As pessoas se perguntam se devem fazer o possível para evitar exceções ou apenas deixar o sistema lidar com elas. Já vi várias discussões em que as pessoas debatem se devem fazer o que puderem para evitar uma exceção, porque o tratamento de erros é "caro". Não há dúvida de que o tratamento de erros não é gratuito, mas eu prevejo que uma violação de restrição é pelo menos tão eficiente quanto verificar primeiro uma possível violação. Isso pode ser diferente para uma violação de chave e uma violação de restrição estática, por exemplo, mas neste post vou focar na primeira.
As principais abordagens que as pessoas usam para lidar com exceções são:
- Deixe o mecanismo lidar com isso e envie qualquer exceção de volta ao chamador.
- Usar
BEGIN TRANSACTIONeROLLBACKif@@ERROR <> 0. - Usar
TRY/CATCHcomROLLBACKnoCATCHbloco (SQL Server 2005+).
E muitos adotam a abordagem de que devem verificar se vão incorrer na violação primeiro, pois parece mais fácil lidar com a duplicata do que forçar o mecanismo a fazê-lo. Minha teoria é que você deve confiar, mas verificar; por exemplo, considere esta abordagem (principalmente pseudocódigo):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END Sabemos que o
IF NOT EXISTS check não garante que outra pessoa não terá inserido a linha no momento em que chegarmos ao INSERT (a menos que coloquemos travas agressivas na mesa e/ou usemos SERIALIZABLE ), mas a verificação externa nos impede de tentar cometer uma falha e depois ter que reverter. Ficamos de fora de todo o TRY/CATCH estrutura se já sabemos que o INSERT falhará, e seria lógico supor que - pelo menos em alguns casos - isso será mais eficiente do que inserir o TRY/CATCH estrutura incondicionalmente. Isso faz pouco sentido em um único INSERT cenário, mas imagine um caso em que há mais acontecendo nesse TRY bloqueio (e mais violações potenciais que você pode verificar com antecedência, o que significa ainda mais trabalho que você pode ter que executar e depois reverter caso ocorra uma violação posterior). Agora, seria interessante ver o que aconteceria se você usasse um nível de isolamento não padrão (algo que tratarei em um post futuro), principalmente com simultaneidade. Para este post, porém, eu queria começar devagar e testar esses aspectos com um único usuário. Criei uma tabela chamada
dbo.[Objects] , uma tabela muito simplista:CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Eu queria preencher esta tabela com 100.000 linhas de dados de amostra. Para tornar os valores na coluna name únicos (já que o PK é a restrição que eu queria violar), criei uma função auxiliar que recebe um número de linhas e uma string mínima. A string mínima seria usada para garantir que (a) o conjunto começasse além do valor máximo na tabela Objetos ou (b) o conjunto iniciasse no valor mínimo na tabela Objetos. (Vou especificá-los manualmente durante os testes, verificados simplesmente inspecionando os dados, embora eu provavelmente pudesse ter incorporado essa verificação na função.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Isso aplica um
CROSS JOIN de sys.all_objects sobre si mesmo, anexando um número_linha exclusivo a cada nome, de modo que os 10 primeiros resultados ficariam assim: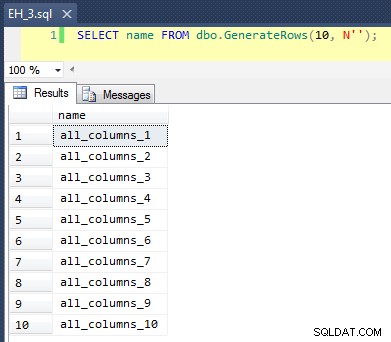
Preencher a tabela com 100.000 linhas foi simples:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Agora, como vamos inserir novos valores exclusivos na tabela, criei um procedimento para realizar uma limpeza no início e no final de cada teste – além de excluir todas as novas linhas que adicionamos, ele também limpará o cache e os buffers. Não é algo que você queira codificar em um procedimento em seu sistema de produção, é claro, mas muito bom para testes de desempenho local.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
Também criei uma tabela de log para acompanhar os horários de início e término de cada teste:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Finalmente, o procedimento armazenado de teste lida com uma variedade de coisas. Temos três métodos diferentes de tratamento de erros, conforme descrito nos marcadores acima:"JustInsert", "Rollback" e "TryCatch"; também temos três tipos de inserção diferentes:(1) todas as inserções são bem-sucedidas (todas as linhas são exclusivas), (2) todas as inserções falham (todas as linhas são duplicadas) e (3) meias inserções são bem-sucedidas (metade das linhas são exclusivas e metade as linhas são duplicadas). Juntamente com isso, há duas abordagens diferentes:verifique a violação antes de tentar a inserção ou apenas vá em frente e deixe o mecanismo determinar se é válido. Achei que isso daria uma boa comparação das diferentes técnicas de tratamento de erros combinadas com diferentes probabilidades de colisões para ver se uma porcentagem alta ou baixa de colisão afetaria significativamente os resultados.
