O PostgreSQL 11 foi lançado em 10 de outubro de 2018 e dentro do cronograma, marcando o 23º aniversário do cada vez mais popular banco de dados de código aberto.
Embora uma lista completa de alterações esteja disponível nas notas de lançamento usuais, vale a pena conferir a página renovada da Matriz de Recursos que, assim como a documentação oficial, recebeu uma reformulação desde sua primeira versão, o que facilita a detecção de alterações antes de mergulhar nos detalhes .
Por exemplo, na página Notas de versão, a “ligação de canal para autenticação SCAM” está oculta no Código-fonte, enquanto a matriz o possui na seção Segurança. Para os curiosos aqui está uma captura de tela da interface:
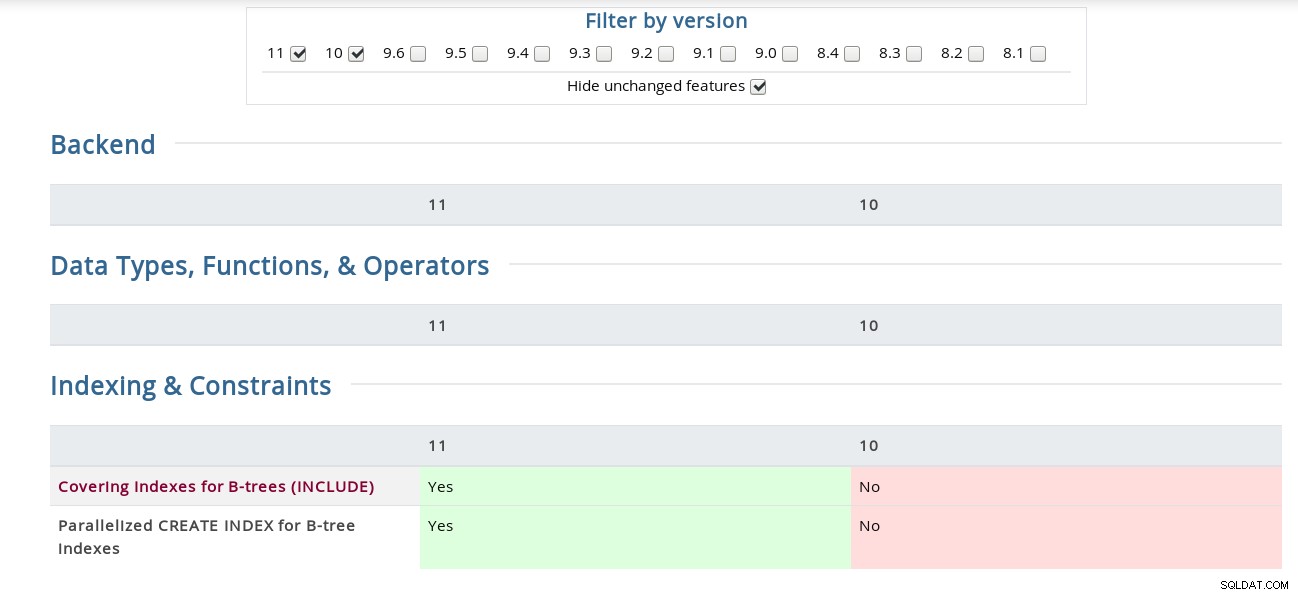 Matriz de recursos do PostgreSQL
Matriz de recursos do PostgreSQL Além disso, a página de Notas de versão do Bucardo Postgres vinculada acima é útil à sua maneira, facilitando a pesquisa de uma palavra-chave em todas as versões.
O que há de novo? Com literalmente centenas de mudanças, passarei pelas diferenças listadas na Matriz de Recursos.
Cobrindo índices para árvores B (INCLUIR)
CREATE INDEX recebeu a cláusula INCLUDE que permite que os índices incluam colunas não chave . Seu caso de uso para consultas idênticas frequentes está bem descrito no commit de Tom Lane de 22 de novembro, que atualiza a documentação de desenvolvimento (o que significa que a documentação atual do PostgreSQL 11 ainda não a possui), portanto, para o texto completo, consulte a seção 11.9. Varreduras somente de índice e índices de cobertura na versão de desenvolvimento.
