Introdução
Armazenar dados é uma coisa; armazenamento significativo, útil, correto dados é outra bem diferente. Embora o significado e a utilidade sejam qualidades subjetivas, pelo menos a correção pode ser definida e imposta logicamente. Os tipos já garantem que os números sejam números e as datas sejam datas, mas não podem garantir que o peso ou a distância sejam números positivos ou impedir que os intervalos de datas se sobreponham. Restrições de tupla, tabela e banco de dados aplicam regras aos dados armazenados e rejeitam valores ou combinações de valores que não são aprovados.
As restrições não tornam outras técnicas de validação de entrada inúteis de forma alguma, mesmo quando testam as mesmas asserções. O tempo gasto tentando e não armazenando dados inválidos é tempo perdido. Mensagens de violação, como
assert em sistemas e linguagens de programação de aplicativos, apenas revela o primeiro problema com o primeiro registro candidato com muito mais detalhes do que qualquer pessoa não envolvida imediatamente com as necessidades do banco de dados. Mas no que diz respeito à exatidão dos dados, as restrições são lei, para o bem ou para o mal; qualquer outra coisa é conselho. Em Tuplas:Não Nulo, Padrão e Verificado
As restrições não nulas são a categoria mais simples. Uma tupla deve ter um valor para o atributo restrito, ou dito de outra forma, o conjunto de valores permitidos para a coluna não inclui mais o conjunto vazio. Nenhum valor significa que não há tupla:a inserção ou atualização é rejeitada.
Proteger contra valores nulos é tão fácil quanto declarar
column_name COLUMN_TYPE NOT NULL em CREATE TABLE ou ADD COLUMN . Valores nulos causam categorias inteiras de problemas entre o banco de dados e os usuários finais, portanto, definir reflexivamente restrições não nulas em qualquer coluna sem um bom motivo para permitir nulos é um bom hábito. O fornecimento de um valor padrão se nada for especificado (por omissão ou um
NULL explícito ) em uma inserção ou atualização nem sempre é considerada uma restrição, pois os registros candidatos são modificados e armazenados em vez de rejeitados. Em muitos SGBDs, os valores padrão podem ser gerados por uma função, embora o MySQL não permita funções definidas pelo usuário para esta finalidade. Qualquer outra regra de validação que dependa apenas dos valores dentro de uma única tupla pode ser implementada como um
CHECK limitação. De certa forma, NOT NULL em si é um atalho para CHECK (column_name IS NOT NULL); a mensagem de erro recebida em violação faz a maior diferença. CHECK , no entanto, pode aplicar e impor a verdade de qualquer predicado booleano sobre uma única tupla. Por exemplo, uma tabela que armazena localizações geográficas deve CHECK (latitude >= -90 AND latitude < 90) , e da mesma forma para longitude entre -180 e 180 -- ou, se disponível, use e valide uma GEOGRAPHY tipo de dados. Nas tabelas:exclusivo e exclusão
As restrições de nível de tabela testam as tuplas umas contra as outras. Em uma restrição exclusiva, apenas um registro pode ter um determinado conjunto de valores para as colunas restritas. A nulidade pode causar problemas aqui, pois
NULL nunca é igual a qualquer outra coisa, até e incluindo NULL em si. Uma restrição exclusiva em (batman, robin) portanto, permite cópias infinitas de qualquer Batman sem Robin. As restrições de exclusão são suportadas apenas no PostgreSQL e no DB2, mas preenchem um nicho muito útil:elas podem evitar sobreposições. Especifique os campos restritos e as operações pelas quais cada um será avaliado, e um novo registro só será aceito se nenhum registro existente for comparado com sucesso com cada campo e operação. Por exemplo, um
