Existem duas habilidades complementares que são muito úteis no ajuste de consultas. Uma é a capacidade de ler e interpretar planos de execução. A segunda é saber um pouco sobre como o otimizador de consultas funciona para traduzir o texto SQL em um plano de execução. Juntar as duas coisas pode nos ajudar a identificar momentos em que uma otimização esperada não foi aplicada, resultando em um plano de execução que não é tão eficiente quanto poderia ser. A falta de documentação sobre exatamente quais otimizações o SQL Server pode aplicar (e em quais circunstâncias) significa que muito disso se resume à experiência.
Um exemplo
A consulta de exemplo para este artigo é baseada na pergunta feita pelo MVP do SQL Server Fabiano Amorim há alguns meses, com base em um problema do mundo real que ele encontrou. O esquema e a consulta de teste abaixo são uma simplificação da situação real, mas mantêm todos os recursos importantes.
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Teste 1 – 10.000 linhas, SQL Server 2005+
Os dados específicos da tabela realmente não importam para esses testes. As consultas a seguir simplesmente carregam 10.000 linhas de uma tabela de números para cada uma das três tabelas de teste:
INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 10000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1;
Com os dados carregados, o plano de execução produzido para a consulta de teste é:
SELECT MAX(c1) FROM dbo.V1;
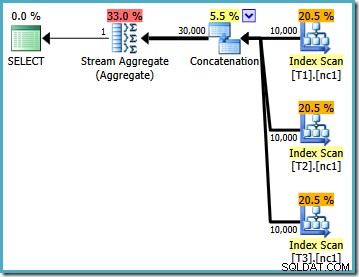
Este plano de execução é uma implementação bastante direta da consulta SQL lógica (após a referência de visualização V1 ser expandida). O otimizador vê a consulta após a expansão da visualização, quase como se a consulta tivesse sido escrita por completo:
SELECT MAX(c1)
FROM
(
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3
) AS V1; Comparando o texto expandido com o plano de execução, fica clara a franqueza da implementação do otimizador de consulta. Existe um Index Scan para cada leitura das tabelas base, um operador de Concatenação para implementar o
UNION ALL , e um Stream Aggregate para o MAX final agregar. As propriedades do plano de execução mostram que a otimização baseada em custo foi iniciada (o nível de otimização é
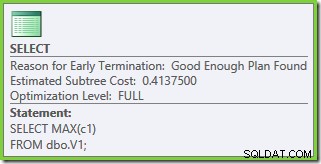
FULL ), mas que terminou cedo porque foi encontrado um plano "bom o suficiente". O custo estimado do plano selecionado é 0,1016240 unidades otimizadoras mágicas. 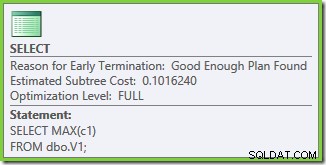
Teste 2 – 50.000 linhas, SQL Server 2008 e 2008 R2
Execute o script a seguir para redefinir o ambiente de teste para executar com 50.000 linhas:
TRUNCATE TABLE dbo.T1; TRUNCATE TABLE dbo.T2; TRUNCATE TABLE dbo.T3; INSERT dbo.T1 (pk, c1) SELECT n, n FROM dbo.Numbers AS N WHERE n BETWEEN 1 AND 50000; INSERT dbo.T2 (pk, c1) SELECT pk, c1 FROM dbo.T1; INSERT dbo.T3 (pk, c1) SELECT pk, c1 FROM dbo.T1; SELECT MAX(c1) FROM dbo.V1;
O plano de execução para este teste depende da versão do SQL Server que você está executando. No SQL Server 2008 e 2008 R2, temos o seguinte plano:
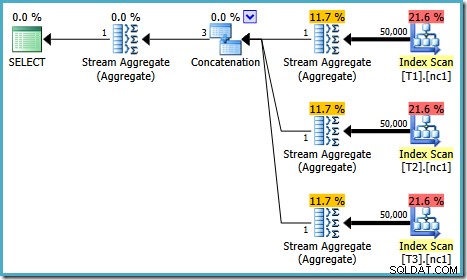
As propriedades do plano mostram que a otimização baseada em custo ainda terminou cedo pelo mesmo motivo de antes. O custo estimado é maior do que antes em 0,41375 unidades, mas isso é esperado devido à maior cardinalidade das tabelas base.