Para esses testes, selecionei 40.000 linhas como meu número total de tentativas de inserção e, no procedimento, executo uma união de 20.000 linhas exclusivas ou não exclusivas com 20.000 outras linhas exclusivas ou não exclusivas. Você pode ver que eu codifiquei as strings de corte no procedimento; observe que em seu sistema esses cortes quase certamente ocorrerão em um local diferente.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Agora podemos chamar este procedimento com vários argumentos para obter o comportamento diferente que procuramos, tentando inserir 40.000 valores (e sabendo, é claro, quantos devem ter sucesso ou falhar em cada caso). Para cada 'método de tratamento de erros' (apenas tente inserir, use begin tran/rollback ou try/catch) e cada tipo de inserção (todos com êxito, meio com êxito e nenhum com êxito), combinado com a verificação ou não da violação primeiro, isso nos dá 18 combinações:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
Depois de executarmos isso (leva cerca de 8 minutos no meu sistema), temos alguns resultados em nosso log. Executei o lote inteiro cinco vezes para ter certeza de que obtivemos médias decentes e para suavizar quaisquer anomalias. Aqui estão os resultados:
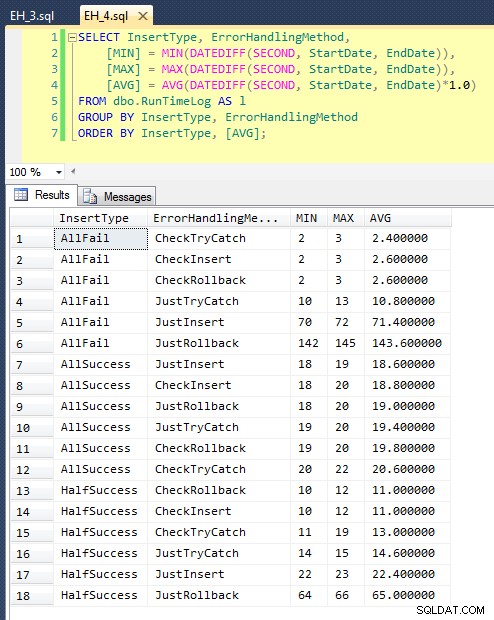
O gráfico que traça todas as durações de uma só vez mostra alguns valores discrepantes sérios:
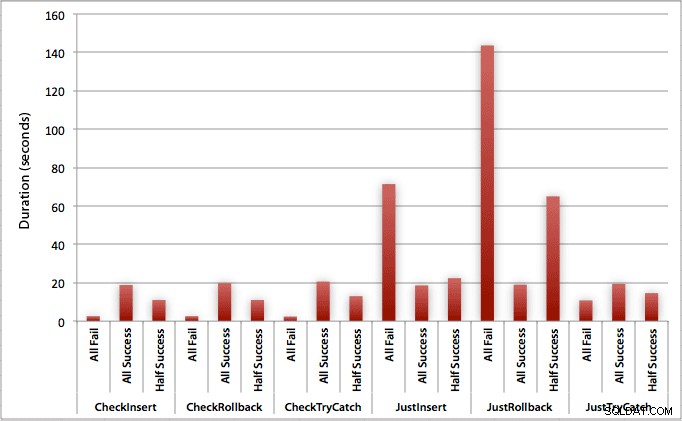
Você pode ver que, nos casos em que esperamos uma alta taxa de falha (neste teste, 100%), iniciar uma transação e reverter é de longe a abordagem menos atraente (3,59 milissegundos por tentativa), enquanto apenas deixamos o mecanismo aumentar um erro é cerca de metade tão ruim (1,785 milissegundos por tentativa). O segundo pior desempenho foi o caso em que iniciamos uma transação e a revertemos, em um cenário em que esperamos que cerca de metade das tentativas falhem (média de 1,625 milissegundos por tentativa). Os 9 casos do lado esquerdo do gráfico, onde estamos verificando a violação primeiro, não ultrapassaram 0,515 milissegundos por tentativa.
Dito isso, os gráficos individuais para cada cenário (alta % de sucesso, alta % de falha e 50-50) realmente mostram o impacto de cada método.
