Que problemas consideraremos?
Se o servidor notificar que “não há mais espaço na unidade E” – nenhuma análise profunda é necessária. Não consideraremos erros, cuja solução é óbvia no texto da mensagem e para os quais o Google lança imediatamente um link para o MSDN com a solução.
Vamos examinar os problemas que não são óbvios para o Google, como, por exemplo, uma queda repentina no desempenho ou a ausência de conexão. Considere as principais ferramentas para customização e análise. Vamos ver onde os logs e outras informações úteis estão localizadas. Na verdade, tentarei reunir em um artigo todas as informações necessárias para um início rápido.
Primeiro de tudo
Vamos começar com as perguntas mais frequentes e considerá-las separadamente.
Se o seu banco de dados de repente, sem motivo aparente, começou a funcionar lentamente, mas você não mudou nada – primeiro, atualize as estatísticas e reconstrua os índices.
Na Internet, existem muitos métodos como este, exemplos de scripts são fornecidos. Vou assumir que todos esses métodos são para profissionais. Bem, vou descrever a maneira mais simples:você só precisa de um mouse para implementá-lo.
Abreviações
- SSMS é um aplicativo do Microsoft SQL Server Management Studio. A partir da versão 2016, está disponível gratuitamente no site da MS como um aplicativo independente. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler é um aplicativo do “SQL Server Profiler” instalado com SSMS.
- Performance Monitor é um snap-in do painel de controle que permite monitorar os contadores de desempenho, registrar e visualizar o histórico de medições.
Atualização de estatísticas usando um “plano de serviço”:
- executar o SSMS;
- conectar-se a um servidor necessário;
- expandir a árvore no Inspetor de Objetos:Planos de Gerenciamento\Manutenção (Planos de Serviço);
- clique com o botão direito do mouse no nó e selecione "Assistente de plano de manutenção";
- no assistente, marque as tarefas necessárias:reconstruir o índice e atualizar as estatísticas
- você pode marcar as duas tarefas de uma vez ou fazer dois planos de manutenção com uma tarefa em cada (veja as “notas importantes” abaixo);
- além disso, verificamos um banco de dados necessário (ou vários bancos de dados). Fazemos isso para cada tarefa (se forem escolhidas duas tarefas, haverá duas caixas de diálogo com a escolha de um banco de dados);
- Próximo, Próximo, Concluir.
Após essas ações, será criado um “plano de manutenção” (não executado). Você pode executá-lo manualmente clicando com o botão direito do mouse e selecionando “Executar”. Como alternativa, você configura o lançamento via SQL Agent.
Anotações importantes:
- A atualização de estatísticas é uma operação sem bloqueio. Você pode realizá-lo em um modo de trabalho.
- A reconstrução do índice é uma operação de bloqueio. Você pode executá-lo apenas fora do horário de trabalho. Há uma exceção — a edição Enterprise do servidor permite a execução de uma “reconstrução online”. Esta opção pode ser habilitada nas configurações da tarefa. Observe que há uma marca de seleção em todas as edições, mas funciona apenas no Enterprise.
- É claro que essas tarefas devem ser realizadas regularmente. Sugiro uma maneira fácil de determinar com que frequência você faz isso:
– Com os primeiros problemas, execute o plano de manutenção;
– Se ajudou, espere até que os problemas ocorram novamente (geralmente até o próximo fechamento mensal/cálculo de salário/etc. de transações em massa);
– O período resultante de uma operação normal será seu ponto de referência;
– Por exemplo, configure a execução do plano de manutenção duas vezes mais.
O servidor está lento – o que você deve fazer?
Os recursos usados pelo servidor
Como qualquer outro programa, o servidor precisa de tempo de processador, dados no disco, quantidade de RAM e largura de banda da rede.
O Gerenciador de Tarefas o ajudará a avaliar a falta de um determinado recurso na primeira aproximação, não importa o quão terrível possa parecer.
CPU Carregar
Até um estudante pode verificar a utilização no Manager. Só precisamos ter certeza de que, se o processador estiver carregado, é o processo sqlserver.exe.
Se este for o seu caso, você precisa ir para a análise da atividade do usuário para entender o que exatamente causou a carga (veja abaixo).
