Sua pergunta é realmente impreciso. Por favor, siga as sugestões do @RiggsFolly e leia as referências sobre como fazer uma boa pergunta.
Além disso, como sugerido por @DuduMarkovitz, você deve começar simplificando o problema e limpando seus dados. Alguns recursos para você começar:
- Tutorial básico de processamento de texto por Matt Deny
- Manuseando e processando strings em R por Gaston Sanchez
Quando estiver satisfeito com os resultados, você poderá identificar um grupo para cada
Var1 entrada (isso irá ajudá-lo no caminho para realizar mais análises/manipulações em entradas semelhantes) Isso pode ser feito de muitas maneiras diferentes, mas conforme mencionado por @GordonLinoff, uma possibilidade é a Distância de Levenshtein. Observação :para 50 mil entradas, o resultado não será 100% preciso, pois nem sempre categorizar os termos no grupo apropriado, mas isso deve reduzir consideravelmente os esforços manuais.
Em R, você pode fazer isso usando
adist()
Usando seus dados de exemplo:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
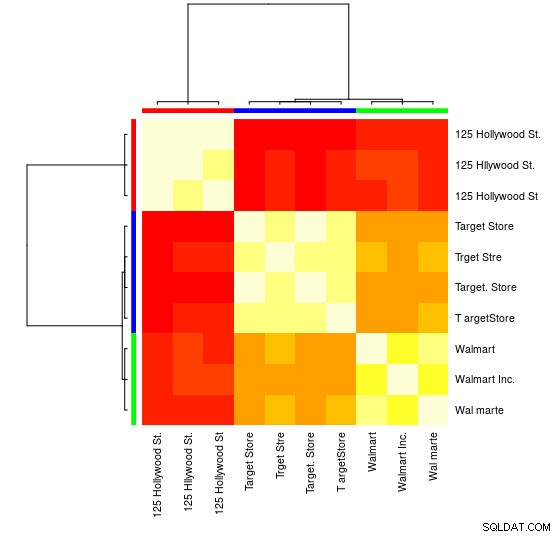
Para esta pequena amostra, você pode ver os 3 grupos distintos (os agrupamentos de valores baixos de Distância de Levensthein) e pode atribuí-los facilmente manualmente, mas para conjuntos maiores, você provavelmente precisará de um algoritmo de agrupamento.
Já indiquei você nos comentários para um dos meus resposta anterior mostrando como fazer isso usando
hclust() e o método de variação mínima do Ward, mas acho que aqui seria melhor usar outras técnicas (um dos meus recursos favoritos sobre o tópico para uma visão geral rápida de alguns dos métodos mais usados em R é este resposta detalhada
) Aqui está um exemplo usando clustering de propagação de afinidade:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Você encontrará no objeto APResult
d_ap os elementos associados a cada cluster e o número ótimo de clusters, neste caso:3. > example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Você também pode ver uma representação visual:
> heatmap(d_ap, margins = c(10, 10))
Em seguida, você pode realizar outras manipulações para cada grupo. Como exemplo, aqui eu uso
hunspell para pesquisar cada palavra separada de Var1 em um dicionário en_US para erros de ortografia e tente encontrar, dentro de cada group , que id não tem erros de ortografia (potential_id ) library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Que dá:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Observação :Aqui, como não realizamos nenhum processamento de texto, os resultados não são muito conclusivos, mas você entendeu.
Dados
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)