Ambas as estratégias de carregamento problemáticas geram exceções se você tentar usá-las com
yield_per , então você realmente não precisa se preocupar muito. Eu acredito o único problema com
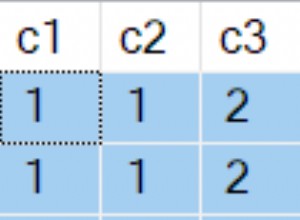
subqueryload é que o carregamento em lote da segunda consulta não foi implementado (ainda). Nada daria errado semanticamente, mas se você estiver usando yield_per , você provavelmente tem um bom motivo para não querer carregar todos os resultados de uma vez. Então SQLAlchemy educadamente se recusa a ir contra seus desejos. joinedload é um pouco mais sutil. Só é proibido no caso de uma coleção, onde uma linha primária pode ter várias linhas associadas. Digamos que sua consulta produza resultados brutos como este, onde A e B são chaves primárias de tabelas diferentes: A | B
---+---
1 | 1
1 | 2
1 | 3
1 | 4
2 | 5
2 | 6
Agora você os busca com
yield_per(3) . O problema é que o SQLAlchemy só pode limitar o quanto ele busca por linhas , mas deve retornar objetos . Aqui, SQLAlchemy vê apenas as três primeiras linhas, então cria um A objeto com chave 1 e três B filhos:1, 2 e 3. Quando ele carrega o próximo lote, ele deseja criar um novo
A objeto com chave 1... ah, mas ele já tem uma dessas, então não precisa criar novamente. O B extra , 4, é perdido. (Então, não, mesmo lendo coleções unidas com yield_per não é seguro — pedaços de seus dados podem desaparecer.) Você pode dizer "bem, continue lendo as linhas até ter um objeto completo" - mas e se esse
A tem cem filhos? Ou um milhão? SQLAlchemy não pode garantir razoavelmente que pode fazer o que você pediu e produzir resultados corretos, por isso se recusa a tentar. Lembre-se de que a DBAPI foi projetada para que qualquer banco de dados pode ser usado com a mesma API, mesmo que esse banco de dados não suporte todos os recursos DBAPI. Considere que a DBAPI é projetada em torno de cursores, mas o MySQL na verdade não tem cursores! Os adaptadores DBAPI para MySQL precisam falsificá-los.
Então, enquanto
cursor.fetchmany(100) vai funcionar , você pode ver no o MySQLdb código-fonte
que não busca preguiçosamente do servidor; ele busca tudo em uma grande lista e retorna uma fatia quando você chama fetchmany . O que
psycopg2 suporta é o verdadeiro streaming, onde os resultados são lembrados persistentemente no servidor, e seu processo Python vê apenas alguns deles por vez. Você ainda pode usar
yield_per com MySQLdb , ou qualquer outro DBAPI; esse é o ponto principal do design do DBAPI. Você terá que pagar o custo de memória para todas as linhas brutas ocultas na DBAPI (que são tuplas, bastante baratas), mas não também tem que pagar por todos os objetos ORM ao mesmo tempo.