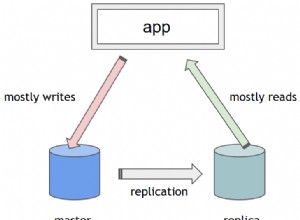
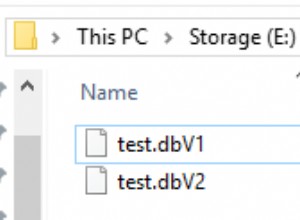
Se eu fosse você, preferiria comparar os descritores no código, em vez de no SQL. SQL não foi feito para isso. Eu faria o seguinte:-
1. Pre-load N descriptors from SQL onto memory.
2. Compare distances to query descriptor, descriptor by descriptor.
3. If distance<threshold, push to possiblematches.
4. When you reach N/2 descriptors, push the next N.
5. Compare all matches, choose the best one or the best D descriptors, as per your requirement.
No entanto, para isso, prefiro usar a classe FileStorage embutida do OpenCV, que fornece E/S em arquivos XML e YAML; ele resolve a dor de cabeça de analisar manualmente os valores do descritor.