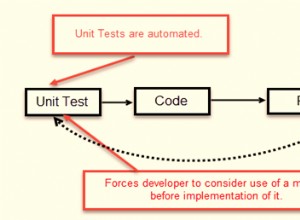
Aqui está um modelo para atingir sua exigência declarada.
Link para o modelo de dados de série temporal forte>
Link para notação IDEF1X para aqueles que não estão familiarizados com o Padrão de Modelagem Relacional.
-
Normalizado para 5NF; sem colunas duplicadas; sem anomalias de atualização, sem nulos.
-
Quando o Status de um Produto muda, basta inserir uma linha no ProductStatus, com o DateTime atual. Não há necessidade de tocar nas linhas anteriores (que eram verdadeiras e permanecem verdadeiras). Nenhum valor fictício que as ferramentas de relatório (além do seu aplicativo) precisam interpretar.
-
O DateTime é o DateTime real em que o Produto foi colocado nesse Status; o "De", se você quiser. O "Para" é facilmente derivado:é o DateTime da próxima linha (DateTime> "From") do Produto; onde não existe, o valor é o DateTime atual (use ISNULL).
O primeiro modelo está completo; (ProductId, DateTime) é suficiente para fornecer exclusividade, para a Chave Primária. No entanto, como você solicita velocidade para determinadas condições de consulta, podemos aprimorar o modelo no nível físico e fornecer:
-
Um índice (já temos o índice PK, então vamos aprimorá-lo primeiro, antes de adicionar um segundo índice) para suportar consultas cobertas (aquelas baseadas em qualquer arranjo de { ProductId | DateTime | Status } podem ser fornecidas pelo índice, sem ter para ir para as linhas de dados). O que altera a relação Status::ProductStatus de Não Identificador (linha quebrada) para Tipo Identificador (linha sólida).
-
O arranjo PK é escolhido com base no fato de que a maioria das consultas será de Séries Temporais, com base no Product⇢DateTime⇢Status.
-
O segundo índice é fornecido para aumentar a velocidade das consultas com base no Status.
-
No Arranjo Alternativo, isso é invertido; ou seja, queremos principalmente o status atual de todos os produtos.
-
Em todas as versões de ProductStatus, a coluna DateTime no índice secundário (não o PK) é DESCending; o mais recente é o primeiro.
Eu forneci a discussão que você solicitou. Claro, você precisa experimentar um conjunto de dados de tamanho razoável e tomar suas próprias decisões. Se houver algo aqui que você não entenda, por favor pergunte, e eu vou expandir.
Respostas a comentários
Relatar todos os produtos com estado atual de 2
SELECT ProductId,
Description
FROM Product p,
ProductStatus ps
WHERE p.ProductId = ps.ProductId -- Join
AND StatusCode = 2 -- Request
AND DateTime = ( -- Current Status on the left ...
SELECT MAX(DateTime) -- Current Status row for outer Product
FROM ProductStatus ps_inner
WHERE p.ProductId = ps_inner.ProductId
)-
ProductIdé Indexado, col inicial, ambos os lados
-
DateTimeem Indexado, 2ª coluna na Opção de Consulta Coberta
-
StatusCodeé indexado, 3ª coluna na opção de consulta coberta
-
DesdeStatusCodeno índice é DESCENDENDO, apenas uma busca é necessária para satisfazer a consulta interna
-
as linhas são necessárias ao mesmo tempo, para uma consulta; eles estão próximos (devido ao Índice Clstered); quase sempre na mesma página devido ao tamanho curto da linha.
Este é o SQL comum, uma subconsulta, usando o poder do mecanismo SQL, processamento de conjunto relacional. É o método correto , não há nada mais rápido e qualquer outro método seria mais lento. Qualquer ferramenta de relatório produzirá esse código com alguns cliques, sem digitação.
Duas datas no ProductStatus
Colunas como DateTimeFrom e DateTimeTo são erros grosseiros. Vamos levá-lo em ordem de importância.