Disco Loa d
Muitas pessoas apenas olham para a carga da CPU, mas esquecem que o DBMS é um armazenamento de dados. Os volumes de dados estão crescendo, o desempenho do processador está aumentando enquanto a velocidade do HDD é praticamente a mesma. Com SSDs a situação é melhor, mas armazenar terabytes neles é caro.
Acontece que muitas vezes encontro situações em que o sistema de disco se torna o gargalo, em vez da CPU.
Para discos, as seguintes métricas são importantes:
- comprimento médio da fila (operações de E/S pendentes, número);
- velocidade de leitura e gravação (em Mb/s).
A versão do servidor do Gerenciador de Tarefas, como regra (dependendo da versão do sistema), mostra ambos. Caso contrário, execute o snap-in Performance Monitor (monitor do sistema). Estamos interessados nos seguintes contadores:
- Disco físico (lógico)/tempo médio de leitura (gravação)
- Disco físico (lógico)/Comprimento médio da fila de disco
- Disco físico (lógico)/Velocidade do disco
Para obter mais detalhes, você pode ler os manuais do fabricante, por exemplo, aqui:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
Resumidamente:
- A fila não deve exceder 1. Intervalos curtos são permitidos se diminuirem rapidamente. As rajadas podem ser diferentes dependendo do seu sistema. Para um espelho RAID simples de dois HDDs – a fila de mais de 10-20 é um problema. Para uma biblioteca legal com supercaching, vi rajadas de até 600-800 que foram resolvidas instantaneamente sem causar atrasos.
- A taxa de câmbio normal também depende do tipo de sistema de disco. O HDD usual (desktop) transmite a 50-100 MB/s. Uma boa biblioteca de discos – a 500 MB/s e mais. Para pequenas operações aleatórias, a velocidade é menor. Este pode ser seu ponto de referência.
- Esses parâmetros devem ser considerados como um todo. Se sua biblioteca transmite 50 MB/s e uma fila de 50 operações se alinha - obviamente, algo está errado com o hardware. Se a fila se alinhar quando a transmissão estiver próxima do máximo - provavelmente, os discos não são os culpados - eles simplesmente não podem fazer mais - precisamos procurar uma maneira de reduzir a carga.
- A carga deve ser verificada separadamente nos discos (se houver vários) e comparada com a localização dos arquivos do servidor. O Gerenciador de Tarefas pode mostrar os arquivos usados mais ativamente. Isso pode ser usado para garantir que a carga seja causada pelo DBMS.
O que pode causar problemas no sistema de disco:
- problemas com hardware
- cache queimado, desempenho caiu drasticamente;
- o sistema de disco é usado por outra coisa;
- Falta de RAM. Trocando. Сaching decaiu, desempenho caiu (veja a seção sobre RAM abaixo).
- A carga do usuário aumentou. É necessário avaliar o trabalho dos usuários (consulta problemática/nova funcionalidade/aumento do número de usuários/aumento da quantidade de dados/etc).
- Fragmentação de dados do banco de dados (veja a reconstrução do índice acima), fragmentação de arquivos do sistema.
- O sistema de disco atingiu sua capacidade máxima.
No caso da última opção – não jogue fora o hardware de uma vez. Às vezes, você pode obter um pouco mais do sistema se abordar o problema com sabedoria. Verifique a localização dos arquivos do sistema quanto à conformidade com os requisitos recomendados:
- Não misture arquivos do SO com arquivos de dados de banco de dados. Armazene-os em diferentes mídias físicas para que o sistema não concorra com o DBMS para E/S.
- O banco de dados consiste em dois tipos de arquivo:dados (*.mdf, *.ndf) e logs (*.ldf).
Os arquivos de dados, via de regra, são usados principalmente para leitura. Os logs servem para escrita (em que a escrita é consecutiva). Recomenda-se, portanto, armazenar logs e dados em diferentes mídias físicas para que o log não interrompa a leitura dos dados (como regra, a operação de gravação tem precedência sobre a leitura). - O MS SQL pode usar “tabelas temporárias” para processamento de consultas. Eles são armazenados no banco de dados do sistema tempdb. Se você tiver uma carga alta de arquivos desse banco de dados, tente renderizá-lo em uma mídia fisicamente separada.
