car
(
CarId int identity(1,1) primary key,
Name varchar(100),
Make varchar(100),
Model int ,
Price int ,
Type varchar(20)
)
insert into Car( Name, Make, Model , Price, Type)
VALUES ('Corrolla','Toyota',2015, 20000,'Sedan'),
('Civic','Honda',2018, 25000,'Sedan'),
('Passo','Toyota',2012, 18000,'Hatchback'),
('Land Cruiser','Toyota',2017, 40000,'SUV'),
('Corrolla','Toyota',2011, 17000,'Sedan'),
('Vitz','Toyota',2014, 15000,'Hatchback'),
('Accord','Honda',2018, 28000,'Sedan'),
('7500','BMW',2015, 50000,'Sedan'),
('Parado','Toyota',2011, 25000,'SUV'),
('C200','Mercedez',2010, 26000,'Sedan'),
('Corrolla','Toyota',2014, 19000,'Sedan'),
('Civic','Honda',2015, 20000,'Sedan') No script acima, criamos o banco de dados do Showroom com uma tabela Car. A tabela Car possui cinco atributos:CarId, Name, Make, Model, Price e Type.
Em seguida, adicionamos 12 registros fictícios na tabela Carro.
Agora, você vê cada uma das funções de classificação.
1. Função de classificação
A função de classificação no SQL Server atribui classificação a cada registro ordenado pela cláusula ORDER BY. Por exemplo, se você quiser ver o quinto carro mais caro na tabela Carro, você pode usar a função de classificação da seguinte forma:
Use Showroom SELECT Name,Make,Model, Price, Type, RANK() OVER(ORDER BY Price DESC) as PriceRank FROM Car
No script acima, selecione o Nome, Marca, Modelo, Preço, Tipo e a classificação de cada carro encomendado por Preço na coluna “PriceRank”. A sintaxe da função Rank é simples. Você tem que escrever a função RANK seguida do operador OVER. Dentro do operador OVER, você precisa passar a cláusula ORDER BY que ordena os dados. A saída do script acima é assim:
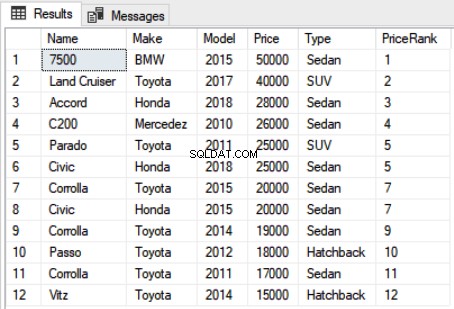
Você pode ver a classificação para cada carro. É importante mencionar que se houver empate entre as classificações de dois recordes, a próxima posição do ranking é ignorada. Por exemplo, há um empate entre o registro 5 e 6 na saída. Tanto o Parado quanto o Civic têm preços iguais e, portanto, foram classificados em 5. No entanto, a próxima classificação, em particular, a classificação 6, é ignorada e os próximos dois carros na lista foram classificados em 7, pois também têm o mesmo preço. Após a 7ª classificação, a classificação 8 é ignorada novamente e a próxima classificação atribuída é 9.
Você pode dividir os dados em partições e, em seguida, aplicar a classificação a partições individuais. No script a seguir, há a partição dos registros por tipo. Classificamos os carros dentro de cada partição.
SELECT Name,Make,Model, Price, Type, RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as PriceRank FROM Car
A saída do script acima é assim:
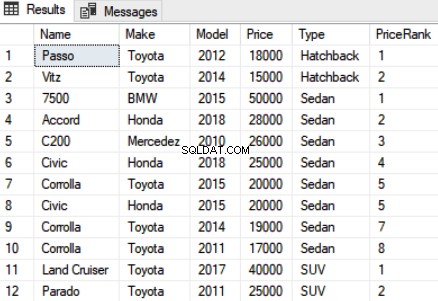
É evidente a partir da saída que os registros foram particionados de acordo com os tipos de carro e a classificação foi atribuída localmente dentro da partição. Por exemplo, os dois primeiros registros pertencem à partição “Hatchback” e foram classificados em 1 e 2. Para a próxima partição, ou seja, “Sedan”, a classificação é redefinida para 1.
2. Função Dense_Rank
A função densa_rank é semelhante à função rank. No entanto, no caso de denso_rank, se houver empate entre dois registros em termos de classificação, a próxima classificação não será ignorada. Vamos ver demonstrá-lo com o exemplo. Execute o seguinte script:
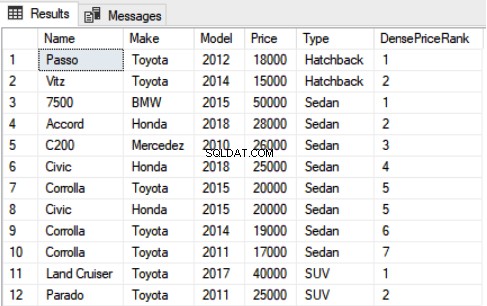
Use Showroom SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(ORDER BY Price DESC) as DensePriceRank FROM Car
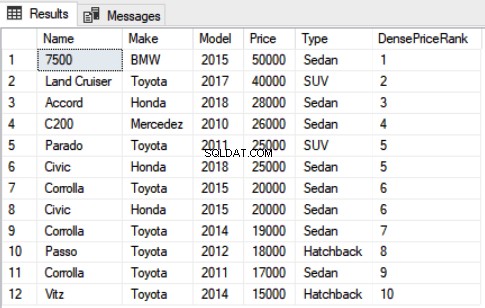
Novamente, você pode ver que o 5º e o 6º registro têm o mesmo valor para Price e ambos receberam a classificação 5. No entanto, ao contrário da função de classificação que pulou a próxima classificação, a função densa_rank não pula a próxima classificação e a classificação 6 foi atribuído ao próximo registro.
