Como administradores de sistemas e desenvolvedores, passamos muito tempo em um terminal. Então trouxemos o ClusterControl para o terminal com nossa ferramenta de interface de linha de comando chamada s9s. O s9s fornece uma interface fácil para a API ClusterControl RPC v2. Você achará muito útil ao trabalhar com implantações de grande escala, pois a CLI permite que você projete recursos e fluxos de trabalho mais complexos.
Esta postagem de blog mostra como usar o s9s para automatizar o gerenciamento do Galera Cluster for MySQL ou MariaDB, bem como uma configuração simples de replicação mestre-escravo.
Configuração
Você pode encontrar instruções de instalação para seu sistema operacional específico na documentação. O que é importante notar é que, se você usar as ferramentas s9s mais recentes, do GitHub, haverá uma pequena mudança na maneira como você cria um usuário. O comando a seguir funcionará bem:
s9s user --create --generate-key --controller="https://localhost:9501" dbaEm geral, há duas etapas necessárias se você deseja configurar a CLI localmente no host ClusterControl. Primeiro, você precisa criar um usuário e depois fazer algumas alterações no arquivo de configuração - todas as etapas estão incluídas na documentação.
Implantação
Depois que a CLI tiver sido configurada corretamente e tiver acesso SSH aos hosts de banco de dados de destino, você poderá iniciar o processo de implantação. No momento da escrita, você pode usar a CLI para implantar clusters MySQL, MariaDB e PostgreSQL. Vamos começar com um exemplo de como implantar o Percona XtraDB Cluster 5.7. Um único comando é necessário para fazer isso.
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitA última opção “--wait” significa que o comando aguardará até que o trabalho seja concluído, mostrando seu progresso. Você pode ignorá-lo se quiser - nesse caso, o comando s9s retornará imediatamente ao shell após registrar um novo trabalho em cmon. Isso está perfeitamente bem, pois cmon é o processo que lida com o trabalho em si. Você sempre pode verificar o andamento de um trabalho separadamente, usando:
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1Vejamos outro exemplo. Desta vez vamos criar um novo cluster, replicação MySQL:par simples mestre-escravo. Novamente, um único comando é suficiente:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdAgora podemos verificar se ambos os clusters estão funcionando:
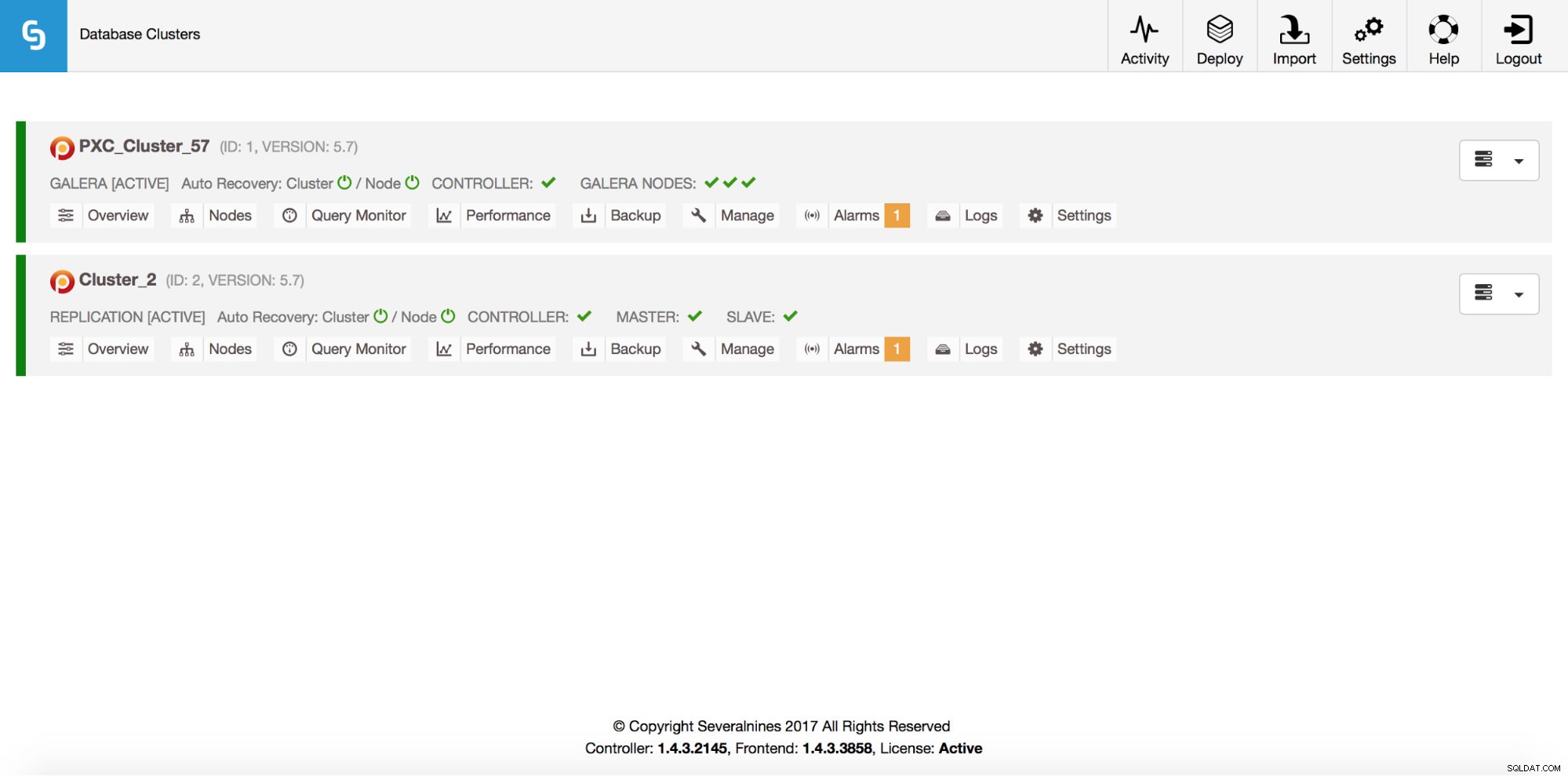