Resumindo o problema com a localização do arquivo, use o princípio de “dividir e conquistar”. Avalie quais arquivos são acessados e tente distribuí-los para diferentes mídias. Além disso, use os recursos dos sistemas RAID. Por exemplo, as leituras do RAID-5 são mais rápidas do que as gravações – o que é bom para arquivos de dados.
Vamos explorar como recuperar informações sobre o desempenho do usuário:quem faz o quê e quantos recursos são consumidos
Eu dividi as tarefas de auditoria da atividade do usuário nos seguintes grupos:
- Tarefas de análise de uma solicitação específica.
- Tarefas de análise de carga do aplicativo em condições específicas (por exemplo, quando um usuário clica em um botão em um aplicativo de terceiros compatível com o banco de dados).
- Tarefas de análise da situação atual.
Vamos considerar cada um deles em detalhes.
Aviso
A análise de desempenho requer um profundo conhecimento da estrutura e princípios de funcionamento do servidor de banco de dados e do sistema operacional. É por isso que a leitura apenas desses artigos não fará de você um profissional.
Os critérios e contadores considerados em sistemas reais dependem muito uns dos outros. Por exemplo, uma alta carga de HDD geralmente é causada por falta de RAM. Mesmo se você realizar algumas medições, isso não é suficiente para avaliar os problemas de forma razoável.
O objetivo dos artigos é apresentar o essencial em exemplos simples. Você não deve considerar minhas recomendações como um guia. Eu recomendo que você as use como tarefas de treinamento que possam explicar o fluxo de pensamentos.
Espero que você aprenda a racionalizar suas conclusões sobre o desempenho do servidor em números.
Em vez de dizer “servidor lento”, você fornecerá valores específicos de indicadores específicos.
Analisar um P articular R equest
O primeiro ponto é bastante simples, vamos nos debruçar sobre ele brevemente. Vamos considerar algumas questões menos óbvias.
Além dos resultados da consulta, o SSMS permite recuperar informações adicionais sobre a execução da consulta:
- Você pode obter o plano de consulta clicando nos botões "Exibir plano de execução estimado" e "Incluir plano de execução real". A diferença entre eles é que o plano de estimativa é construído sem uma execução de consulta. Assim, serão estimadas as informações sobre o número de linhas processadas. No plano real, haverá dados estimados e reais. Fortes discrepâncias desses valores indicam que as estatísticas não são relevantes. No entanto, a análise do plano é assunto para outro artigo – até agora, não nos aprofundaremos.
- Podemos obter medições dos custos do processador e das operações de disco do servidor. Para isso, é necessário habilitar a opção SET. Você pode fazer isso na caixa de diálogo "Opções de consulta" assim:
Ou com os comandos SET diretos na consulta:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDComo resultado, obteremos dados sobre o tempo gasto na compilação e execução, bem como o número de operações de disco.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Gostaria de chamar sua atenção para o tempo de compilação, leituras lógicas 96 e leituras físicas 5. Ao executar a mesma consulta pela segunda vez e posteriormente, as leituras físicas podem diminuir e a recompilação pode não ser necessária. Devido a este fato, muitas vezes acontece que a consulta é executada mais rapidamente durante a segunda e subsequentes vezes do que na primeira vez. A razão, como você entende, está no cache de dados e planos de consulta compilados.
- O botão «Incluir estatísticas do cliente» exibe as informações sobre a troca de rede, a quantidade de operações executadas e o tempo total de execução, incluindo os custos de troca de rede e processamento por um cliente. O exemplo mostra que leva mais tempo para executar a consulta pela primeira vez:
- No SSMS 2016, existe o botão «Incluir estatísticas de consulta ao vivo». Ele exibe a imagem como no caso do plano de consulta, mas contém os dígitos não aleatórios das linhas processadas, que mudam na tela durante a execução da consulta. A imagem é muito clara - setas piscando e números em execução, você pode ver imediatamente onde o tempo é desperdiçado. O botão também funciona para SQL Server 2014 e posterior.
Resumindo:
- Verifique os custos de CPU usando SET STATISTICS TIME ON.
- Operações de disco:SET STATISTICS IO ON. Não esqueça que a leitura lógica é uma operação de leitura concluída no cache de disco sem acessar fisicamente o sistema de disco. A “leitura física” leva muito mais tempo.
- Avalie o volume de tráfego de rede usando «Incluir estatísticas do cliente».