CREATE INDEX paralelo para índices de árvore B
Como mencionado no nome, esse recurso é implementado apenas para os índices da árvore B, e do log de confirmação de Robert Haas aprendemos que a implementação pode ser refinada no futuro. Conforme observado na documentação do CREATE INDEX, embora os métodos de criação de índice paralelo e simultâneo tirem proveito de várias CPUs, no caso de CONCURRENT apenas a primeira verificação de tabela será executada em paralelo.
Relacionados a este novo recurso estão os parâmetros de configuração maintenance_work_mem e maintenance_parallel_maintenance_workers .
Por fim, o número de trabalhadores paralelos pode ser definido por tabela usando o comando ALTER TABLE e especificando um valor para parallel_workers .
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Compilação Just-In-Time (JIT) para avaliação de expressão e deformação de tupla
Com seu próprio capítulo JIT na documentação, este novo recurso depende do PostgreSQL sendo compilado com suporte LLVM (use pg_config para verificar).
O tópico de JIT no PostgreSQL é complexo o suficiente (veja a referência JIT README na documentação) para exigir um blog dedicado, entretanto, o blog CitusData sobre JIT é uma leitura muito boa para os interessados em se aprofundar no assunto.
Uniões de hash paralelas
Essa melhoria de desempenho para consultas paralelas é o resultado da adição de uma tabela de hash compartilhada, que, como Thomas Munro explica em seu blog Parallel Hash for PostgreSQL, evita particionar a tabela de hash desde que ela caiba em work_mem , que até agora para o PostgreSQL parece ser uma solução melhor do que o algoritmo de partição em primeiro lugar. O mesmo blog descreve os obstáculos da arquitetura do PostgreSQL que o autor teve que superar em sua busca por adicionar paralelização às junções de hash que fala da complexidade do trabalho necessário para implementar esse recurso.
Partição padrão
Esta é uma partição catch all para armazenar linhas que não correspondem a nenhuma outra partição definida. Nos casos em que uma nova partição é adicionada, uma restrição CHECK é recomendada para evitar uma varredura da partição padrão, que pode ser lenta quando a partição padrão contém um grande número de linhas.
O comportamento padrão da partição é explicado na documentação de ALTER TABLE e CREATE TABLE.
Particionamento por uma chave de hash
Também chamado de particionamento de hash, e conforme apontado na mensagem de confirmação, o recurso permite o particionamento de tabelas de forma que as partições mantenham um número semelhante de linhas. Isso é obtido fornecendo um módulo, que no cenário mais simples é recomendado para ser igual ao número de partições, e o restante deve ser diferente para cada partição.
Para obter mais detalhes e um exemplo, consulte a página de documentação do CREATE TABLE.
Suporte para PRIMARY KEY, FOREIGN KEY, índices e gatilhos em tabelas particionadas
O particionamento de tabelas já é um grande passo para melhorar o desempenho de tabelas grandes, e a adição desses recursos aborda as limitações que as tabelas particionadas têm desde o PostgreSQL 10, quando o “particionamento declarativo” de estilo moderno foi introduzido.
O trabalho de Alvaro Herrera está em andamento para permitir que chaves estrangeiras façam referência a chaves primárias e está programado para a próxima versão principal do PostgreSQL 12.
ATUALIZAÇÃO em uma chave de partição
Conforme explicado no log de confirmação do patch, esta atualização evita que o PostgreSQL gere um erro quando uma atualização na chave de partição invalida uma linha e, em vez disso, a linha será movida para uma partição apropriada.
Vinculação de canal para autenticação SCRAM
Esta é uma medida de segurança que visa prevenir ataques man-in-the-middle na autenticação SASL e é detalhadamente detalhada no blog do autor. O recurso requer um mínimo de OpenSSL 1.0.2.
CREATE PROCEDURE and CALL Syntax for SQL Stored Procedures
PostgreSQL tem CREATE FUNCTION desde 1996, com a versão 1.0.1 , no entanto, as funções não podem manipular transações. Conforme mencionado na documentação, o comando CREATE PROCEDURE não é totalmente compatível com o padrão SQL.
Observação:fique atento a um próximo blog que se aprofunda nesse recurso
Conclusão
As principais atualizações do PostgreSQL 11 se concentram em melhorias de desempenho por meio de execução paralela, particionamento e compilação Just-In-Time. Os procedimentos armazenados permitem o controle total da transação e podem ser escritos em uma variedade de linguagens PL.