Assim como a função de classificação, a função de classificação_densidade também pode ser aplicada à partição por cláusula. Observe o seguinte roteiro:
SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as DensePriceRank FROM Car
A saída do script acima é assim:
3. Função Row_Number
A função row_number também classifica os registros de acordo com as condições especificadas pela cláusula ORDER BY. No entanto, ao contrário das funções de classificação e densa_rank, a função row_number não atribui a mesma classificação onde há valores duplicados para a coluna especificada pela cláusula ORDER BY. Observe o seguinte roteiro:
SELECT Name,Make,Model, Price, Type, DENSE_RANK() OVER(PARTITION BY Type ORDER BY Price DESC) as DensePriceRank FROM Car
A saída do script acima é assim:
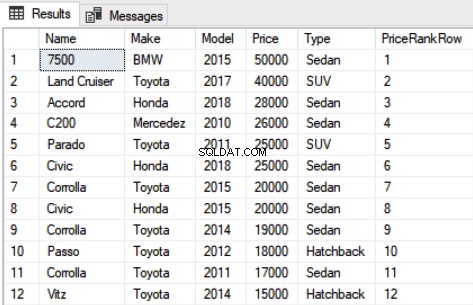
No script acima, você pode ver que o 5º e o 6º registros têm o mesmo valor para a coluna Price, mas a classificação atribuída a eles é diferente.
Da mesma forma, a função row_number pode ser aplicada aos dados particionados. Veja o script a seguir, por exemplo.
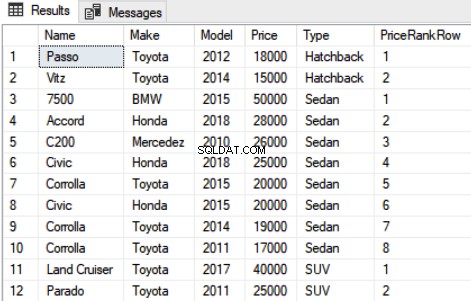
SELECT Name,Make,Model, Price, Type, ROW_NUMBER() OVER(PARTITION BY Type ORDER BY Price DESC) AS PriceRankRow FROM Car
A saída do script acima é assim:
4. Função NTILE
A função NTILE agrupa a classificação. Suponha que você tenha 12 registros em uma tabela e queira classificá-los em grupos de 4. Os três primeiros registros terão classificação 1, os próximos três registros terão classificação 2 e assim por diante.
Vamos dar uma olhada em um exemplo da função NTILE.
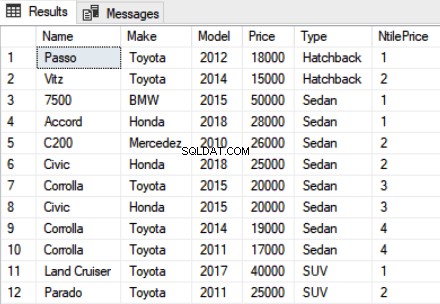
Use Showroom SELECT Name,Make,Model, Price, Type, NTILE(4) OVER(ORDER BY Price DESC) as NtilePrice FROM Car
No script acima, passamos 4 como parâmetro para a função NTILE. Como temos 12 registros, você verá um total de 4 classificações diferentes, onde 1 classificação será atribuída a três registros. A saída fica assim:
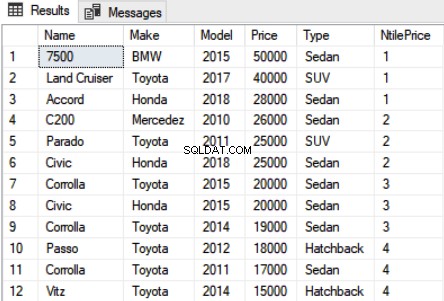
Você pode ver que os três primeiros carros mais caros foram classificados em 1, os três seguintes foram classificados em 2 e assim por diante.
A função NTILE também pode ser aplicada aos dados particionados. Observe o seguinte roteiro:
SELECT Name,Make,Model, Price, Type, NTILE(4) OVER(PARTITION BY Type ORDER BY Price DESC) as NtilePrice FROM Car
Conclusão
As funções de classificação no SQL Server são usadas para classificar dados de diferentes maneiras. Nesta leitura, introduzimos diferentes tipos de funções de classificação com os exemplos. As funções rank e density_rank dão a mesma classificação aos dados com os mesmos valores na cláusula ORDER BY enquanto a função row_number classifica o registro de forma incremental mesmo se houver empate.
No caso de não haver registros duplicados na coluna especificada pela cláusula ORDER BY, as funções rank, densa_rank e row_number se comportam de maneira semelhante.