Este artigo mostra como o SQL Server combina informações de densidade de várias estatísticas de coluna única para produzir uma estimativa de cardinalidade para uma agregação em várias colunas. Espera-se que os detalhes sejam interessantes por si mesmos. Eles também fornecem uma visão sobre algumas das abordagens gerais e algoritmos usados pelo estimador de cardinalidade.
Considere a seguinte consulta de banco de dados de exemplo do AdventureWorks, que lista o número de itens de inventário de produtos em cada compartimento em cada prateleira do depósito:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin; O plano de execução estimado mostra 1.069 linhas sendo lidas da tabela, classificadas em
Shelf e Bin order e, em seguida, agregados usando um operador Stream Aggregate: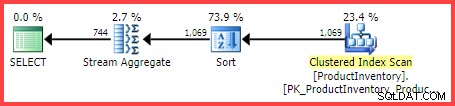
Plano de Execução Estimado
A questão é:como o otimizador de consultas do SQL Server chegou à estimativa final de 744 linhas?
Estatísticas disponíveis
Ao compilar a consulta acima, o otimizador de consulta criará estatísticas de coluna única na
Shelf e Bin colunas, se as estatísticas adequadas ainda não existirem. Entre outras coisas, essas estatísticas fornecem informações sobre o número de valores de coluna distintos (no vetor de densidade):DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; Os resultados estão resumidos na tabela abaixo (a terceira coluna é calculada a partir da densidade):
| Coluna | Densidade | 1 / Densidade |
|---|---|---|
| Prateleira | 0,04761905 | 21 |
| Caixa | 0,01612903 | 62 |
Informações do vetor de densidade de prateleira e caixa
Como observa a documentação, o recíproco da densidade é o número de valores distintos na coluna. A partir das informações estatísticas mostradas acima, o SQL Server sabe que havia 21
Shelf distintos valores e 62 Bin distintos valores na tabela, quando as estatísticas foram coletadas. A tarefa de estimar o número de linhas produzidas por um
GROUP BY cláusula é trivial quando apenas uma única coluna está envolvida (supondo que não haja outros predicados). Por exemplo, é fácil ver que GROUP BY Shelf produzirá 21 linhas; GROUP BY Bin produzirá 62. No entanto, não está imediatamente claro como o SQL Server pode estimar o número de
(Shelf, Bin) distintos combinações para nosso GROUP BY Shelf, Bin inquerir. Colocando a questão de uma maneira um pouco diferente:Dadas 21 prateleiras e 62 caixas, quantas combinações únicas de prateleiras e caixas haverá? Deixando de lado os aspectos físicos e outros conhecimentos humanos do domínio do problema, a resposta pode estar em qualquer lugar de max(21, 62) =62 a (21 * 62) =1.302. Sem mais informações, não há uma maneira óbvia de saber onde lançar uma estimativa nesse intervalo. No entanto, para nossa consulta de exemplo, o SQL Server estima 744.312 linhas (arredondadas para 744 na visualização do Plan Explorer), mas em que base?
Evento Estendido de Estimativa de Cardinalidade
A maneira documentada de analisar o processo de estimativa de cardinalidade é usar o evento estendido
query_optimizer_estimate_cardinality (apesar de estar no canal "debug"). Enquanto uma sessão que coleta esse evento está em execução, os operadores do plano de execução obtêm uma propriedade adicional StatsCollectionId que liga as estimativas de operadores individuais aos cálculos que as produziram. Para nossa consulta de exemplo, o ID de coleta de estatísticas 2 está vinculado à estimativa de cardinalidade do grupo por operador agregado. A saída relevante do Extended Event para nossa consulta de teste é:
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> Há algumas informações úteis lá, com certeza.
Podemos ver que a classe de calculadora de valores distintos da folha do plano (
CDVCPlanLeaf ) foi empregado, usando estatísticas de coluna única em Shelf e Bin como entradas. O elemento de coleta de estatísticas corresponde a este fragmento ao id (2) mostrado no plano de execução, que mostra a estimativa de cardinalidade de 744,31 , e mais informações sobre os IDs de objetos de estatísticas usados também. Infelizmente, não há nada na saída do evento que diga exatamente como a calculadora chegou ao valor final, que é o que realmente nos interessa.