Teste 3 – 50.000 linhas, SQL Server 2005 e 2012
A mesma consulta executada em 2005 ou 2012 produz um plano de execução diferente:
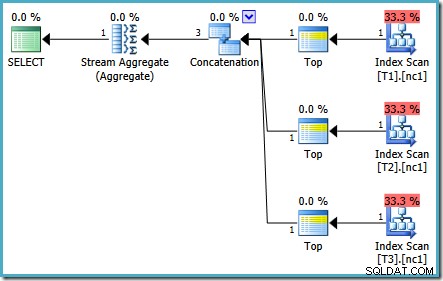
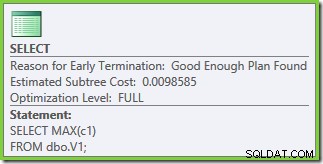
A otimização terminou mais cedo novamente, mas o custo estimado do plano para 50.000 linhas por tabela base caiu para 0,0098585 (de 0,41375 no SQL Server 2008 e 2008 R2).
Explicação
Como você deve saber, o otimizador de consulta do SQL Server separa o esforço de otimização em vários estágios, com os estágios posteriores adicionando mais técnicas de otimização e permitindo mais tempo. As etapas de otimização são:
- Plano trivial
- Otimização baseada em custo
- Processamento de transações (pesquisa 0)
- Plano rápido (pesquisa 1)
- Plano rápido com paralelismo ativado
- Otimização completa (pesquisa 2)
Nenhum dos testes realizados aqui se qualifica para um plano trivial porque o agregado e os sindicatos têm múltiplas possibilidades de implementação, exigindo uma decisão baseada em custos.
Processamento de transações
O estágio de Processamento de Transação (TP) requer que uma consulta contenha pelo menos três referências de tabela, caso contrário, a otimização baseada em custo ignora esse estágio e passa direto para o Plano Rápido. O estágio TP destina-se às consultas de navegação de baixo custo típicas de cargas de trabalho OLTP. Ele tenta um número limitado de técnicas de otimização e está limitado a encontrar planos com associações de loop aninhadas (a menos que uma associação de hash seja necessária para gerar um plano válido).
Em alguns aspectos, é surpreendente que a consulta de teste se qualifique para um estágio destinado a encontrar planos OLTP. Embora a consulta contenha as três referências de tabela necessárias, ela não contém junções. O requisito de três tabelas é apenas uma heurística, então não vou me alongar no assunto.
Quais estágios do otimizador foram executados?
Existem vários métodos, sendo o documentado para comparar o conteúdo de sys.dm_exec_query_optimizer_info antes e depois da compilação. Isso é bom, mas registra informações de toda a instância, portanto, você precisa ter cuidado para que a sua seja a única compilação de consulta que acontece entre os instantâneos.
Uma alternativa não documentada (mas razoavelmente conhecida) que funciona em todas as versões atualmente com suporte do SQL Server é habilitar os sinalizadores de rastreamento 8675 e 3604 durante a compilação da consulta.
Teste 1
Este teste produz uma saída do sinalizador de rastreamento 8675 semelhante à seguinte:

O custo estimado de 0,101624 após o estágio TP é baixo o suficiente para que o otimizador não procure planos mais baratos. O plano simples com o qual acabamos é bastante razoável, dada a cardinalidade relativamente baixa das tabelas base, mesmo que não seja realmente ideal.
