Eu montei uma amostra de transformação (clique com o botão direito e escolha salvar link) com base no que você forneceu. O único passo em que me sinto um pouco incerto são as últimas entradas da tabela. Estou basicamente escrevendo os dados de junção na tabela e deixando-os falhar se já existir um relacionamento específico.
observação:
Essa solução realmente não atende a "Todas as abordagens devem incluir algumas formas de validação e uma estratégia de reversão caso uma inserção falhe ou falhe em manter a integridade referencial". critérios, embora provavelmente não irá falhar. Se você realmente deseja configurar algo complexo, podemos, mas isso definitivamente deve levá-lo a essas transformações.

Fluxo de dados por etapa
1. Começamos com a leitura do seu arquivo. No meu caso, converti para CSV, mas a guia também está bem.

2. Agora vamos inserir os nomes dos funcionários na tabela Employee usando uma
combination lookup/update .Após a inserção, anexamos o employee_id ao nosso fluxo de dados como id e remova o EmployeeName do fluxo de dados. 
3. Aqui estamos apenas usando uma etapa Select Values para renomear o
id campo para employee_id 
4. Insira os cargos como fizemos com os funcionários e anexe o id do título ao nosso fluxo de dados, excluindo também o
JobLevelHistory do fluxo de dados. 
5. Renomeação simples do id do título para title_id (consulte a etapa 3)

6. Insira escritórios, obtenha ids, remova OfficeHistory do fluxo.

7. Renomeação simples do ID do escritório para office_id (consulte a etapa 3)

8. Copie os dados da última etapa em dois fluxos com os valores
employee_id,office_id e employee_id,title_id respectivamente. 
9. Use uma inserção de tabela para inserir os dados de junção. Eu selecionei para ignorar erros de inserção, pois pode haver duplicatas e as restrições de PK farão com que algumas linhas falhem.
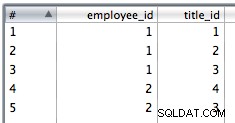
Tabelas de saída