Entrar em produção é uma tarefa muito importante que deve ser cuidadosamente pensada e planejada com antecedência. Algumas decisões não tão boas podem ser facilmente corrigidas depois, mas outras não. Portanto, é sempre melhor gastar esse tempo extra lendo os documentos oficiais, livros e pesquisas feitas por outras pessoas cedo, do que se arrepender depois. Isso é verdade para a maioria das implantações de sistemas de computador, e o PostgreSQL não é exceção.
Planejamento inicial do sistema
Algumas decisões devem ser tomadas antecipadamente, antes que o sistema entre em operação. O DBA do PostgreSQL deve responder a uma série de perguntas:O banco de dados será executado em bare metal, VMs ou mesmo em contêiner? Será executado nas instalações da organização ou na nuvem? Qual SO será usado? O armazenamento será do tipo discos giratórios ou SSDs? Para cada cenário ou decisão, existem prós e contras e a decisão final será feita em cooperação com as partes interessadas de acordo com os requisitos da organização. Tradicionalmente, as pessoas costumavam executar o PostgreSQL em bare metal, mas isso mudou drasticamente nos últimos anos, com mais e mais provedores de nuvem oferecendo o PostgreSQL como uma opção padrão, o que é um sinal da ampla adoção e resultado da crescente popularidade do PostgreSQL. Independentemente da solução específica, o DBA deve garantir que os dados estarão seguros, o que significa que o banco de dados será capaz de sobreviver a falhas, e esse é o critério número 1 na tomada de decisões sobre hardware e armazenamento. Então, isso nos leva à primeira dica!
Dica 1
Não importa o que o controlador de disco ou fabricante de disco ou provedor de armazenamento em nuvem anuncie, você deve sempre certificar-se de que o armazenamento não mente sobre o fsync. Uma vez que o fsync retorna OK, os dados devem estar seguros no meio, não importa o que aconteça depois (falha, falha de energia, etc). Uma boa ferramenta que o ajudará a testar a confiabilidade do cache de write-back de seus discos é diskchecker.pl.
Basta ler as notas:https://brad.livejournal.com/2116715.html e fazer o teste.
Use uma máquina para ouvir eventos e a máquina real para testar. Você deveria ver:
verifying: 0.00%
verifying: 10.65%
…..
verifying: 100.00%
Total errors: 0no final do relatório da máquina testada.
A segunda preocupação após a confiabilidade deve ser sobre o desempenho. As decisões sobre o sistema (CPU, memória) costumavam ser muito mais vitais, pois era muito difícil alterá-las posteriormente. Mas nos dias de hoje, na era da nuvem, podemos ser mais flexíveis sobre os sistemas em que o banco de dados é executado. O mesmo vale para armazenamento, especialmente no início da vida de um sistema e enquanto os tamanhos ainda são pequenos. Quando o banco de dados ultrapassa o número de TB em tamanho, fica cada vez mais difícil alterar os parâmetros básicos de armazenamento sem a necessidade de copiar inteiramente o banco de dados - ou, pior ainda, executar um pg_dump, pg_restore. A segunda dica é sobre o desempenho do sistema.
Dica 2
Da mesma forma que sempre testando as promessas dos fabricantes em relação à confiabilidade, o mesmo deve ser feito com relação ao desempenho do hardware. Bonnie++ é o benchmark de desempenho de armazenamento mais popular para sistemas do tipo Unix. Para testes gerais do sistema (CPU, Memória e também armazenamento) nada é mais representativo do que o desempenho do banco de dados. Portanto, o teste básico de desempenho em seu novo sistema seria executar o pgbench, o conjunto de benchmarks oficial do PostgreSQL baseado em TCP-B.
Começar com o pgbench é bastante fácil, tudo o que você precisa fazer é:
example@sqldat.com:~$ createdb pgbench
example@sqldat.com:~$ pgbench -i pgbench
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 100000 tuples (100%) done (elapsed 0.12 s, remaining 0.00 s)
vacuum...
set primary keys...
done.
example@sqldat.com:~$ pgbench pgbench
starting vacuum...end.
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 1
query mode: simple
number of clients: 1
number of threads: 1
number of transactions per client: 10
number of transactions actually processed: 10/10
latency average = 2.038 ms
tps = 490.748098 (including connections establishing)
tps = 642.100047 (excluding connections establishing)
example@sqldat.com:~$Você deve sempre consultar o pgbench após qualquer mudança importante que deseja avaliar e comparar os resultados.
