Duas perguntas - as descrições são padrão (as descrições não mudam) ou são inseridas por um usuário? Se forem padrão, adicione uma coluna que seja um número inteiro e faça uma comparação nessa coluna.
Se for digitado pelo usuário, seu trabalho é mais complicado, pois você está procurando por algo que é uma pesquisa mais difusa. Eu usei um algoritmo de pesquisa bi-gram para classificar a semelhança entre duas strings, mas isso não pode ser feito diretamente no mySQL.
Em vez de uma pesquisa difusa, você pode usar LIKE, mas sua eficiência é limitada a fazer varreduras de tabela se você acabar colocando o '%' no início do termo de pesquisa. Além disso, isso implica que você pode obter uma correspondência na parte da substring que você escolher, o que significa que você precisa conhecer a substring com antecedência.
Eu ficaria feliz em elaborar mais uma vez que eu saiba o que você está tentando fazer.
EDIT1:Ok, dada a sua elaboração, você precisará fazer uma pesquisa de estilo difuso como mencionei. Eu uso um método bi-gram, que envolve pegar cada entrada feita pelo usuário e dividi-la em pedaços de 2 ou 3 caracteres. Em seguida, armazeno cada um desses pedaços em outra tabela com cada entrada digitada de volta à descrição real.
Exemplo:
Descrição1:"Uma corrida rápida para a frente"Descrição2:"Uma corrida curta para a frente"
Se você quebrar cada um em 2 pedaços de caracteres - 'A', 'f', 'fa', 'as','st'.....
Então você pode comparar o número de pedaços de 2 caracteres que correspondem a ambas as strings e obter uma "pontuação" que conotará precisão ou semelhança entre os dois.
Dado que não sei qual linguagem de desenvolvimento você está usando, deixarei a implementação de fora, mas isso é algo que precisará ser feito não explicitamente no mySQL.
Ou a alternativa preguiçosa seria usar um serviço de pesquisa em nuvem como o da Amazon, que fornecerá pesquisa com base nos termos que você fornecer ... não tenho certeza se eles permitem que você adicione continuamente novas descrições a serem consideradas e, dependendo do seu aplicativo, pode ser um pouco caro (IMHO).
R
Para outra postagem do SO sobre a implementação do bigram - veja esta SO bigram / fuzzy search
--- Atualização por elaboração do questionador---
Primeiro, suponho que você tenha lido a teoria nos links que forneci. multar)
Ok, então o método bigrama funciona bem em fazer/comparar arrays na memória apenas se as possíveis correspondências forem relativamente pequenas, caso contrário, ele sofre com um desempenho de varredura de tabela como uma tabela mysql sem índices rapidamente. Então, você vai usar os pontos fortes do banco de dados para ajudar a fazer a indexação para você.
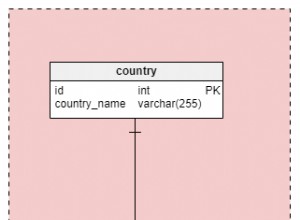
O que você precisa é de uma tabela para conter os "termos" inseridos pelo usuário ou o texto que você deseja comparar. A forma mais simples é uma tabela com duas colunas, uma é um inteiro único de incremento automático que será indexado, chamaremos hd_id abaixo, a segunda é um varchar(255) se as strings forem muito curtas, ou TEXT se puderem ficar longo - você pode nomear isso como quiser.
Então, você precisará fazer outra tabela que tenha pelo menos TRÊS colunas - uma para a coluna de referência de volta à coluna auto-incrementada da outra tabela (chamaremos isso de hd_id abaixo), a segunda seria um varchar() de digamos 5 caracteres no máximo (isso conterá seus pedaços de bigrama) que chamaremos de "bigrama" abaixo, e o terceiro uma coluna de incremento automático chamada b_id abaixo. Esta tabela conterá todos os bigramas para a entrada de cada usuário e vinculará à entrada geral. Você desejará indexar a coluna varchar sozinha (ou primeiro em ordem em um índice composto).
Agora, toda vez que um usuário insere um termo que você deseja pesquisar, você precisa inserir o termo na primeira tabela, dissecar o termo em bigramas e inserir cada parte na segunda tabela usando a referência de volta ao termo geral na primeira tabela para completar a relação. Dessa forma, você está fazendo a dissecação em PHP, mas deixando o mySQL ou qualquer banco de dados fazer a otimização do índice para você. Pode ajudar na fase de bigrama armazenar o número de bigramas feitos na tabela 1 para a fase de cálculo. Abaixo está um código em PHP para dar uma ideia de como criar os bigramas:
// split the string into len-character segments and store seperately in array slots
function get_bigrams($theString,$len)
{
$s=strtolower($theString);
$v=array();
$slength=strlen($s)-($len-1); // we stop short of $len-1 so we don't make short chunks as we run out of characters
for($m=0;$m<$slength;$m++)
{
$v[]=substr($s,$m,$len);
}
return $v;
}
Não se preocupe com espaços nas strings - eles são realmente muito úteis se você pensar em pesquisa difusa.
Então você pega os bigramas, os insere em uma tabela, vinculado ao texto geral na tabela 1 via e coluna indexada... e agora?
Agora, sempre que você pesquisar um termo como "Meu termo favorito para pesquisar" - você pode usar a função php para transformá-lo em uma matriz de bigramas. Você então usa isso para criar a parte IN (..) de uma instrução SQL em sua tabela de bigramas(2). Abaixo segue um exemplo:
select count(b_id) as matches,a.hd_id,description, from table2 a
inner join table1 b on (a.hd_id=b.hd_id)
where bigram in (" . $sqlstr . ")
group by hd_id order by matches desc limit X
Deixei o $sqlstr como uma referência de string PHP - você pode construir isso você mesmo como uma lista separada por vírgulas da função bigrama usando implode ou qualquer outra coisa na matriz retornada de get_bigrams ou parametrizar se quiser também.
Se feita corretamente, a consulta acima retorna os termos de pesquisa difusos mais próximos, dependendo do comprimento do bigrama escolhido. O comprimento escolhido tem uma eficácia relativa com base no comprimento esperado das strings de pesquisa gerais.
Por último - a consulta acima, apenas fornece uma classificação de correspondência difusa. Você pode brincar e melhorar comparando não apenas as correspondências, mas as correspondências versus a contagem geral de bigramas, o que ajudará a eliminar o viés de cadeias de pesquisa longas em comparação com cadeias curtas. Eu parei aqui porque neste momento se torna muito mais específico de aplicação.
Espero que isto ajude!
R