- Analise o algoritmo de execução da consulta pelo plano de execução usando «Incluir Plano de Execução Real» e «Incluir Estatísticas de Consulta ao Vivo».
Analise a carga do aplicativo
Aqui usaremos o SQL Server Profiler. Após iniciar e conectar ao servidor, é necessário selecionar eventos de log. Para fazer isso, execute a criação de perfil com um modelo de rastreamento padrão. No Geral guia na guia Usar o modelo campo, selecione Padrão (padrão) e clique em Executar .
A maneira mais complicada é adicionar/soltar filtros ou eventos de/para o modelo selecionado. Essas opções podem ser encontradas na segunda guia do menu de diálogo. Para ver toda a gama de eventos e colunas possíveis para selecionar, selecione Mostrar todos os eventos e Mostrar todas as colunas caixas de seleção.

Vamos precisar dos seguintes eventos:
- Procedimentos armazenados \ RPC:Concluído
- TSQL\SQL:BatchCompleted
Esses eventos monitoram todas as chamadas SQL externas para o servidor. Eles aparecem após a conclusão do processamento da consulta. Existem eventos semelhantes que acompanham o início do SQL Server:
- Procedimentos armazenados \ RPC:Iniciando
- TSQL \ SQL:BatchStarting
No entanto, não precisamos desses procedimentos, pois eles não contêm informações sobre os recursos do servidor gastos na execução da consulta. É óbvio que tais informações só estão disponíveis após a conclusão do processo de execução. Assim, as colunas com dados na CPU, Reads, Writes nos eventos *Starting estarão vazias.
Os seguintes eventos também podem nos interessar, no entanto, não os habilitaremos até o momento:
- Stored Procedures \ SP:Starting (*Completed) monitora a chamada interna para o procedimento armazenado não do cliente, mas dentro da solicitação atual ou de outro procedimento.
- Stored Procedures \ SP:StmtStarting (*Completed) rastreia o início de cada instrução dentro do procedimento armazenado. Se houver um ciclo no procedimento, o número de eventos para os comandos no ciclo será igual ao número de iterações no ciclo.
- TSQL \ SQL:StmtStarting (*Completed) monitora o início de cada instrução no lote SQL. Se houver vários comandos em sua consulta, cada um deles conterá um evento. Assim, funciona para os comandos localizados na consulta.
Esses eventos são convenientes para monitorar o processo de execução.
Por C colunas
Quais colunas selecionar são claras no nome do botão. Vamos precisar dos seguintes:
- TextData, BinaryData contém o texto da consulta.
- CPU, leituras, gravações e duração exibem dados de consumo de recursos.
- StartTime, EndTime é a hora de iniciar e terminar o processo de execução. Eles são convenientes para classificação.
Adicione outras colunas com base em suas preferências.
Os Filtros de coluna… botão abre a caixa de diálogo para configurar filtros de eventos. Se você estiver interessado na atividade de um usuário específico, poderá definir o filtro pelo número SID ou nome de usuário. Infelizmente, no caso de conectar o aplicativo através do servidor de aplicativos com o pull de conexões, o monitoramento do usuário específico se torna mais complicado.
Você pode usar filtros para a seleção apenas de consultas complicadas (Duration>X), consultas que causam gravação intensiva (Writes>Y), bem como seleções de conteúdo de consulta, etc.
O que mais precisamos do criador de perfil? Claro, o plano de execução!