Implantação, automação e monitoramento do sistema
Depois de entrar em operação, é muito importante ter os principais componentes do sistema documentados e reproduzíveis, ter procedimentos automatizados para criar serviços e tarefas recorrentes e também ter as ferramentas para realizar o monitoramento contínuo.
Dica 3
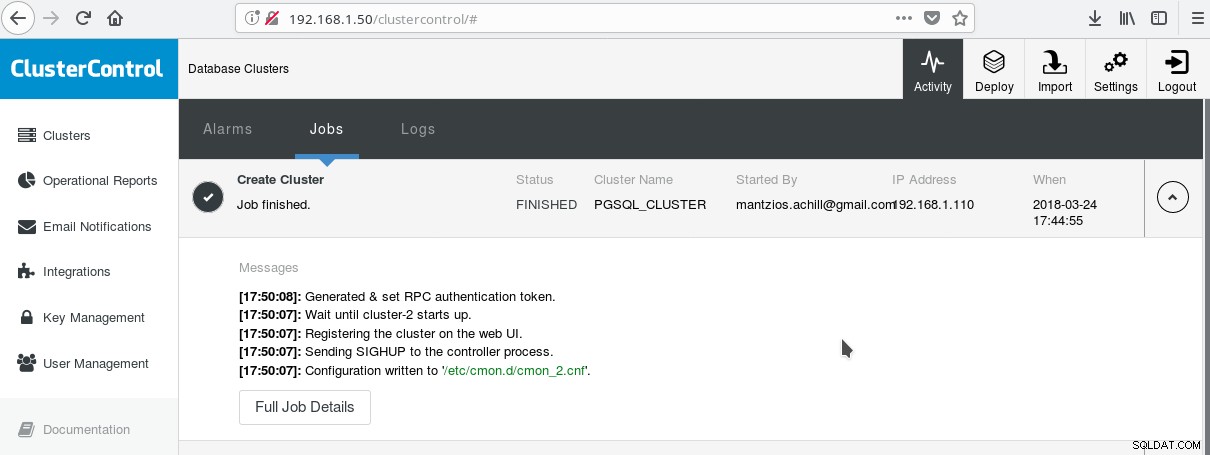
Uma maneira prática de começar a usar o PostgreSQL com todos os seus recursos empresariais avançados é o ClusterControl da Variousnines. Pode-se ter um cluster PostgreSQL de classe empresarial, apenas com alguns cliques. ClusterControl fornece todos esses serviços mencionados e muito mais. Configurar o ClusterControl é bastante fácil, basta seguir as instruções na documentação oficial. Uma vez que você preparou seus sistemas (normalmente um para rodar CC e outro para PostgreSQL para uma configuração básica) e fez a configuração SSH, então você deve inserir os parâmetros básicos (IPs, Portas, etc), e se tudo correr bem você deve veja uma saída como a seguinte:
E na tela principal de clusters:
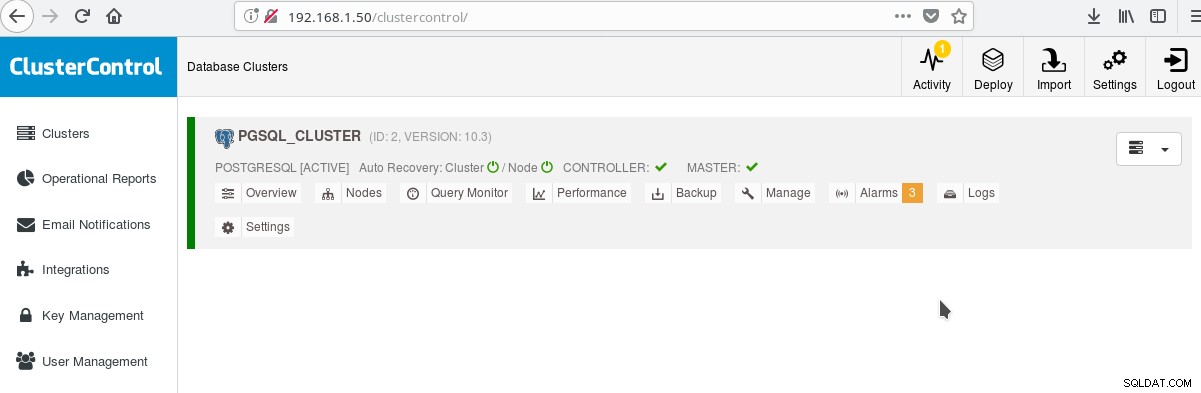
Você pode fazer login no seu servidor mestre e começar a criar seu esquema! Claro que você pode usar como base o cluster que acabou de criar para construir ainda mais sua infraestrutura (topologia). Geralmente, uma boa ideia é ter um layout de sistema de arquivos de servidor estável e uma configuração final em seu servidor PostgreSQL e bancos de dados de usuários/aplicativos antes de começar a criar clones e standbys (escravos) com base em seu novo servidor recém-criado.