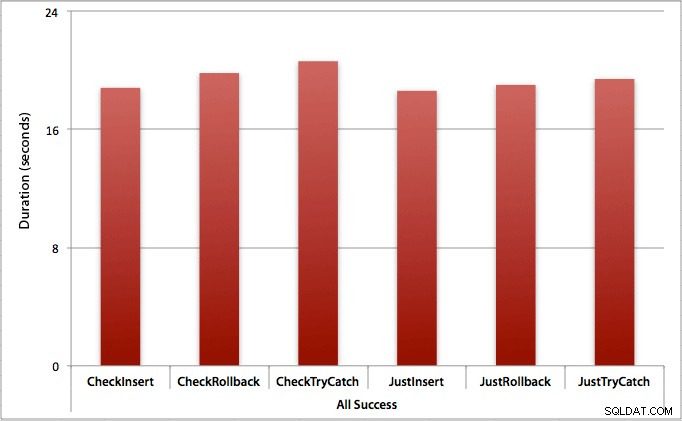
Onde todas as inserções são bem-sucedidas
Nesse caso, vemos que a sobrecarga de verificar a violação primeiro é insignificante, com uma diferença média de 0,7 segundos no lote (ou 125 microssegundos por tentativa de inserção):
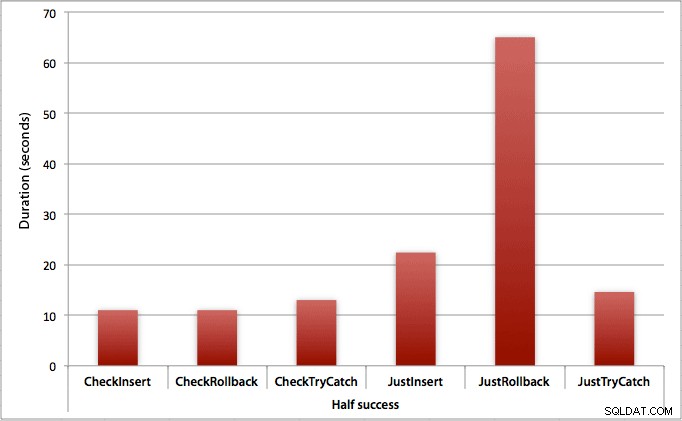
Onde apenas metade das inserções são bem-sucedidas
Quando metade das inserções falham, vemos um grande salto na duração dos métodos de inserção/reversão. O cenário em que iniciamos uma transação e a revertemos é cerca de 6x mais lento em todo o lote quando comparado à primeira verificação (1,625 milissegundos por tentativa versus 0,275 milissegundos por tentativa). Até o método TRY/CATCH é 11% mais rápido quando verificamos primeiro:
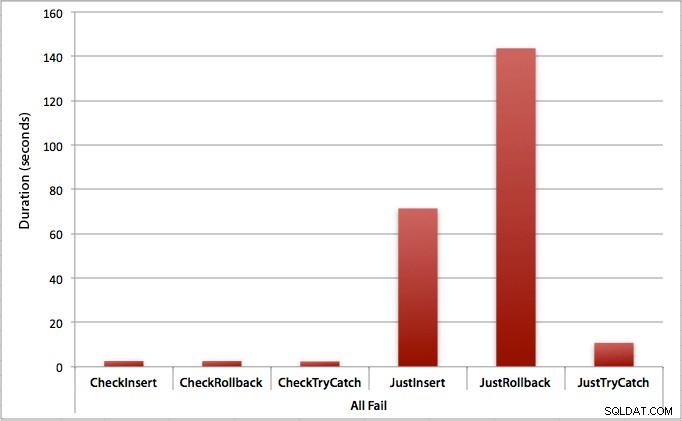
Onde todas as inserções falham
Como você pode esperar, isso mostra o impacto mais pronunciado do tratamento de erros e os benefícios mais óbvios de verificar primeiro. O método de reversão é quase 70 vezes mais lento neste caso quando não verificamos em comparação com quando o fazemos (3,59 milissegundos por tentativa versus 0,065 milissegundos por tentativa):
O que isso nos diz? Se acharmos que teremos uma alta taxa de falhas, ou não tivermos ideia de qual será nossa taxa de falhas potencial, verificar primeiro para evitar violações no mecanismo valerá muito a pena. Mesmo no caso em que sempre temos uma inserção bem-sucedida, o custo de verificar primeiro é marginal e facilmente justificado pelo custo potencial de lidar com erros posteriormente (a menos que sua taxa de falha prevista seja exatamente 0%).
Então, por enquanto, acho que vou me ater à minha teoria de que, em casos simples, faz sentido verificar uma possível violação antes de dizer ao SQL Server para prosseguir e inserir de qualquer maneira. Em um post futuro, examinarei o impacto no desempenho de vários níveis de isolamento, simultaneidade e talvez até algumas outras técnicas de tratamento de erros.
[Como um aparte, escrevi uma versão condensada deste post como uma dica para mssqltips.com em fevereiro.]