Um índice de suporte pode ajudar a evitar a necessidade de classificação explícita no plano de consulta ao otimizar consultas T-SQL envolvendo funções de janela. Por um índice de suporte, Quero dizer um com os elementos de particionamento e ordenação da janela como a chave de índice e o restante das colunas que aparecem na consulta como as colunas incluídas no índice. Costumo me referir a esse padrão de indexação como um POC index como um acrônimo para particionamento , pedido, e cobertura . Naturalmente, se um elemento de particionamento ou ordenação não aparecer na função de janela, você omite essa parte da definição do índice.
Mas e as consultas envolvendo várias funções de janela com diferentes necessidades de ordenação? Da mesma forma, e se outros elementos na consulta, além das funções da janela, também exigirem a organização dos dados de entrada conforme ordenados no plano, como uma cláusula ORDER BY de apresentação? Isso pode resultar em diferentes partes do plano que precisam processar os dados de entrada em ordens diferentes.
Em tais circunstâncias, você normalmente aceita que a classificação explícita seja inevitável no plano. Você pode descobrir que o arranjo sintático de expressões na consulta pode afetar quantos operadores de classificação explícitos que você obtém no plano. Seguindo algumas dicas básicas, às vezes você pode reduzir o número de operadores de classificação explícitos, o que pode, é claro, ter um grande impacto no desempenho da consulta.
Ambiente para demonstrações
Em meus exemplos, usarei o banco de dados de exemplo PerformanceV5. Você pode baixar o código-fonte para criar e preencher este banco de dados aqui.
Executei todos os exemplos no SQL Server 2019 Developer, onde o modo de lote no rowstore está disponível.
Neste artigo, quero me concentrar em dicas relacionadas ao potencial do cálculo da função de janela no plano para contar com dados de entrada ordenados sem exigir uma atividade de classificação extra explícita no plano. Isso é relevante quando o otimizador usa um tratamento de modo de linha serial ou paralelo de funções de janela e ao usar um operador Window Aggregate em modo de lote serial.
No momento, o SQL Server não oferece suporte a uma combinação eficiente de uma entrada de preservação de ordem paralela antes de um operador Window Aggregate de modo de lote paralelo. Portanto, para usar um operador Window Aggregate de modo de lote paralelo, o otimizador precisa injetar um operador Sort de modo de lote paralelo intermediário, mesmo quando a entrada já estiver pré-ordenada.
Para simplificar, você pode evitar o paralelismo em todos os exemplos mostrados neste artigo. Para conseguir isso sem precisar adicionar uma dica a todas as consultas e sem definir uma opção de configuração em todo o servidor, você pode definir a opção de configuração no escopo do banco de dados
MAXDOP para 1 , igual a:USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Lembre-se de defini-lo de volta para 0 depois de terminar de testar os exemplos deste artigo. Vou lembrá-lo no final.
Como alternativa, você pode evitar o paralelismo no nível da sessão com o
DBCC OPTIMIZER_WHATIF não documentado comando, assim:DBCC OPTIMIZER_WHATIF(CPUs, 1);
Para redefinir a opção quando terminar, invoque-a novamente com o valor 0 como o número de CPUs.
Quando você terminar de tentar todos os exemplos deste artigo com o paralelismo desabilitado, recomendo habilitar o paralelismo e tentar todos os exemplos novamente para ver o que muda.
Dicas 1 e 2
Antes de começar com as dicas, vamos primeiro ver um exemplo simples com uma função de janela projetada para se beneficiar de um supp class="border indent shadow orting index.
Considere a seguinte consulta, à qual me referirei como Consulta 1:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Não se preocupe com o fato de que o exemplo é artificial. Não há uma boa razão comercial para calcular um total de IDs de pedidos em execução - esta tabela é decentemente dimensionada com linhas de 1MM, e eu queria mostrar um exemplo simples com uma função de janela comum, como uma que aplica um cálculo total em execução.
Seguindo o esquema de indexação POC, você cria o seguinte índice para dar suporte à consulta:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
O plano para esta consulta é mostrado na Figura 1.
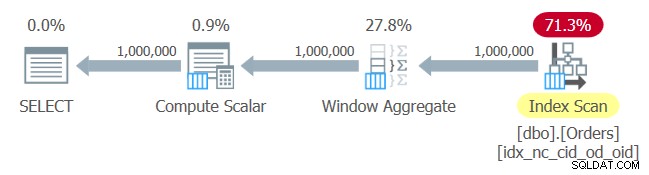 Figura 1:plano para a consulta 1
Figura 1:plano para a consulta 1 Sem surpresas aqui. O plano aplica uma varredura de ordem de índice do índice que você acabou de criar, fornecendo os dados ordenados ao operador Window Aggregate, sem a necessidade de classificação explícita.
