Você deve realmente olhar para Normalização de banco de dados e primeiro normalize sua estrutura adicionando uma tabela de junção e mantenha uma relação de tablec cada relação armazenada em tablec será armazenada em uma nova tabela de junção, mas não como uma lista separada por vírgulas, cada linha conterá id de c e um id de usuário por linha, se você não pode alterar seu esquema você pode usar
find_in_set para encontrar valores no conjunto select *
from tblC c
JOIN tblB b
ON (find_in_set(b.userid,c.userids) > 0)
where c.nname="new1"
Ver demonstração
Editar para normalizar esquema
Eu removi
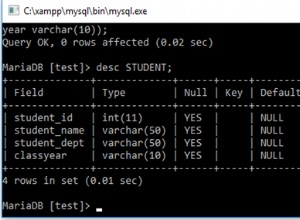
userids coluna do seu tblC e, em vez disso, criei uma nova tabela de junção como tblC_user com 2 colunas c_id isso será relacionado à coluna id de tblC e o segundo userid para armazenar usuários de relações de usuário para tblC veja o esquema de amostra para tblC CREATE TABLE if not exists tblC
(
id int(11) NOT NULL auto_increment ,
nname varchar(255),
PRIMARY KEY (id)
);
INSERT INTO tblC (id, nname) VALUES
('1', 'new1'),
('2', 'new2'),
('3', 'new3'),
('4', 'new4'),
('5', 'new5');
E aqui está sua tabela de junção como
tblC_user CREATE TABLE if not exists tblC_user
(
c_id int,
userid int
);
INSERT INTO tblC_user (c_id,userid) VALUES
('1','1'),
('1','2'),
('2','1'),
('2','3'),
('3','1'),
('3','4'),
('4','3'),
('4','2'),
('5','5'),
('5','2');
Acima, se você notar que não armazenei nenhuma relação separada por vírgula, cada relação de usuário para
tblC é armazenado em uma nova linha, para você, o conjunto de resultados em questão eu usei a tabela de junção na junção e a nova consulta será como abaixo select *
from tblC c
join tblC_user cu on(c.id = cu.c_id)
join tblB b on (b.userid = cu.userid)
where c.nname="new1"
Demonstração 2
Agora, a consulta acima pode ser otimizada usando índices, você pode manter relações em cascata facilmente