É necessário adicionar o evento «Performance \ Showplan XML Statistics Profile» ao rastreamento. Ao executar nossa consulta, obteremos a seguinte imagem:
O texto da consulta:
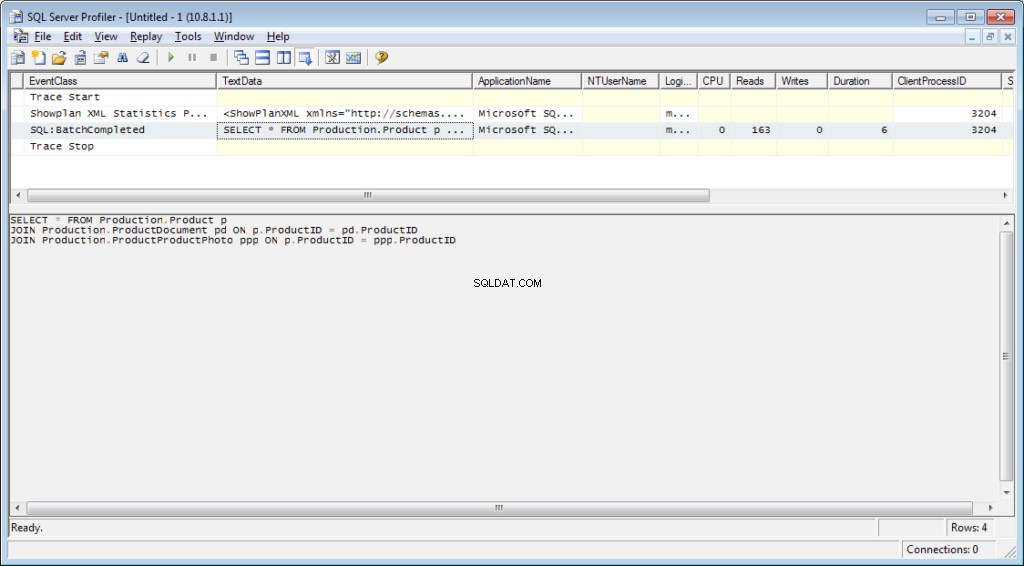
O plano de execução:
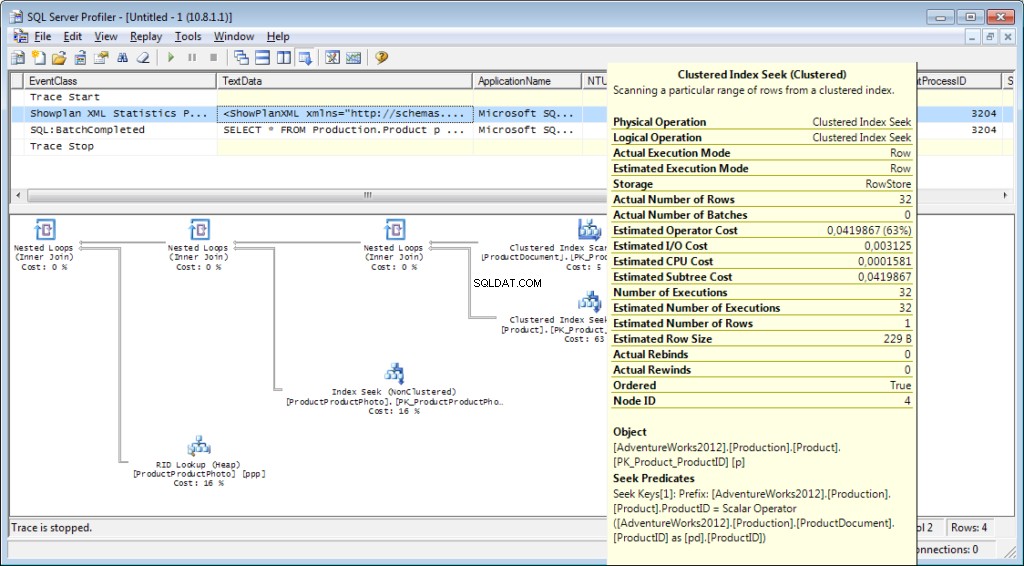
E isso não é tudo
É possível salvar um rastreamento em um arquivo ou tabela de banco de dados. As configurações de rastreamento podem ser armazenadas como um modelo pessoal para uma execução rápida. Você pode executar o rastreamento sem um criador de perfil, simplesmente usando um código T-SQL e os procedimentos sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Você pode encontrar um exemplo aqui. Essa abordagem pode ser útil, por exemplo, para iniciar automaticamente o armazenamento de um rastreamento em um arquivo em um agendamento. Você pode dar uma espiada no criador de perfil para ver como usar esses comandos. Você pode executar dois traces e em um deles acompanhar o que acontece quando o segundo inicia. Verifique se não há filtro pela coluna “ApplicationName” no próprio criador de perfil.
A lista de eventos monitorados pelo criador de perfil é muito grande e não se limita a receber textos de consulta. Existem eventos que rastreiam fullscan, recompilação, autogrow, deadlock e muito mais.