schedules tabela pode ser configurada para rejeitar conflitos:-- text, int, etc. comparisons in exclusion constraints require this-- Postgres extensionCREATE EXTENSION btree_gist;CREATE TABLE schedules ( schedule_id SERIAL NOT NULL PRIMARY KEY, room_number TEXT NOT NULL, -- a range of TIMESTAMP WITH TIME ZONE provides both start and end duration TSTZRANGE, -- table-level constraints imply an index, since otherwise they'd -- have to search the entire table to validate a candidate record; -- GiST (generalized search tree) indexes are usually used in -- Postgres EXCLUDE USING GIST ( room_number WITH =, duration WITH && ));INSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- the same time in a different room: acceptedINSERT INTO schedules (room_number, duration)VALUES ('32B', '[2020-08-20T10:00:00Z,2020-08-20T11:00:00Z)');-- a half-hour overlap for an already-scheduled room: rejectedINSERT INTO schedules (room_number, duration)VALUES ('32A', '[2020-08-20T10:30:00Z,2020-08-20T11:30:00Z)');
Operações de upsert como
ON CONFLICT do PostgreSQL cláusula ou ON DUPLICATE KEY UPDATE do MySQL use uma restrição de nível de tabela para detectar conflitos. E como restrições não nulas podem ser expressas como CHECK restrições, uma restrição única pode ser expressa como uma restrição de exclusão na igualdade. A chave primária
As restrições exclusivas têm um caso especial particularmente útil. Com uma restrição adicional não nula na coluna ou colunas exclusivas, cada registro na tabela pode ser identificado individualmente por seus valores para as colunas restritas, que são chamadas coletivamente de chave . Várias chaves candidatas podem coexistir em uma tabela, como
users às vezes ainda tendo um email exclusivo e não nulo distinto s e username s; mas declarar uma chave primária estabelece um único critério pelo qual os registros são conhecidos publicamente e exclusivamente. Alguns RDBMSs até organizam linhas nas páginas pela chave primária, chamada para esse propósito de índice clusterizado , para tornar a pesquisa por valores de chave primária o mais rápido possível. Existem dois tipos de chave primária. Uma chave natural é definida em uma coluna ou colunas "naturalmente" incluídas nos dados da tabela, enquanto uma chave substituta ou sintética é inventada apenas com o objetivo de se tornar a chave. Chaves naturais requerem cuidado - mais coisas podem mudar do que os designers de banco de dados geralmente acreditam, de nomes a esquemas de numeração. Uma tabela de pesquisa contendo nomes de países e regiões pode usar seus respectivos códigos ISO 3166 como uma chave primária natural segura, mas um
users tabela com uma chave natural baseada em valores mutáveis como nomes ou endereços de e-mail convida a problemas. Em caso de dúvida, crie uma chave substituta. Se uma chave natural abrange várias colunas, uma chave substituta deve sempre ser considerada pelo menos, pois as chaves de várias colunas exigem mais esforço para gerenciar. Se a chave natural for adequada, no entanto, as colunas devem ser ordenadas em especificidade crescente, assim como nos índices:código do país então código de região, e não o inverso.
A chave substituta tem sido historicamente uma única coluna inteira, ou
BIGINT onde bilhões serão eventualmente atribuídos. Bancos de dados relacionais podem preencher automaticamente chaves substitutas com o próximo inteiro em uma série, um recurso geralmente chamado de SERIAL ou IDENTITY . Um contador numérico de incremento automático tem suas desvantagens:adicionar registros com chaves pré-geradas pode causar conflitos e, se os valores sequenciais forem expostos aos usuários, é fácil para eles adivinhar quais outras chaves válidas podem ser. Identificadores Universalmente Exclusivos, ou UUIDs, evitam esses pontos fracos e se tornaram uma escolha comum para chaves substitutas, embora também sejam muito maiores na página do que um simples número. Os tipos de UUID v1 (baseado em endereço MAC) e v4 (pseudorandom) são os mais usados.