Layout, parâmetros e configurações do PostgreSQL
Na fase de inicialização do cluster, a decisão mais importante é usar ou não as somas de verificação de dados nas páginas de dados. Se você deseja a máxima segurança de dados para seus dados valiosos (futuros), então esta é a hora de fazê-lo. Se houver uma chance de você querer esse recurso no futuro e deixar de fazê-lo neste estágio, não poderá alterá-lo mais tarde (sem pg_dump/pg_restore). Esta é a próxima dica:
Dica 4
Para habilitar as somas de verificação de dados, execute o initdb da seguinte forma:
$ /usr/lib/postgresql/10/bin/initdb --data-checksums <DATADIR>Observe que isso deve ser feito no momento da dica 3 que descrevemos acima. Se você já criou o cluster com o ClusterControl, terá que executar novamente o pg_createcluster manualmente, pois no momento da redação deste artigo não há como informar ao sistema ou ao CC para incluir essa opção.
Outro passo muito importante antes de entrar em produção é planejar o layout do sistema de arquivos do servidor. A maioria das distribuições linux modernas (pelo menos as baseadas em debian) montam tudo em / mas com o PostgreSQL normalmente você não quer isso. É benéfico ter seu(s) tablespace(s) em volume(s) separado(s), ter um volume dedicado para os arquivos WAL e outro para pg log. Mas o mais importante é mover o WAL para seu próprio disco. Isso nos leva à próxima dica.
Dica 5
Com o PostgreSQL 10 no Debian Stretch, você pode mover seu WAL para um novo disco com os seguintes comandos (supondo que o novo disco tenha o nome /dev/sdb ):
# mkfs.ext4 /dev/sdb
# mount /dev/sdb /pgsql_wal
# mkdir /pgsql_wal/pgsql
# chown postgres:postgres /pgsql_wal/pgsql
# systemctl stop postgresql
# su postgres
$ cd /var/lib/postgresql/10/main/
$ mv pg_wal /pgsql_wal/pgsql/.
$ ln -s /pgsql_wal/pgsql/pg_wal
$ exit
# systemctl start postgresqlÉ extremamente importante configurar corretamente a localidade e a codificação de seus bancos de dados. Ignore isso na fase createdb e você se arrependerá muito, pois seu aplicativo/DB se move para os territórios i18n, l10n. A próxima dica mostra exatamente como fazer isso.
Dica 6
Você deve ler os documentos oficiais e decidir sobre suas configurações COLLATE e CTYPE (createdb --locale=) (responsável pela ordem de classificação e classificação de caracteres), bem como a configuração de charset (createdb --encoding=). Especificar UTF8 como a codificação permitirá que seu banco de dados armazene texto em vários idiomas.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Alta disponibilidade do PostgreSQL
Desde o PostgreSQL 9.0, quando a replicação de streaming tornou-se um recurso padrão, tornou-se possível ter um ou mais hot standbys readonly, possibilitando assim a possibilidade de direcionar o tráfego somente leitura para qualquer um dos escravos disponíveis. Existem novos planos para replicação multimestre, mas no momento da redação deste artigo (10.3) só é possível ter um mestre de leitura e gravação, pelo menos no produto oficial de código aberto. Para a próxima dica que trata exatamente disso.