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Claro, tudo isso também é visível através da GUI:
Agora, vamos adicionar um balanceador de carga ProxySQL:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.Desta vez não usamos a opção '--wait' então, se quisermos verificar o progresso, temos que fazer por conta própria. Observe que estamos usando um ID de trabalho que foi retornado pelo comando anterior, portanto, obteremos informações apenas sobre esse trabalho específico:
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7Escalando para fora
Os nós podem ser adicionados ao nosso cluster Galera por meio de um único comando:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8Algo deu errado. Podemos verificar o que exatamente aconteceu:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.Certo, esse IP já é usado para nosso servidor de replicação. Deveríamos ter usado outro IP gratuito. Vamos tentar isso:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9Gerenciando
Digamos que queremos fazer um backup do nosso mestre de replicação. Podemos fazer isso a partir da GUI, mas às vezes podemos precisar integrá-lo a scripts externos. ClusterControl CLI faria um ajuste perfeito para esse caso. Vamos verificar quais clusters temos:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Então, vamos verificar os hosts em nosso cluster de replicação, com cluster ID 2:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningComo podemos ver, existem três hosts que o ClusterControl conhece - dois deles são hosts MySQL (10.0.0.229 e 10.0.0.230), o terceiro é a própria instância do ClusterControl. Vamos imprimir apenas os hosts MySQL relevantes:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3Na coluna “STAT” você pode ver alguns caracteres lá. Para obter mais informações, sugerimos consultar a página de manual dos nós s9s (man s9s-nodes). Aqui vamos apenas resumir as partes mais importantes. O primeiro caractere nos informa sobre o tipo do nó:“s” significa que é um nó MySQL regular, “c” - controlador ClusterControl. O segundo caractere descreve o estado do nó:“o” nos diz que está online. Terceiro personagem - papel do nó. Aqui “M” descreve um mestre e “S” - um escravo enquanto “C” significa controlador. O quarto caractere final nos informa se o nó está em modo de manutenção. “-” significa que não há manutenção programada. Caso contrário, veríamos “M” aqui. Então, a partir desses dados podemos ver que nosso mestre é um host com IP:10.0.0.229. Vamos fazer um backup dele e armazená-lo no controlador.
