Atualmente, os bancos de dados que abrangem várias nuvens são bastante comuns. Eles prometem alta disponibilidade e possibilidade de implementar facilmente procedimentos de recuperação de desastres. Eles também são um método para evitar o aprisionamento do fornecedor:se você projetar seu ambiente de banco de dados para que ele possa operar em vários provedores de nuvem, provavelmente não estará vinculado a recursos e implementações específicos de um determinado provedor. Isso facilita a adição de outro provedor de infraestrutura ao seu ambiente, seja outra configuração na nuvem ou no local. Essa flexibilidade é muito importante, pois há uma concorrência acirrada entre os provedores de nuvem e a migração de um para outro pode ser bastante viável se for apoiada pela redução de despesas.
Ampliar sua infraestrutura em vários datacenters (do mesmo provedor ou não, não importa) traz sérios problemas para resolver. Como se pode projetar toda a infraestrutura de forma que os dados estejam seguros? Como lidar com os desafios que você precisa enfrentar ao trabalhar em um ambiente multinuvem? Neste blog, vamos dar uma olhada em um, mas sem dúvida o mais sério - o potencial de um cérebro dividido. O que isso significa? Vamos nos aprofundar um pouco no que é o cérebro dividido.
O que é “Cérebro Dividido”?
Split-brain é uma condição na qual um ambiente que consiste em vários nós sofre particionamento de rede e foi dividido em vários segmentos que não têm contato entre si. O caso mais simples ficará assim:
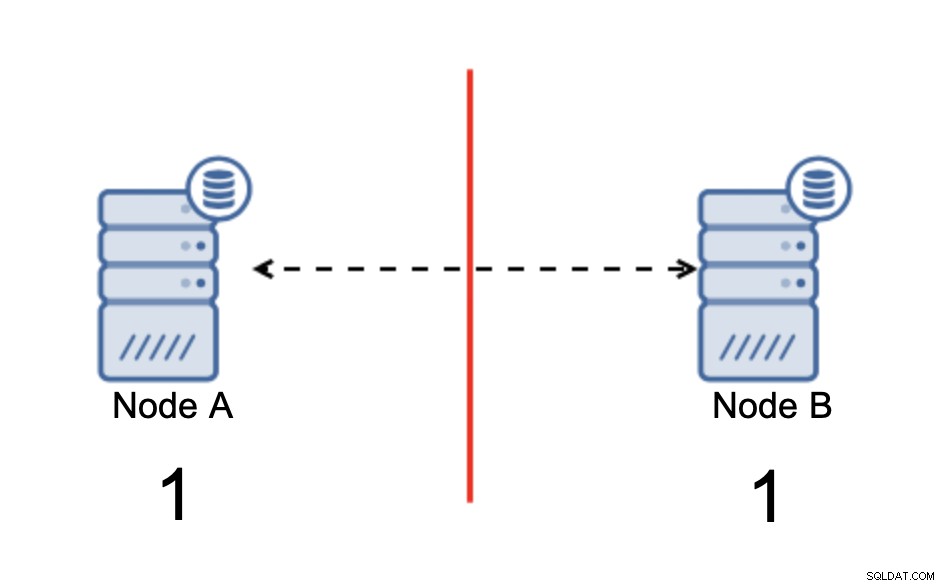
Temos dois nós, A e B, conectados em uma rede usando bi replicação assíncrona direcional. Em seguida, a conexão de rede é cortada entre esses nós. Como resultado, ambos os nós não podem se conectar entre si e quaisquer alterações executadas no nó A não podem ser transmitidas ao nó B e vice-versa. Ambos os nós, A e B, estão ativos e aceitando conexões, eles simplesmente não podem trocar dados. Isso pode levar a problemas sérios, pois o aplicativo pode fazer alterações em ambos os nós esperando ver o estado completo do banco de dados enquanto, na verdade, ele opera apenas em um estado de dados parcialmente conhecido. Como resultado, ações incorretas podem ser tomadas pelo aplicativo, resultados incorretos podem ser apresentados ao usuário e assim por diante. Achamos que está claro que o cérebro dividido é potencialmente uma condição muito perigosa e uma das prioridades seria lidar com isso até certo ponto. O que pode ser feito a respeito?
Como evitar o cérebro dividido
Resumindo, depende. O principal problema a ser tratado é o fato de que os nós estão funcionando, mas não possuem conectividade entre eles, portanto, eles não têm conhecimento do estado do outro nó. Em geral, a replicação assíncrona do MySQL não possui nenhum tipo de mecanismo que resolva internamente o problema do cérebro dividido. Você pode tentar implementar algumas soluções que o ajudem a evitar o cérebro dividido, mas elas vêm com limitações ou ainda não resolvem completamente o problema.
