Veja como essas duas abordagens serão representadas fisicamente no banco de dados:
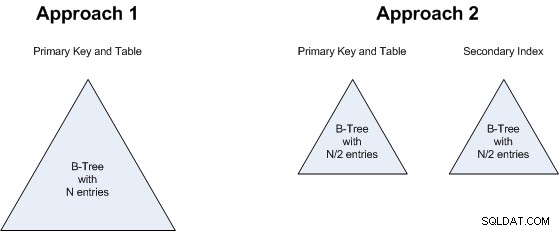
Vamos analisar as duas abordagens...
Abordagem 1 (ambas as direções armazenadas na tabela):
- PRO:consultas mais simples.
- CON:Os dados podem ser corrompidos ao inserir/atualizar/excluir somente uma direção.
- MINOR PRO:não requer restrições adicionais para garantir que uma amizade não possa ser duplicada.
- Análise adicional necessária:
- TIE:um índice capas ambas as direções, então você não precisa de um índice secundário.
- TIE:requisitos de armazenamento.
- TIE:Desempenho.
Abordagem 2 (apenas uma direção armazenada na tabela):
- CON:consultas mais complicadas.
- PRO:Não é possível corromper os dados esquecendo de lidar com a direção oposta, pois não há direção oposta .
- MINOR CON:Requer
CHECK(UID < FriendID), então uma mesma amizade nunca pode ser representada de duas maneiras diferentes, e a chave em(UID, FriendID)pode fazer seu trabalho. - Análise adicional necessária:
- TIE:Dois índices são necessários para cobrir
ambas as direções de consulta (índice composto em
{UID, FriendID}e índice composto em{FriendID, UID}). - TIE:requisitos de armazenamento.
- TIE:Desempenho.
- TIE:Dois índices são necessários para cobrir
ambas as direções de consulta (índice composto em
O ponto 1 é de especial interesse. MySQL/InnoDB sempre clusters dados e índices secundários podem ser caros em tabelas clusterizadas (consulte "Desvantagens do clustering" em este artigo ), então pode parecer que o índice secundário na abordagem 2 consumiria todas as vantagens de menos linhas. No entanto , o índice secundário contém exatamente os mesmos campos que o primário (apenas na ordem oposta), portanto, não há sobrecarga de armazenamento nesse caso específico. Também não há ponteiro para o heap da tabela (já que não há heap da tabela), portanto, provavelmente é ainda mais barato em termos de armazenamento do que um índice normal baseado em heap. E supondo que a consulta seja coberta pelo índice, também não haverá uma pesquisa dupla normalmente associada a um índice secundário em uma tabela clusterizada. Então, isso é basicamente um empate (nem a abordagem 1 nem a abordagem 2 tem vantagem significativa).
O ponto 2 está relacionado ao ponto 1:não importa se teremos uma B-Tree de N valores ou duas B-Trees, cada uma com valores N/2. Portanto, isso também é um empate:ambas as abordagens usarão aproximadamente a mesma quantidade de armazenamento.
O mesmo raciocínio se aplica ao ponto 3 :se procuramos uma B-Tree maior ou 2 menores, não faz muita diferença, então isso também é um empate.
Portanto, pela robustez, e apesar das consultas um pouco mais feias e da necessidade de
CHECK adicionais , eu iria com a abordagem 2.