Em seguida, considere a seguinte consulta, que envolve várias funções de janela com diferentes necessidades de ordenação, bem como uma cláusula ORDER BY de apresentação:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Vou me referir a essa consulta como Consulta 2. O plano para essa consulta é mostrado na Figura 2.
 Figura 2:plano para consulta 2
Figura 2:plano para consulta 2 Observe que há quatro operadores de classificação no plano.
Se você analisar as várias funções da janela e as necessidades de ordenação da apresentação, descobrirá que existem três necessidades de ordenação distintas:
- custid, orderdate, orderid
- código do pedido
- custid, orderid
Dado que um deles (o primeiro na lista acima) pode ser suportado pelo índice que você criou anteriormente, você esperaria ver apenas duas classificações no plano. Então, por que o plano tem quatro tipos? Parece que o SQL Server não tenta ser muito sofisticado ao reorganizar a ordem de processamento das funções no plano para minimizar as classificações. Ele processa as funções no plano na ordem em que aparecem na consulta. Esse é pelo menos o caso da primeira ocorrência de cada necessidade de ordenação distinta, mas explicarei isso em breve.
Você pode eliminar a necessidade de alguns tipos no plano aplicando as duas práticas simples a seguir:
Dica 1:se você tiver um índice para dar suporte a algumas das funções de janela na consulta, especifique-as primeiro.
Dica 2:se a consulta envolver funções de janela com a mesma necessidade de ordenação que a ordenação de apresentação na consulta, especifique essas funções por último.
Seguindo essas dicas, você reorganiza a ordem de aparência das funções da janela na consulta da seguinte forma:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Vou me referir a essa consulta como Consulta 3. O plano para essa consulta é mostrado na Figura 3.
 Figura 3:plano para a consulta 3
Figura 3:plano para a consulta 3 Como você pode ver, o plano agora tem apenas dois tipos.
Dica 3
O SQL Server não tenta ser muito sofisticado ao reorganizar a ordem de processamento das funções da janela na tentativa de minimizar as classificações no plano. No entanto, é capaz de um certo rearranjo simples. Ele verifica as funções da janela com base na ordem de aparência na consulta e cada vez que detecta uma nova necessidade de ordenação distinta, procura funções de janela adicionais com a mesma necessidade de ordenação e, se as encontrar, as agrupa com a primeira ocorrência. Em alguns casos, pode até usar o mesmo operador para calcular várias funções de janela.
Considere a seguinte consulta como um exemplo:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Vou me referir a essa consulta como Consulta 4. O plano para essa consulta é mostrado na Figura 4.
 Figura 4:planejar a consulta 4
Figura 4:planejar a consulta 4 As funções de janela com as mesmas necessidades de ordenação não são agrupadas na consulta. No entanto, ainda existem apenas dois tipos no plano. Isso ocorre porque o que conta em termos de ordem de processamento no plano é a primeira ocorrência de cada necessidade de pedido distinta. Isso me leva à terceira dica.
Dica 3:Certifique-se de seguir as dicas 1 e 2 para a primeira ocorrência de cada necessidade de pedido distinta. Ocorrências subsequentes da mesma necessidade de pedido, mesmo que não adjacentes, são identificadas e agrupadas com a primeira.
Dicas 4 e 5
Suponha que você queira retornar colunas resultantes de cálculos em janela em uma determinada ordem da esquerda para a direita na saída. Mas e se a ordem não for a mesma que minimizará as classificações no plano?
Por exemplo, suponha que você queira o mesmo resultado produzido pela Consulta 2 em termos de ordem das colunas da esquerda para a direita na saída (ordem das colunas:outras colunas, soma2, soma1, soma3), mas você preferiria ter a mesmo plano como o que você obteve para a Consulta 3 (ordem das colunas:outras colunas, soma1, soma3, soma2), que obteve duas classificações em vez de quatro.
Isso é perfeitamente factível se você estiver familiarizado com a quarta dica.
Dica 4:As recomendações mencionadas acima se aplicam à ordem de aparência das funções de janela no código, mesmo que dentro de uma expressão de tabela nomeada, como CTE ou exibição, e mesmo que a consulta externa retorne as colunas em uma ordem diferente da expressão de tabela nomeada. Portanto, se você precisar retornar colunas em uma determinada ordem na saída e for diferente da ordem ideal em termos de classificação minimizada no plano, siga as dicas em termos de ordem de aparência em uma expressão de tabela nomeada e retorne as colunas na consulta externa na ordem de saída desejada.
