Eu tentaria simplificar isso COMPLETAMENTE colocando gatilhos em suas outras tabelas e apenas adicionando algumas colunas à sua tabela User_Fans... Uma para cada count() respectiva que você está tentando obter... de Posts, PostLikes, PostComments, PostCommentLikes.
Quando um registro é adicionado a qualquer tabela, apenas atualize sua tabela user_fans para adicionar 1 à contagem ... será praticamente instantâneo com base no ID da chave do usuário de qualquer maneira. Quanto ao "LIKES"... Semelhante, apenas sob a condição de que algo seja acionado como um "Like", adicione 1.. Então sua consulta será uma matemática direta no registro único e não dependerá de QUALQUER junção para calcular um valor total "ponderado". À medida que sua tabela fica ainda maior, as consultas também ficam mais longas, pois têm mais dados para serem distribuídos e agregados. Você está passando por TODOS os registros user_fan que, em essência, estão consultando todos os registros de todas as outras tabelas.
Dito isso, mantendo as tabelas como você as tem, eu reestruturaria da seguinte forma...
SELECT
uf.user_name,
uf.user_id,
@pc := coalesce( PostSummary.PostCount, 000000 ) as PostCount,
@pl := coalesce( PostLikes.LikesCount, 000000 ) as PostLikes,
@cc := coalesce( CommentSummary.CommentsCount, 000000 ) as PostComments,
@cl := coalesce( CommentLikes.LikesCount, 000000 ) as CommentLikes,
@pc + @cc AS sum_post,
@pl + @cl AS sum_like,
@pCalc := (@pc + @cc) * 10 AS post_cal,
@lCalc := (@pl + @cl) * 5 AS like_cal,
@pCalc + @lCalc AS `total`
FROM
( select @pc := 0,
@pl := 0,
@cc := 0,
@cl := 0,
@pCalc := 0
@lCalc := 0 ) sqlvars,
user_fans uf
LEFT JOIN ( select user_id, COUNT(*) as PostCount
from post
group by user_id ) as PostSummary
ON uf.user_id = PostSummary.User_ID
LEFT JOIN ( select user_id, COUNT(*) as LikesCount
from post_likes
group by user_id ) as PostLikes
ON uf.user_id = PostLikes.User_ID
LEFT JOIN ( select user_id, COUNT(*) as CommentsCount
from post_comment
group by user_id ) as CommentSummary
ON uf.user_id = CommentSummary.User_ID
LEFT JOIN ( select user_id, COUNT(*) as LikesCount
from post_comment_likes
group by user_id ) as CommentLikes
ON uf.user_id = CommentLikes.User_ID
ORDER BY
`total` DESC
LIMIT 20
My variables are abbreviated as
"@pc" = PostCount
"@pl" = PostLikes
"@cc" = CommentCount
"@cl" = CommentLike
"@pCalc" = weighted calc of post and comment count * 10 weighted value
"@lCalc" = weighted calc of post and comment likes * 5 weighted value
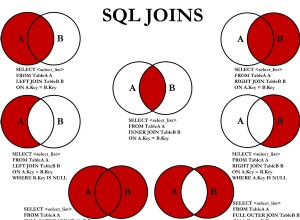
O LEFT JOIN para pré-consultas executa essas consultas UMA VEZ, então a coisa toda é unida em vez de ser atingida como uma subconsulta para cada registro. Ao usar o COALESCE(), se não houver tais entradas nos resultados da tabela LEFT JOINed, você não será atingido com valores NULL atrapalhando os cálculos, então eu os padronizei para 000000.
ESCLARECIMENTO DE SUAS PERGUNTAS
Você pode ter qualquer QUERY como um "AS AliasResult". O "As" também pode ser usado para simplificar qualquer nome de tabela longo para facilitar a leitura. Os aliases também podem usar a mesma tabela, mas como um alias diferente, para obter conteúdo semelhante, mas com finalidades diferentes.
select
MyAlias.SomeField
from
MySuperLongTableNameInDatabase MyAlias ...
select
c.LastName,
o.OrderAmount
from
customers c
join orders o
on c.customerID = o.customerID ...
select
PQ.SomeKey
from
( select ST.SomeKey
from SomeTable ST
where ST.SomeDate between X and Y ) as PQ
JOIN SomeOtherTable SOT
on PQ.SomeKey = SOT.SomeKey ...
