Selecionar linhas aleatórias é sempre complicado e não há soluções perfeitas que não envolvam algum compromisso. Ou comprometa o desempenho, ou comprometa até mesmo a distribuição aleatória, ou comprometa a chance de selecionar duplicatas, etc.
Como @JakeGould menciona, qualquer solução com
ORDER BY RAND() não escala bem. À medida que o número de linhas em sua tabela aumenta, o custo de classificar a tabela inteira em uma classificação de arquivos fica cada vez pior. Jake está correto ao dizer que a consulta não pode ser armazenada em cache quando a ordem de classificação é aleatória. Mas eu não me importo tanto com isso porque eu costumo desabilitar o cache de consulta de qualquer maneira (ele tem seus próprios problemas de escalabilidade). Aqui está uma solução para pré-randomizar as linhas na tabela, criando uma coluna rownum e atribuindo valores consecutivos exclusivos:
ALTER TABLE products ADD COLUMN rownum INT UNSIGNED, ADD KEY (rownum);
SET @rownum := 0;
UPDATE products SET rownum = (@rownum:example@sqldat.com+1) ORDER BY RAND();
Agora você pode obter uma linha aleatória por uma pesquisa de índice, sem Ordenação:
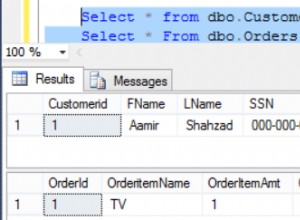
SELECT * FROM products WHERE rownum = 1;
Ou você pode obter a próxima linha aleatória:
SELECT * FROM products WHERE rownum = 2;
Ou você pode obter 10 linhas aleatórias de cada vez, ou qualquer outro número que desejar, sem duplicatas:
SELECT * FROM products WHERE rownum BETWEEN 11 and 20;
Você pode re-aleatorizar sempre que quiser:
SET @rownum := 0;
UPDATE products SET rownum = (@rownum:example@sqldat.com+1) ORDER BY RAND();
Ainda é caro fazer a classificação aleatória, mas agora você não precisa fazer isso em todas as consultas SELECT. Você pode fazê-lo em um horário, espero que em horários fora de pico.