-
É um erro grosseiro de normalização. "DateTimeTo" é facilmente derivado do único DateTime da próxima linha; é, portanto, redundante, uma coluna duplicada.
- A precisão não entra:isso é facilmente resolvido em virtude do DataType (DATE, DATETIME, SMALLDATETIME). Se você exibir um segundo a menos, microssegundo ou nanossegundo, é uma decisão de negócios; não tem nada a ver com os dados armazenados.
-
A implementação de uma coluna DateTo é 100% duplicada (de DateTime da próxima linha). Isso ocupa duas vezes o espaço em disco . Para uma mesa grande, isso seria um desperdício desnecessário significativo.
-
Dado que é uma linha curta, você precisará de duas vezes mais E/S lógicas e físicas para ler a tabela, em cada acesso.
-
E duas vezes mais espaço de cache (ou, em outras palavras, apenas metade das linhas caberia em qualquer espaço de cache).
-
Ao introduzir uma coluna duplicada, você introduziu a possibilidade de erro (o valor agora pode ser derivado de duas maneiras:da coluna DateTimeTo duplicada ou do DateTimeFrom da próxima linha).
-
Esta também é uma Atualização de Anomalia . Quando você atualiza qualquer DateTimeFrom é Updated, o DateTimeTo da linha anterior deve ser buscado (não é grande coisa, pois está próximo) e atualizado (grande coisa, pois é um verbo adicional que pode ser evitado).
-
"Curtos" e "atalhos de codificação" são irrelevantes, SQL é uma linguagem de manipulação de dados complicada, mas SQL é tudo o que temos (Apenas lide com isso). Qualquer pessoa que não possa codificar uma subconsulta realmente não deveria estar codificando. Qualquer pessoa que duplique uma coluna para facilitar a "dificuldade" de codificação menor realmente não deveria estar modelando bancos de dados.
Note bem, que se a regra de ordem mais alta (Normalização) foi mantida, todo o conjunto de problemas de ordem inferior é eliminado.
Pense em termos de conjuntos
-
Qualquer pessoa que tenha "dificuldade" ou "dor" ao escrever SQL simples é prejudicada no desempenho de sua função de trabalho. Normalmente, o desenvolvedor não pensando em termos de conjuntos e o Banco de Dados Relacional é modelo orientado a conjuntos .
-
Para a consulta acima, precisamos do Current DateTime; já que ProductStatus é um conjunto dos Estados do Produto em ordem cronológica, precisamos simplesmente do mais recente, ou MAX(DateTime) do conjunto pertencentes ao Produto.
-
Agora vamos ver algo supostamente "difícil", em termos de conjuntos . Para um relatório da duração em que cada Produto esteve em um determinado Estado:o DateTimeFrom é uma coluna disponível e define o corte horizontal, um sub conjunto (podemos excluir linhas anteriores); o DateTimeTo é o mais antigo do sub conjunto dos Estados do Produto.
SELECT ProductId,
Description,
[DateFrom] = DateTime,
[DateTo] = (
SELECT MIN(DateTime) -- earliest in subset
FROM ProductStatus ps_inner
WHERE p.ProductId = ps_inner.ProductId -- our Product
AND ps_inner.DateTime > ps.DateTime -- defines subset, cutoff
)
FROM Product p,
ProductStatus ps
WHERE p.ProductId = ps.ProductId
AND StatusCode = 2 -- Request-
Pensando em termos de obter a próxima linha é orientado a linhas, não processamento orientado a conjuntos. Crippling, ao trabalhar com um banco de dados orientado a conjuntos. Deixe o Optimizer pensar por você. Verifique seu SHOWPLAN, isso otimiza lindamente.
-
Incapacidade de pensar em conjuntos , limitando-se a escrever apenas consultas de nível único, não é uma justificativa razoável para:implementar duplicação massiva e anomalias de atualização no banco de dados; desperdiçando recursos online e espaço em disco; garantindo metade do desempenho. Muito mais barato aprender a escrever subconsultas SQL simples para obter dados facilmente derivados.