Agora, a terceira consulta acima não é prática exigindo a ( consulta completa resultando no alias "PQ" representando "PreQuery" ). Isso poderia ser feito se você quisesse pré-limitar um certo conjunto de outras condições complexas e quisesse um conjunto menor ANTES de fazer junções extras em muitas outras tabelas para todos os resultados finais.
Como um "FROM" não precisa ser uma tabela real, mas pode ser uma consulta em si, em qualquer outro lugar usado na consulta, ele precisa saber como fazer referência a esse conjunto de resultados de pré-consulta.
Além disso, ao consultar campos, eles também podem ser "As FinalColumnName" para simplificar os resultados para onde quer que sejam usados.
selectCONCAT( User.Salutation, User.LastName ) como CourtesyNamefrom ...
selectOrder.NonTaxable+ Order.Taxable+ ( Order.Taxable * Order.SalesTaxRate ) como OrderTotalWithTaxfrom ...
O nome da coluna "As" NÃO precisa ser um agregado, mas é mais comumente visto dessa maneira.
Agora, com respeito às variáveis do MySQL... Se você estiver fazendo um procedimento armazenado, muitas pessoas irão pré-declará-los definindo seus valores padrão antes do resto do procedimento. Você pode fazê-los in-line em uma consulta apenas definindo e dando a esse resultado uma referência "Alias". Ao fazer essas variáveis, o select irá simular sempre retornando um SINGLE RECORD no valor dos valores. É quase como um único registro atualizável usado na consulta. Você não precisa aplicar nenhuma condição de "Join" específica, pois pode não ter relação com o restante das tabelas em uma consulta... Em essência, cria um resultado cartesiano, mas um registro em relação a qualquer outra tabela nunca criará duplica de qualquer maneira, então nenhum dano a jusante.
select
...
from
( select @SomeVar := 0,
@SomeDate := curdate(),
@SomeString := "hello" ) as SQLVars
Agora, como os sqlvars funcionam. Pense em um programa linear... Um comando é executado na sequência exata da execução da consulta. Esse valor é então armazenado novamente no registro "SQLVars" pronto para a próxima vez. No entanto, você não faz referência a ele como SQLVars.SomeVar ou SQLVars.SomeDate... apenas @SomeVar :=someNewValue. Agora, quando o @var é usado em uma consulta, ele também é armazenado como "As ColumnName" no conjunto de resultados. Algumas vezes, isso pode ser apenas um valor calculado de espaço reservado na preparação do próximo registro. Cada valor fica então diretamente disponível para a próxima linha. Então, dado o exemplo a seguir...
select
@SomeVar := SomeVar * 2 as FirstVal,
@SomeVar := SomeVar * 2 as SecondVal,
@SomeVar := SomeVar * 2 as ThirdVal
from
( select @SomeVar := 1 ) sqlvars,
AnotherTable
limit 3
Will result in 3 records with the values of
FirstVal SecondVal ThirdVal
2 4 8
16 32 64
128 256 512
Observe como o valor de @SomeVar é usado à medida que cada coluna o usa... Então, mesmo no mesmo registro, o valor atualizado está imediatamente disponível para a próxima coluna... Dito isso, agora tente construir uma contagem de registros simulada / ranking por cada cliente...
select
o.CustomerID,
o.OrderID
@SeqNo := if( @LastID = o.CustomerID, @SeqNo +1, 1 ) as CustomerSequence,
@LastID := o.CustomerID as PlaceHolderToSaveForNextRecordCompare
from
orders o,
( select @SeqNo := 0, @LastID := 0 ) sqlvars
order by
o.CustomerID
A cláusula "Order By" força os resultados a serem retornados em sequência primeiro. Então, aqui, os registros por cliente são retornados. Na primeira vez, LastID é 0 e o ID do cliente é, digamos... 5. Por ser diferente, ele retorna 1 como @SeqNo, ENTÃO ele preserva esse ID do cliente no campo @LastID para o próximo registro. Agora, próximo registro para o cliente... O último ID é o mesmo, então ele pega o @SeqNo (agora =1), e adiciona 1 a 1 e se torna #2 para o mesmo cliente... Continue no caminho.. .
Quanto a melhorar a escrita de consultas, dê uma olhada na tag MySQL e veja alguns dos contribuidores pesados. Olhe para as perguntas e algumas das respostas complexas e como funciona a resolução de problemas. Para não dizer que não há outros com pontuações de reputação mais baixas apenas começando e completamente competentes, mas você encontrará quem dá boas respostas e por quê. Veja o histórico de respostas postadas também. Quanto mais você ler e seguir, mais você terá um melhor controle sobre como escrever consultas mais complexas.