Combinando contagens distintas
Seguindo uma rota menos documentada, podemos solicitar um plano estimado para a consulta com sinalizadores de rastreamento 2363 e 3604 habilitado:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); Isso retorna informações de depuração para a guia Mensagens no SQL Server Management Studio. A parte interessante é reproduzida abaixo:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation Isso mostra as mesmas informações que o Extended Event mostrou em um formato (sem dúvida) mais fácil de consumir:
- O operador relacional de entrada para calcular uma estimativa de cardinalidade para (
LogOp_GbAgg– grupo lógico por agregado) - A calculadora usada (
CDVCPlanLeaf) e estatísticas de entrada - Os detalhes da coleta de estatísticas resultantes
A nova informação interessante é a parte sobre como usar a cardinalidade do ambiente para combinar contagens distintas .
Isso mostra claramente que os valores 21, 62 e 1069 foram usados, mas (frustrantemente) ainda não exatamente quais cálculos foram realizados para chegar ao 744.312 resultado.
Para o depurador!
Anexar um depurador e usar símbolos públicos nos permite explorar em detalhes o caminho do código seguido durante a compilação da consulta de exemplo.
O instantâneo abaixo mostra a parte superior da pilha de chamadas em um ponto representativo do processo:
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
Há alguns detalhes interessantes aqui. Trabalhando de baixo para cima, vemos que a cardinalidade está sendo derivada usando o CE atualizado (
CCardFrameworkSQL12 ) disponível no SQL Server 2014 e posterior (o CE original é CCardFrameworkSQL7 ), para o grupo por operador lógico agregado (CLogOp_GbAgg ). Calcular a cardinalidade distinta envolve combinar (munging) múltiplas entradas, usando amostragem sem reposição.
A referência a
H e um logaritmo (natural) no segundo método a partir do topo mostra o uso de Shannon Entropy no cálculo: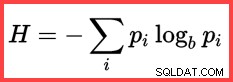
Entropia Shannon
A entropia pode ser usada para estimar a correlação informacional (informações mútuas) entre duas estatísticas:
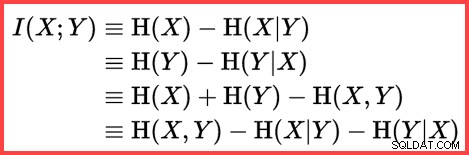
Informações mútuas
Juntando tudo isso, podemos construir um script de cálculo T-SQL combinando a maneira como o SQL Server usa amostragem sem substituição, Shannon Entropy e informações mútuas para produzir a estimativa final de cardinalidade.
Começamos com os números de entrada (cardinalidade do ambiente e o número de valores distintos em cada coluna):
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; A frequência de cada coluna é o número médio de linhas por valor distinto:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; Amostragem sem reposição (SWR) é uma simples questão de subtrair o número médio de linhas por valor distinto (frequência) do número total de linhas:
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; Calcule as entropias (N log N) e as informações mútuas:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); Agora que estimamos o quão correlacionados são os dois conjuntos de estatísticas, podemos calcular a estimativa final:
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
O resultado do cálculo é 744,311823994677, que é 744,312 arredondado para três casas decimais.
Por conveniência, aqui está todo o código em um bloco:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; Considerações finais
A estimativa final é imperfeita neste caso – a consulta de exemplo retorna 441 linhas.
Para obter uma estimativa melhorada, podemos fornecer ao otimizador melhores informações sobre a densidade do
Bin e Shelf colunas usando uma estatística de várias colunas. Por exemplo:CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
Com essa estatística em vigor (como fornecida ou como um efeito colateral da adição de um índice de várias colunas semelhante), a estimativa de cardinalidade para a consulta de exemplo está exatamente correta. No entanto, é raro calcular uma agregação tão simples. Com predicados adicionais, a estatística multicoluna pode ser menos eficaz. No entanto, é importante lembrar que as informações de densidade adicionais fornecidas pelas estatísticas de várias colunas podem ser úteis para agregações (assim como para comparações de igualdade).
Sem uma estatística de várias colunas, uma consulta agregada com predicados adicionais ainda poderá usar a lógica essencial mostrada neste artigo. Por exemplo, em vez de aplicar a fórmula à cardinalidade da tabela, ela pode ser aplicada aos histogramas de entrada passo a passo.
Conteúdo relacionado:Estimativa de cardinalidade para um predicado em uma expressão COUNT