A consulta a seguir, que chamarei de Consulta 5, ilustra essa técnica:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; O plano para esta consulta é mostrado na Figura 5.
 Figura 5:planejar a consulta 5
Figura 5:planejar a consulta 5 Você ainda obtém apenas duas classificações no plano, apesar de a ordem das colunas na saída ser:other cols, sum2, sum1, sum3, como na consulta 2.
Uma ressalva para esse truque com a expressão de tabela nomeada é que, se suas colunas na expressão de tabela não forem referenciadas pela consulta externa, elas serão excluídas do plano e, portanto, não contam.
Considere a seguinte consulta, à qual me referirei como Consulta 6:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Aqui, todas as colunas de expressão de tabela são referenciadas pela consulta externa, portanto, a otimização acontece com base na primeira ocorrência distinta de cada necessidade de ordenação na expressão de tabela:
- max1:custid, orderdate, orderid
- max3:id do pedido
- max2:custid, orderid
Isso resulta em um plano com apenas duas classificações, conforme mostrado na Figura 6.
 Figura 6:planejar a consulta 6
Figura 6:planejar a consulta 6 Agora altere apenas a consulta externa removendo as referências a max2, max1, max3, avg2, avg1 e avg3, assim:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Vou me referir a essa consulta como Consulta 7. Os cálculos de max1, max3, max2, avg1, avg3 e avg2 na expressão de tabela são irrelevantes para a consulta externa, portanto, são excluídos. Os cálculos restantes envolvendo funções de janela na expressão de tabela, que são relevantes para a consulta externa, são os de sum2, sum1 e sum3. Infelizmente, eles não aparecem na expressão da tabela na ordem ideal em termos de ordenação minimizada. Como você pode ver no plano para essa consulta, conforme mostrado na Figura 7, existem quatro classificações.
 Figura 7:planejar a consulta 7
Figura 7:planejar a consulta 7 Se você acha que é improvável que tenha colunas na consulta interna às quais não se referirá na consulta externa, pense em visualizações. Cada vez que você consulta uma exibição, pode estar interessado em um subconjunto diferente das colunas. Com isso em mente, a quinta dica pode ajudar na redução de ordenações no plano.
Dica 5:na consulta interna de uma expressão de tabela nomeada, como uma CTE ou exibição, agrupe todas as funções de janela com as mesmas necessidades de ordenação e siga as dicas 1 e 2 na ordem dos grupos de funções.
O código a seguir implementa uma exibição com base nessa recomendação:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Agora consulte a visualização solicitando apenas as colunas de resultados em janela sum2, sum1 e sum3, nesta ordem:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Vou me referir a essa consulta como Consulta 8. Você obtém o plano mostrado na Figura 8 com apenas duas classificações.
 Figura 8:plano para consulta 8
Figura 8:plano para consulta 8 Dica 6
Quando você tem uma consulta com várias funções de janela com várias necessidades de ordenação distintas, o senso comum é que você pode oferecer suporte a apenas uma delas com dados pré-ordenados por meio de um índice. Este é o caso mesmo quando todas as funções de janela possuem os respectivos índices de suporte.
Deixe-me demonstrar isso. Lembre-se de quando você criou o índice idx_nc_cid_od_oid, que pode suportar funções de janela que precisam dos dados ordenados por custid, orderdate, orderid, como a seguinte expressão:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Suponha que, além dessa função de janela, você também precise da seguinte função de janela na mesma consulta:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Esta função de janela se beneficiaria do seguinte índice:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
A consulta a seguir, que chamarei de Consulta 9, invoca ambas as funções de janela:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
O plano para esta consulta é mostrado na Figura 9.
 Figura 9:planejar a consulta 9
Figura 9:planejar a consulta 9 Recebo as seguintes estatísticas de tempo para esta consulta na minha máquina, com resultados descartados no SSMS:
CPU time = 3234 ms, elapsed time = 3354 ms.
Conforme explicado anteriormente, o SQL Server verifica as expressões em janela na ordem de aparecimento na consulta e calcula que pode dar suporte à primeira com uma verificação ordenada do índice idx_nc_cid_od_oid. Mas então ele adiciona um operador Sort ao plano para ordenar os dados como a função da segunda janela precisa. Isso significa que o plano tem escala N log N. Ele não considera o uso do índice idx_nc_cid_oid para dar suporte à segunda função de janela. Você provavelmente está pensando que não pode, mas tente pensar um pouco fora da caixa. Você não poderia calcular cada uma das funções da janela com base em sua respectiva ordem de índice e depois juntar os resultados? Teoricamente, você pode, e dependendo do tamanho dos dados, disponibilidade de indexação e outros recursos disponíveis, a versão de junção às vezes pode ser melhor. O SQL Server não considera essa abordagem, mas você certamente pode implementá-la escrevendo o join você mesmo, assim:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Vou me referir a essa consulta como Consulta 10. O plano para essa consulta é mostrado na Figura 10.