Analisando a atividade do usuário no servidor
Existem diferentes situações. Uma consulta pode travar em 'execução' por um longo tempo e não está claro se ela será concluída ou não. Gostaria de analisar a consulta problemática separadamente; no entanto, devemos primeiro determinar qual é a consulta. É inútil pegá-lo com um criador de perfil - já perdemos o evento inicial e não está claro quanto tempo esperar para que o processo seja concluído.
Vamos descobrir
Você já deve ter ouvido falar sobre o ‘Monitor de Atividades’. Suas edições superiores têm funcionalidades realmente ricas. Como isso pode nos ajudar? O Activity Monitor inclui muitos recursos úteis e interessantes. Obteremos tudo o que precisamos das visualizações e funções do sistema. O próprio monitor é útil porque você pode definir o criador de perfil nele e ver quais consultas ele executa.
Nós vamos precisar:
- dm_exec_sessions fornece informações sobre sessões de usuários conectados. Dentro do nosso artigo, os campos úteis são aqueles que identificam um usuário (login_name, login_time, host_name, program_name, …) e campos com as informações sobre recursos gastos (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests fornece informações sobre as consultas executadas no momento.
- session_id é um identificador da sessão para vincular à visualização anterior.
- start_time é o tempo de execução da visualização.
- comando é um campo que contém um tipo do comando executado. Para consultas do usuário, é select/update/delete/
- sql_handle, statement_start_offset, statement_end_offset fornecem informações para recuperar o texto da consulta:handle, bem como a posição inicial e final no texto da consulta, o que significa a parte que está sendo executada no momento (para o caso em que sua consulta contém vários comandos).
- plan_handle é um identificador do plano gerado.
- blocking_session_id indica o número da sessão que causou o bloqueio se houver bloqueios que impeçam a execução da consulta
- wait_type, wait_time, wait_resource são campos com as informações sobre o motivo e a duração da espera. Para alguns tipos de espera, por exemplo, bloqueio de dados, é necessário indicar adicionalmente um código para o recurso bloqueado.
- percent_complete é a porcentagem de conclusão. Infelizmente, está disponível apenas para comandos com um progresso claramente previsível (por exemplo, backup ou restauração).
- cpu_time, reads, writes, logical_reads, grant_query_memory são custos de recursos.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) são funções de obtenção do texto e do plano de execução. Abaixo, consideraremos um exemplo de seu uso.
- dm_exec_query_stats é uma estatística resumida da execução de consultas. Ele exibe a consulta, o número de execuções e o volume de recursos gastos.
Observações importantes
A lista acima é apenas uma pequena parte. Uma lista completa de todas as visualizações e funções do sistema é descrita na documentação. Além disso, há uma bela imagem mostrando um diagrama de links entre os principais objetos.
O texto da consulta, seu plano e as estatísticas de execução são dados armazenados no cache do procedimento. Eles estão disponíveis durante a execução. Então, a disponibilidade não é garantida e depende da carga do cache. Sim, o cache pode ser limpo manualmente. Às vezes, é recomendado quando os planos de execução “desapareceram”. Ainda assim, há muitas nuances.
O campo “command” não tem sentido para as solicitações do usuário, pois podemos obter o texto completo. No entanto, é muito importante para obter informações sobre os processos do sistema. Via de regra, eles realizam algumas tarefas internas e não possuem o texto SQL. Para esses processos, as informações sobre o comando são a única dica do tipo de atividade.
Nos comentários do artigo anterior, havia uma pergunta sobre em que o servidor está envolvido quando não deveria funcionar. A resposta provavelmente estará no significado deste campo. Na minha prática, o campo “command” sempre forneceu algo bastante compreensível para processos ativos do sistema:autoshrink / autogrow / checkpoint / logwriter / etc.
Como usar
Vamos para a parte prática. Darei vários exemplos de seu uso. As possibilidades do servidor não são limitadas – você pode pensar em seus próprios exemplos.
Exemplo 1. Qual processo consome CPU/leituras/gravações/memória
Primeiro, dê uma olhada nas sessões que consomem mais recursos, por exemplo, CPU. Você pode encontrar essas informações em sys.dm_exec_sessions. No entanto, os dados na CPU, incluindo leituras e gravações, são cumulativos. Isso significa que o número contém o total de todo o tempo de conexão. É claro que o usuário que se conectou há um mês e não foi desconectado terá um valor maior. Isso não significa que eles sobrecarregam o sistema.
