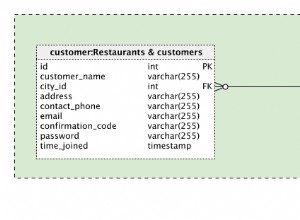
Retornará todos os registros que possuem dups:
SELECT theTable.*
FROM theTable
INNER JOIN (
SELECT link, size
FROM theTable
GROUP BY link, size
HAVING count(ID) > 1
) dups ON theTable.link = dups.link AND theTable.size = dups.size
Eu gosto da subconsulta b/c eu posso fazer coisas como selecionar tudo menos o primeiro ou o último. (muito fácil de se transformar em uma consulta de exclusão então).
Exemplo:selecione todos os registros duplicados, EXCETO aquele com o ID máximo:
SELECT theTable.*
FROM theTable
INNER JOIN (
SELECT link, size, max(ID) as maxID
FROM theTable
GROUP BY link, size
HAVING count(ID) > 1
) dups ON theTable.link = dups.link
AND theTable.size = dups.size
AND theTable.ID <> dups.maxID