Dica 7
Usaremos nosso ClusterControl PGSQL_CLUSTER criado na Dica 3. Primeiro criamos uma segunda máquina que atuará como nosso escravo readonly (hot standby na terminologia PostgreSQL). Em seguida, clicamos em Add Replication slave e selecionamos nosso master e o novo slave. Após a conclusão do trabalho, você deverá ver esta saída:
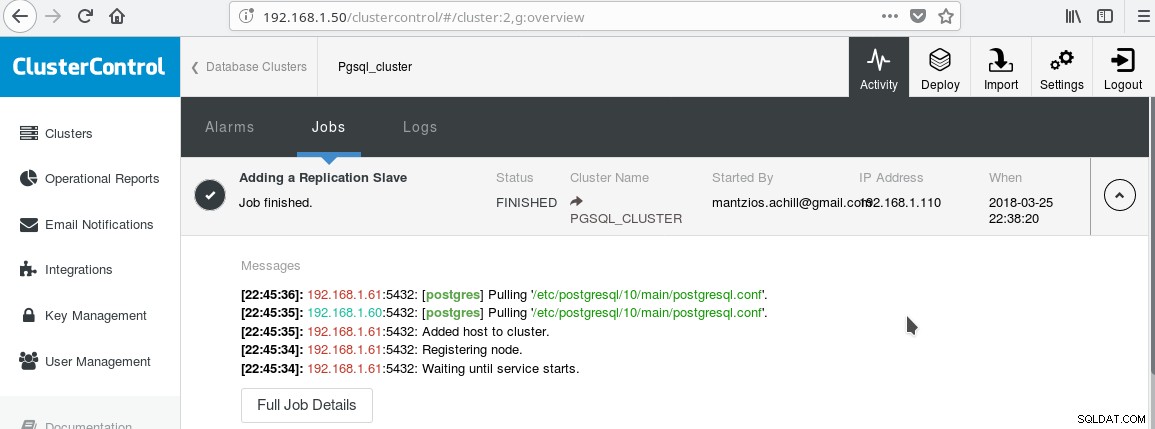
E o cluster agora deve se parecer com:
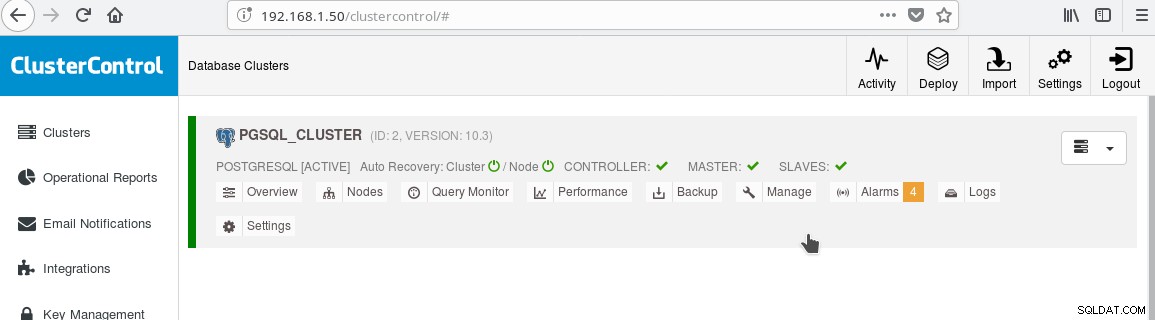
Observe o ícone verde “marcado” na etiqueta “ESCRAVOS” ao lado de “MESTRE”. Você pode verificar se a replicação de streaming funciona, criando um objeto de banco de dados (banco de dados, tabela, etc) ou inserindo algumas linhas em uma tabela no mestre e veja a alteração no standby.
A presença do modo de espera somente leitura nos permite realizar balanceamento de carga para os clientes que fazem consultas somente de seleção entre os dois servidores disponíveis, o mestre e o escravo. Isso nos leva à dica 8.
