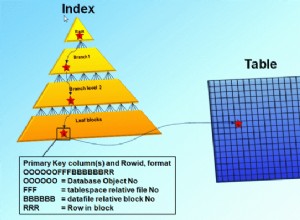
Referindo-se a https://mysql.rjweb.org/utf8_collations.html , vejo que
ı=i em 3 agrupamentos:utf8_general_ci, utf8_general_mysql500_ci, utf8_turkish_ci. No entanto, para o agrupamento turco, I=ı classifica antes de outros I acentuados. Em todos os outros agrupamentos ı classifica afinal os I's, como se fosse tratado como uma letra separada. Enquanto isso
İ=I em todos os agrupamentos, exceto utf8_turkish_ci. O enredo engrossa com o MySQL 8.0. utf8mb4_tr_0900_ai_ci (somente) tem esta ordem:
I=Ì=Í=Î=Ï=Ĩ=Ī=Ĭ=Į=ı sort before i=ì=í=î=ï=ĩ=ī=ĭ=į=İ
Enquanto isso
ä=Ä e eles combinam com a maioria dos outros A acentuados para a maioria dos agrupamentos (incluindo os turcos). Resumindo:Parece que utf8[mb4]_general_ci é o único agrupamento em 5.7 ou 8.0 que sempre tratará um dotless-i (ou dotted-I) igual a um 'i/I regular e ao mesmo tempo ignore os tremas.
Advertência:Os agrupamentos "gerais" não testam mais de um caractere por vez. Ou seja, um "trema sem espaçamento" mais uma vogal não serão tratados como iguais à combinação.
Nesse link... O caractere
æ é classificado da mesma forma que as duas letras ae para alguns agrupamentos. Isso é indicado por:Aa ae=æ az . Em cerca de metade dos outros agrupamentos, o caractere æ é tratado como uma carta separada; isso é indicado por estar depois de az e antes de b . Ou mesmo depois de zz para agrupamentos escandinavos. Este conceito de letra separada às vezes se aplica a pares de letras, por exemplo cs (húngaro) e ch (espanhol tradicional).