No banco de dados:chaves estrangeiras
Os bancos de dados relacionais implementam apenas uma classe de restrição de várias tabelas, o
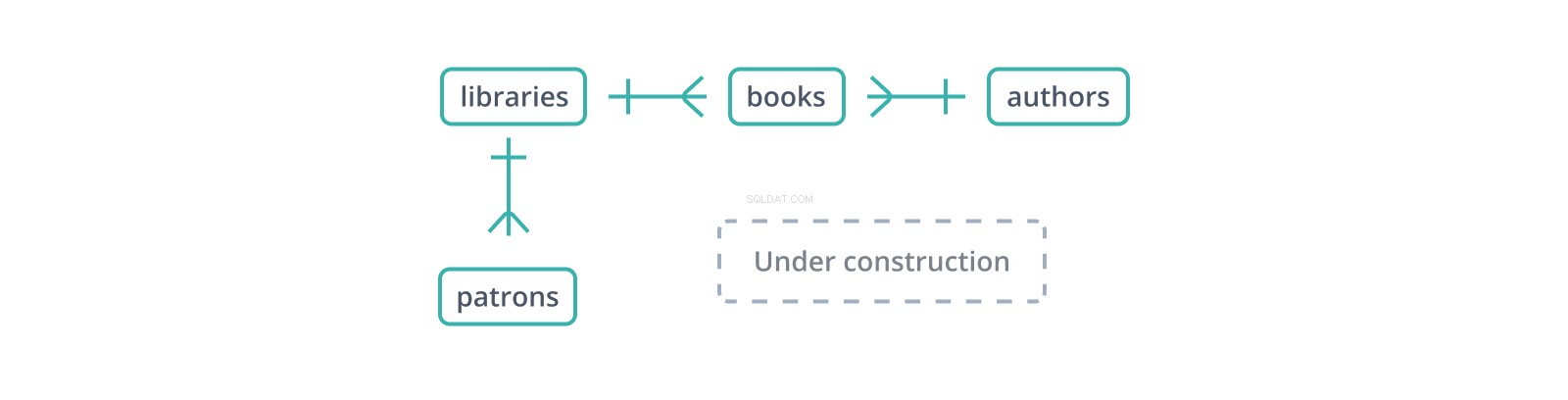
Este "diagrama entidade-relacionamento" informal ou ERD mostra o início de um esquema para um banco de dados de bibliotecas e suas coleções e usuários. Cada aresta representa uma relação entre as tabelas que ela conecta. O | glifo indica um único registro em seu lado, enquanto o glifo "pé de galinha" representa vários:uma biblioteca contém muitos livros e tem muitos frequentadores.
Uma chave estrangeira é uma cópia da chave primária de outra tabela, coluna por coluna (um ponto a favor das chaves substitutas:apenas uma coluna para copiar e referenciar), com valores ligando registros nesta tabela a registros "pais" nela. No esquema acima, os
books tabela mantém um library_id chave estrangeira para libraries , que contém livros e um author_id para authors , que os escreve. Mas o que acontece se um livro for inserido com um author_id que não existe em authors ? Se a chave estrangeira não for restrita - ou seja, é apenas outra coluna ou colunas - um livro pode ter um autor que não existe. Este é um problema:se alguém tentar seguir o link entre
books e authors , eles acabam em lugar nenhum. Se authors.author_id é um número inteiro serial, também existe a possibilidade de que ninguém perceba até que o espúrio author_id é eventualmente atribuído, e você acaba com uma cópia específica de Don Quixote atribuído primeiro a ninguém conhecido e depois a Pierre Menard, com Miguel Cervantes longe de ser encontrado. Restringir a chave estrangeira não pode impedir que um livro seja atribuído erroneamente se o
author_id incorreto apontar para um registro existente em authors , portanto, outras verificações e testes permanecem importantes. No entanto, o conjunto de valores de chave estrangeira existentes é quase sempre um pequeno subconjunto dos possíveis valores de chave estrangeira, portanto, as restrições de chave estrangeira capturarão e impedirão a maioria dos valores errados. Com uma restrição de chave estrangeira, o Quixote com um autor inexistente será rejeitado em vez de registrado. 


