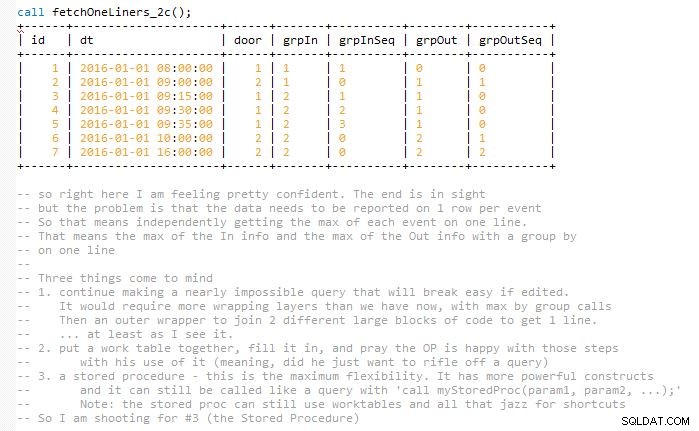
Isso se esforça para manter a solução de fácil manutenção sem terminar a consulta final de uma só vez, o que quase dobraria seu tamanho (na minha opinião). Isso ocorre porque os resultados precisam ser correspondentes e representados em uma linha com eventos de entrada e saída correspondentes. Então, no final, eu uso algumas mesas de trabalho. Ele é implementado em um procedimento armazenado.
O procedimento armazenado usa várias variáveis que são trazidas com uma
cross join . Pense na junção cruzada apenas como um mecanismo para inicializar variáveis. As variáveis são mantidas com segurança, então acredito que, no espírito deste documento
frequentemente referenciado em consultas de variáveis. As partes importantes da referência são o manuseio seguro de variáveis em uma linha, forçando-as a serem definidas antes de outras colunas que as utilizam. Isto é conseguido através do greatest() e least() funções que têm precedência mais alta do que variáveis sendo definidas sem o uso dessas funções. Observe também que coalesce() é frequentemente usado para o mesmo propósito. Se seu uso parece estranho, como tomar o maior de um número conhecido como maior que 0, ou 0, bem, isso é deliberado. Deliberar em forçar a ordem de precedência das variáveis que estão sendo definidas. As colunas na consulta nomearam coisas como
dummy2 etc são colunas que a saída não foi usada, mas foram usadas para definir variáveis dentro, digamos, do greatest() ou outro. Isso foi mencionado acima. A saída como 7777 era um espaço reservado no 3º slot, pois algum valor era necessário para o if() que foi usado. Então ignore tudo isso. Incluí várias capturas de tela do código conforme ele avançava camada por camada para ajudá-lo a visualizar a saída. E como essas iterações de desenvolvimento são lentamente incorporadas à próxima fase para expandir a anterior.
Tenho certeza de que meus colegas poderiam melhorar isso em uma consulta. Eu poderia ter terminado assim. Mas acredito que teria resultado em uma bagunça confusa que quebraria se tocada.
Esquema:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
Procedimento armazenado:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
Teste:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
Este é o fim da resposta. O abaixo é para a visualização de um desenvolvedor das etapas que levaram à conclusão do procedimento armazenado.
Versões de desenvolvimento que levaram até o fim. Espero que isso ajude na visualização em vez de simplesmente descartar um pedaço de código confuso de tamanho médio.
Etapa A
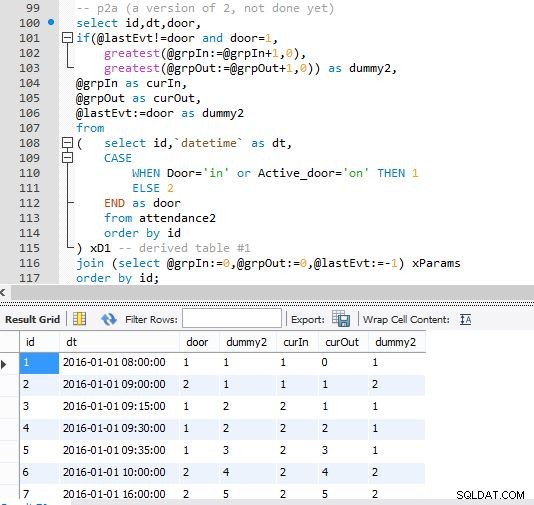
Etapa B
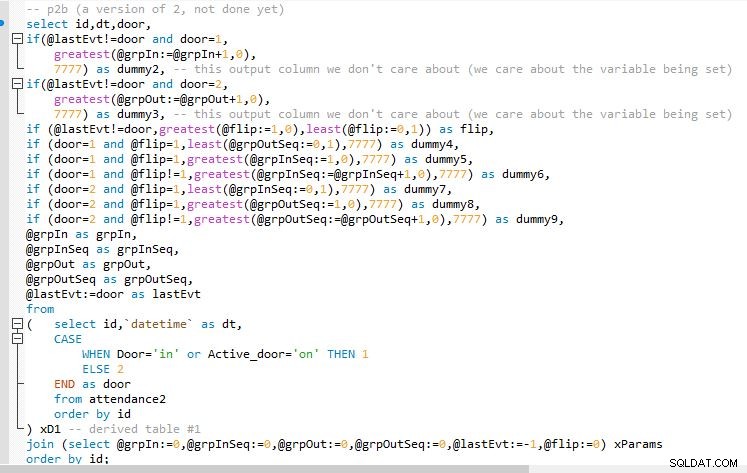
Saída da etapa B

Etapa C
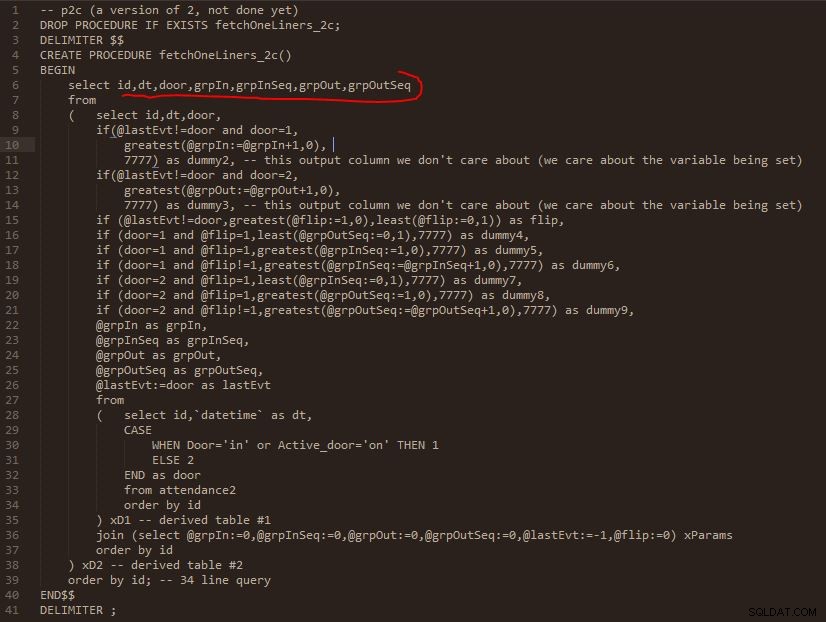
Saída da etapa C