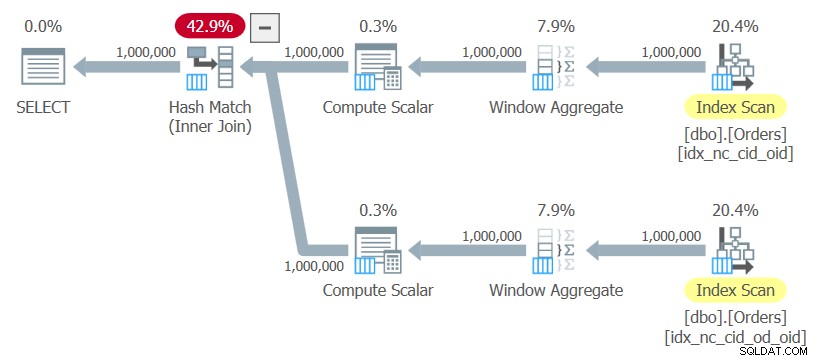 Figura 10:planejar a consulta 10
Figura 10:planejar a consulta 10 O plano usa varreduras ordenadas dos dois índices sem nenhuma classificação explícita, calcula as funções da janela e usa uma junção de hash para unir os resultados. Este plano é dimensionado linearmente em comparação com o anterior, que possui escala N log N.
Recebo as seguintes estatísticas de tempo para esta consulta em minha máquina (novamente com resultados descartados no SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
Para recapitular, aqui está nossa sexta dica.
Dica 6:quando você tiver várias funções de janela com várias necessidades de ordenação distintas e puder oferecer suporte a todas elas com índices, experimente uma versão de junção e compare seu desempenho com a consulta sem a junção.
Limpeza
Se você desativou o paralelismo definindo a opção de configuração do escopo do banco de dados MAXDOP como 1, reative o paralelismo definindo-o como 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Se você usou a opção de sessão não documentada DBCC OPTIMIZER_WHATIF com a opção CPUs definida como 1, reative o paralelismo configurando-a como 0:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Você pode tentar novamente todos os exemplos com paralelismo ativado, se desejar.
Use o código a seguir para limpar os novos índices que você criou:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
E o seguinte código para remover a view:
DROP VIEW IF EXISTS dbo.MyView;
Siga as dicas para minimizar o número de classificações
As funções de janela precisam processar os dados de entrada ordenados. A indexação pode ajudar a eliminar a classificação no plano, mas normalmente apenas para uma necessidade de pedido distinta. As consultas com várias necessidades de pedidos geralmente envolvem alguns tipos em seus planos. No entanto, seguindo algumas dicas, você pode minimizar o número de classificações necessárias. Aqui está um resumo das dicas que mencionei neste artigo:
- Dica 1: Se você tiver um índice para dar suporte a algumas das funções de janela na consulta, especifique-as primeiro.
- Dica 2: Se a consulta envolver funções de janela com a mesma necessidade de ordenação que a ordenação de apresentação na consulta, especifique essas funções por último.
- Dica 3: Certifique-se de seguir as dicas 1 e 2 para a primeira ocorrência de cada necessidade de pedido distinta. As ocorrências subsequentes da mesma necessidade de ordenação, mesmo que não adjacentes, são identificadas e agrupadas com a primeira.
- Dica 4: As recomendações mencionadas acima se aplicam à ordem de aparência das funções de janela no código, mesmo que dentro de uma expressão de tabela nomeada, como uma CTE ou exibição, e mesmo que a consulta externa retorne as colunas em uma ordem diferente da expressão de tabela nomeada. Portanto, se você precisar retornar colunas em uma determinada ordem na saída e for diferente da ordem ideal em termos de classificação minimizada no plano, siga as dicas em termos de ordem de aparência em uma expressão de tabela nomeada e retorne as colunas na consulta externa na ordem de saída desejada.
- Dica 5: Na consulta interna de uma expressão de tabela nomeada, como uma CTE ou exibição, agrupe todas as funções de janela com as mesmas necessidades de ordenação e siga as dicas 1 e 2 na ordem dos grupos de funções.
- Dica 6: Quando você tiver várias funções de janela com várias necessidades de ordenação distintas e puder oferecer suporte a todas elas com índices, tente uma versão de junção e compare seu desempenho com a consulta sem a junção.