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okPodemos então verificar se de fato foi concluído ok. Observe a opção “--backup-format” que permite definir quais informações devem ser impressas:
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1Monitoramento
Todos os bancos de dados devem ser monitorados. O ClusterControl usa orientadores para observar algumas das métricas no MySQL e no sistema operacional. Quando uma condição é atendida, uma notificação é enviada. O ClusterControl também fornece um extenso conjunto de gráficos, tanto em tempo real quanto históricos para post-mortem ou planejamento de capacidade. Às vezes, seria ótimo ter acesso a algumas dessas métricas sem precisar passar pela GUI. A CLI do ClusterControl torna isso possível por meio do comando s9s-node. Informações sobre como fazer isso podem ser encontradas na página de manual do s9s-node. Mostraremos alguns exemplos do que você pode fazer com a CLI.
Antes de tudo, vamos dar uma olhada na opção “--node-format” para o comando “s9s node”. Como você pode ver, há muitas opções para imprimir conteúdo interessante.
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningCom o que mostramos aqui, você provavelmente pode imaginar alguns casos de automação. Por exemplo, você pode observar a utilização da CPU dos nós e, se atingir algum limite, pode executar outro trabalho s9s para ativar um novo nó no cluster Galera. Você também pode, por exemplo, monitorar a utilização da memória e enviar alertas se ela ultrapassar algum limite.
A CLI pode fazer mais do que isso. Em primeiro lugar, é possível verificar os gráficos a partir da linha de comando. Claro, eles não são tão ricos em recursos quanto os gráficos na GUI, mas às vezes basta ver um gráfico para encontrar um padrão inesperado e decidir se vale a pena investigar mais.
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231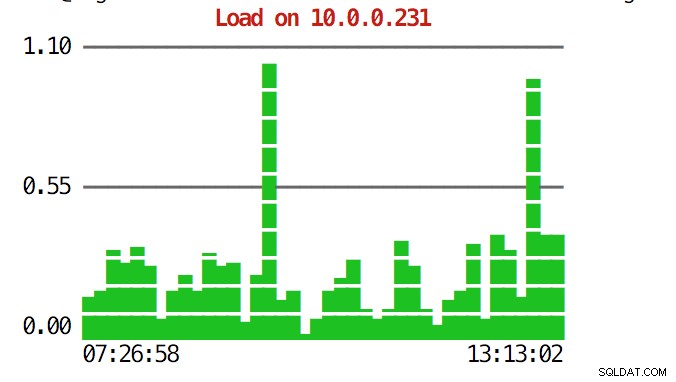
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231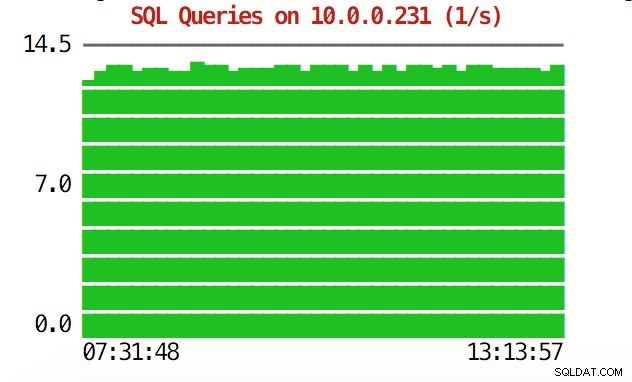
Durante situações de emergência, convém verificar a utilização de recursos no cluster. Você pode criar uma saída tipo top que combina dados de todos os nós do cluster:
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1HQuando você der uma olhada na parte superior, verá estatísticas de CPU e memória agregadas em todo o cluster.
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,Abaixo, você pode encontrar a lista de processos de todos os nós do cluster.
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldIsso pode ser extremamente útil se você precisar descobrir o que está causando a carga e qual nó é o mais afetado.
Esperamos que a ferramenta CLI facilite a integração do ClusterControl com scripts externos e ferramentas de orquestração de infraestrutura. Esperamos que você goste de usar esta ferramenta e, se tiver algum feedback sobre como melhorá-la, sinta-se à vontade para nos informar.