Dica 8
Você pode habilitar o balanceamento de carga entre os dois servidores usando o HAProxy. Com ClusterControl isso é bastante fácil de fazer. Você clica em Gerenciar->Balancer de carga. Depois de escolher seu servidor HAProxy, o ClusterControl instalará tudo para você:xinetd em todas as instâncias que você especificou e HAProxy em seu servidor HAProxy designado. Depois que o trabalho for concluído com sucesso, você deverá ver:
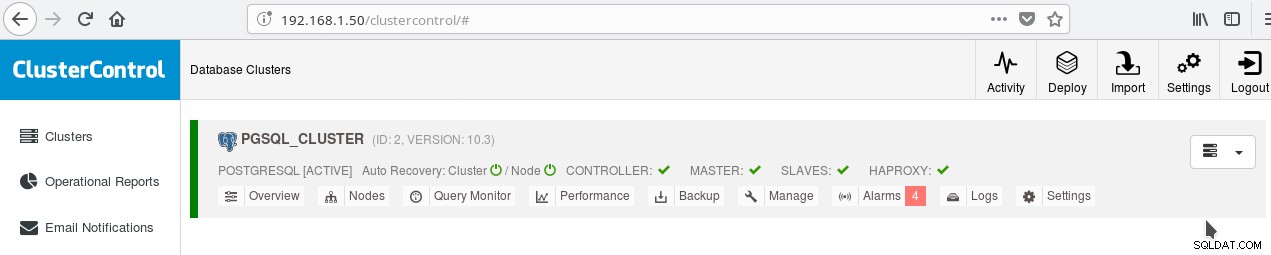
Observe o tique verde HAPROXY ao lado dos SLAVES. Agora você pode testar se o HAProxy funciona:
example@sqldat.com:~$ psql -h localhost -p 5434
psql (10.3 (Debian 10.3-1.pgdg90+1))
SSL connection (protocol: TLSv1.2, cipher: ECDHE-RSA-AES256-GCM-SHA384, bits: 256, compression: off)
Type "help" for help.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.61
(1 row)
--
-- HERE STOP PGSQL SERVER AT 192.168.1.61
--
postgres=# select inet_server_addr();
FATAL: terminating connection due to administrator command
SSL connection has been closed unexpectedly
The connection to the server was lost. Attempting reset: Succeeded.
postgres=# select inet_server_addr();
inet_server_addr
------------------
192.168.1.60
(1 row)
postgres=#Dica 9
Além de configurar para HA e balanceamento de carga, é sempre benéfico ter algum tipo de pool de conexões na frente do servidor PostgreSQL. Pgpool e Pgbouncer são dois projetos vindos da comunidade PostgreSQL. Muitos servidores de aplicativos corporativos também fornecem seus próprios pools. O Pgbouncer tem sido muito popular devido à sua simplicidade, velocidade e ao recurso “transaction pooling”, pelo qual a conexão com o servidor é liberada assim que a transação termina, tornando-o reutilizável para transações subsequentes que podem vir da mesma sessão ou de uma sessão diferente . A configuração do pool de transações interrompe alguns recursos do pool de sessões, mas em geral a conversão para uma configuração pronta para “pooling de transações” é fácil e os contras não são tão importantes no caso geral. Uma configuração comum é configurar o pool do servidor de aplicativos com conexões semi-persistentes:um pool bastante maior de conexões por usuário ou por aplicativo (que se conecta ao pgbouncer) com longos tempos de espera ociosos. Dessa forma, o tempo de conexão do aplicativo é mínimo, enquanto o pgbouncer ajudará a manter as conexões com o servidor o mínimo possível.
Uma coisa que provavelmente será motivo de preocupação quando você entrar em operação com o PostgreSQL é entender e corrigir consultas lentas. As ferramentas de monitoramento que mencionamos no blog anterior como pg_stat_statements e também as telas de ferramentas como ClusterControl irão ajudá-lo a identificar e possivelmente sugerir ideias para corrigir consultas lentas. No entanto, depois de identificar a consulta lenta, você precisará executar EXPLAIN ou EXPLAIN ANALYZE para ver exatamente os custos e os tempos envolvidos no plano de consulta. A próxima dica é sobre uma ferramenta muito útil para fazer isso.
Dica 10
Você deve executar seu EXPLAIN ANALYZE em seu banco de dados e, em seguida, copiar a saída e colá-la na ferramenta online de explicação do depesz e clicar em enviar. Então você verá três guias:HTML, TEXT e STATS. HTML contém custo, tempo e número de loops para cada nó no plano. A guia STATS mostra estatísticas por tipo de nó. Você deve observar a coluna “% de consulta”, para saber exatamente onde sua consulta sofre.
À medida que você se familiarizar com o PostgreSQL, encontrará muitas outras dicas por conta própria!