Um código com o seguinte algoritmo pode resolver esse problema:
- Faça uma seleção e armazene-a em uma tabela temporária
- Aguarde um pouco
- Faça uma seleção pela segunda vez
- Compare esses resultados. A diferença indicará os custos gastos na etapa 2.
- Por conveniência, a diferença pode ser dividida pela duração da etapa 2 para obter os “custos por segundo” médios.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 Eu uso duas tabelas no código:#tmp – para a primeira seleção, e #tmp1 – para a segunda. Durante a primeira execução, o script cria e preenche #tmp e #tmp1 em um intervalo de um segundo e, em seguida, executa outras tarefas. Nas próximas execuções, o script usa os resultados da execução anterior como base de comparação. Assim, a duração da etapa 2 será igual à duração de sua espera entre as execuções do script.
Tente executá-lo, mesmo no servidor de produção. O script criará apenas 'tabelas temporárias' (disponíveis na sessão atual e excluídas quando desabilitadas) e não possui encadeamento.
Aqueles que não gostam de executar uma consulta no MS SSMS podem envolvê-la em um aplicativo escrito em sua linguagem de programação favorita. Mostrarei como fazer isso no MS Excel sem uma única linha de código.
No menu Dados, conecte-se ao servidor. Se você for solicitado a selecionar uma tabela, selecione uma aleatória. Clique em Avançar e Concluir até ver a caixa de diálogo Importação de dados. Nessa janela, você precisa clicar em Propriedades. Em Propriedades, é necessário substituir um tipo de comando pelo valor SQL e inserir nossa consulta modificada no campo de texto Comando.
Você terá que modificar um pouco a consulta:
- Adicionar «SET NOCOUNT ON»
- Substituir tabelas temporárias por tabelas variáveis
- O atraso durará 1 segundo. Campos com valores médios não são obrigatórios
A consulta modificada para Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Resultado:
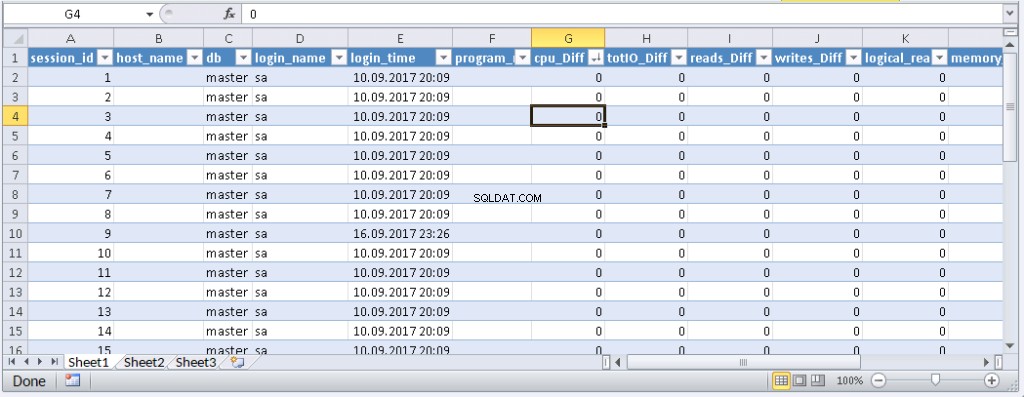
Quando os dados aparecem no Excel, você pode classificá-los conforme necessário. Para atualizar as informações, clique em ‘Atualizar’. Nas configurações da pasta de trabalho, você pode colocar “atualização automática” em um período de tempo especificado e “atualizar no início”. Você pode salvar o arquivo e passá-lo para seus colegas. Assim, criamos uma ferramenta conveniente e simples.
Exemplo 2. Em que uma sessão gasta recursos?
Agora, vamos determinar o que as sessões problemáticas realmente fazem. Para fazer isso, use sys.dm_exec_requests e funções para receber o texto da consulta e o plano de consulta.
A consulta e o plano de execução pelo número da sessão
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Insira o número da sessão na consulta e execute-a. Após a execução, haverá planos na guia Resultados (o primeiro é para toda a consulta e o segundo é para a etapa atual se houver várias etapas na consulta) e o texto da consulta na guia Mensagens. Para visualizar o plano, você precisa clicar no texto que se parece com o URL na linha. O plano será aberto em uma guia separada. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusion
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.



