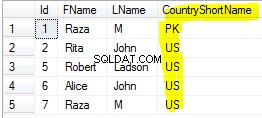
Respondendo à pergunta EDITADA (ou seja, para obter colunas associadas também).
No Sql Server 2005+, a melhor abordagem seria usar um ranking/window função em conjunto com um CTE , assim:
with exam_data as
(
select r.student_id, r.score, r.date,
row_number() over(partition by r.student_id order by r.score desc) as rn
from exam_results r
)
select s.name, d.score, d.date, d.student_id
from students s
join exam_data d
on s.id = d.student_id
where d.rn = 1;
Para uma solução compatível com ANSI-SQL, uma subconsulta e uma autojunção funcionarão, assim:
select s.name, r.student_id, r.score, r.date
from (
select r.student_id, max(r.score) as max_score
from exam_results r
group by r.student_id
) d
join exam_results r
on r.student_id = d.student_id
and r.score = d.max_score
join students s
on s.id = r.student_id;
Este último assume que não há combinações de student_id/max_score duplicadas, se houver e/ou você quiser planejar desduplicar, você precisará usar outra subconsulta para unir com algo determinístico para decidir qual registro extrair . Por exemplo, supondo que você não possa ter vários registros para um determinado aluno com a mesma data, se quiser desempate com base na max_score mais recente, faça algo como o seguinte:
select s.name, r3.student_id, r3.score, r3.date, r3.other_column_a, ...
from (
select r2.student_id, r2.score as max_score, max(r2.date) as max_score_max_date
from (
select r1.student_id, max(r1.score) as max_score
from exam_results r1
group by r1.student_id
) d
join exam_results r2
on r2.student_id = d.student_id
and r2.score = d.max_score
group by r2.student_id, r2.score
) r
join exam_results r3
on r3.student_id = r.student_id
and r3.score = r.max_score
and r3.date = r.max_score_max_date
join students s
on s.id = r3.student_id;
EDIT:Adicionada consulta de desduplicação adequada graças à boa captura de Mark nos comentários