Teste 2
Com 50.000 linhas em cada tabela base, o sinalizador de rastreamento revela informações diferentes:

Desta vez, o custo estimado após o estágio TP é 0,428735 (mais linhas =maior custo). Isso é suficiente para encorajar o otimizador a entrar no estágio Quick Plan. Com mais técnicas de otimização disponíveis, esta etapa encontra um plano com custo de 0,41375 . Isso não representa uma grande melhoria em relação ao plano de teste 1, mas é menor do que o limite de custo padrão para paralelismo e não é suficiente para entrar na Otimização Completa, então, novamente, a otimização termina mais cedo.
Teste 3
Para a execução do SQL Server 2005 e 2012, a saída do sinalizador de rastreamento é:

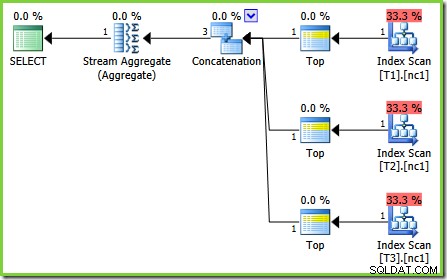
Há pequenas diferenças no número de tarefas executadas entre as versões, mas a diferença importante é que no SQL Server 2005 e 2012, o estágio Quick Plan encontra um plano que custa apenas 0,0098543 unidades. Este é o plano que contém os operadores Top em vez dos três Stream Aggregates abaixo do operador Concatenation visto nos planos do SQL Server 2008 e 2008 R2.
Bugs e correções não documentadas
SQL Server 2008 e 2008 R2 contêm um bug de regressão (comparado com 2005) que foi corrigido no sinalizador de rastreamento 4199, mas não documentado até onde eu sei. Há documentação para o TF 4199 que lista as correções disponibilizadas em sinalizadores de rastreamento separados antes de serem cobertos pelo 4199, mas como diz o artigo da Base de Conhecimento:
Esse sinalizador de rastreamento único pode ser usado para habilitar todas as correções feitas anteriormente para o processador de consulta em vários sinalizadores de rastreamento. Além disso, todas as futuras correções do processador de consultas serão controladas usando esse sinalizador de rastreamento.
O bug neste caso é uma daquelas 'correções futuras do processador de consultas'. Uma regra de otimização específica, ScalarGbAggToTop , não é aplicado aos novos agregados vistos no plano de teste 2. Com o sinalizador de rastreamento 4199 habilitado em compilações adequadas do SQL Server 2008 e 2008 R2, o bug é corrigido e o plano ideal do teste 3 é obtido:
-- Trace flag 4199 required for 2008 and 2008 R2 SELECT MAX(c1) FROM dbo.V1 OPTION (QUERYTRACEON 4199);
Conclusão
Quando você souber que o otimizador pode transformar um
MIN escalar ou MAX agregar a um TOP (1) em um fluxo ordenado, o plano mostrado no teste 2 parece estranho. Os agregados escalares acima de uma varredura de índice (que pode fornecer ordem se solicitado) se destacam como uma otimização perdida que normalmente seria aplicada. Este é o ponto que eu estava enfatizando na introdução:uma vez que você tenha uma ideia dos tipos de coisas que o otimizador pode fazer, ele pode ajudá-lo a reconhecer casos em que algo deu errado.
A resposta nem sempre será habilitar o sinalizador de rastreamento 4199, pois você pode encontrar problemas que ainda não foram corrigidos. Você também pode não querer que as outras correções de QP cobertas pelo sinalizador de rastreamento sejam aplicadas em um caso específico – as correções do otimizador nem sempre melhoram as coisas. Se o fizessem, não haveria necessidade de proteção contra regressões de plano infelizes usando esse sinalizador.
A solução em outros casos pode ser formular a consulta SQL usando uma sintaxe diferente, dividir a consulta em partes mais amigáveis ao otimizador ou algo completamente diferente. Seja qual for a resposta, ainda vale a pena saber um pouco sobre os internos do otimizador para que você possa reconhecer que houve um problema em primeiro lugar :)