Quando nos afastamos da replicação assíncrona, as coisas parecem diferentes. MySQL Group Replication e MySQL Galera Cluster são tecnologias que se beneficiam do reconhecimento de cluster de compilação. Ambas as soluções mantêm a comunicação entre os nós e garantem que o cluster esteja ciente do estado dos nós. Eles implementam um mecanismo de quorum que controla se os clusters podem estar operacionais ou não.
Vamos discutir essas duas soluções (replicação assíncrona e clusters baseados em quórum) com mais detalhes.
Agrupamento baseado em quórum
Não vamos discutir as diferenças de implementação entre MySQL Galera Cluster e MySQL Group Replication, vamos nos concentrar na ideia básica por trás da abordagem baseada em quorum e como ela é projetada para resolver o problema da split-brain em seu cluster.
A conclusão é que:o cluster, para operar, requer que a maioria de seus nós esteja disponível. Com esse requisito, podemos ter certeza de que a minoria nunca pode realmente afetar o resto do cluster, porque a minoria não deve ser capaz de realizar nenhuma ação. Isso também significa que, para poder lidar com uma falha de um nó, um cluster deve ter pelo menos três nós. Se você tiver apenas dois nós:
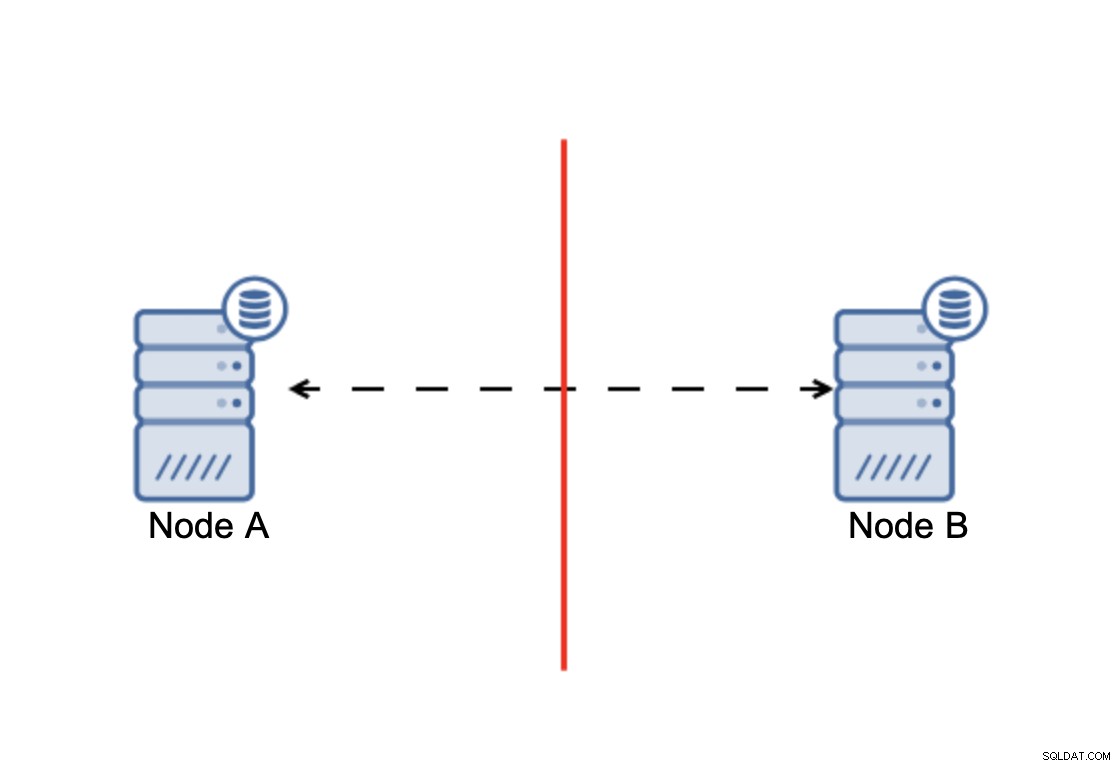
Quando há uma divisão de rede, você acaba com duas partes do cluster, cada um consistindo em exatamente 50% do total de nós no cluster. Nenhuma dessas partes tem maioria. Se você tiver três nós, porém, as coisas são diferentes:
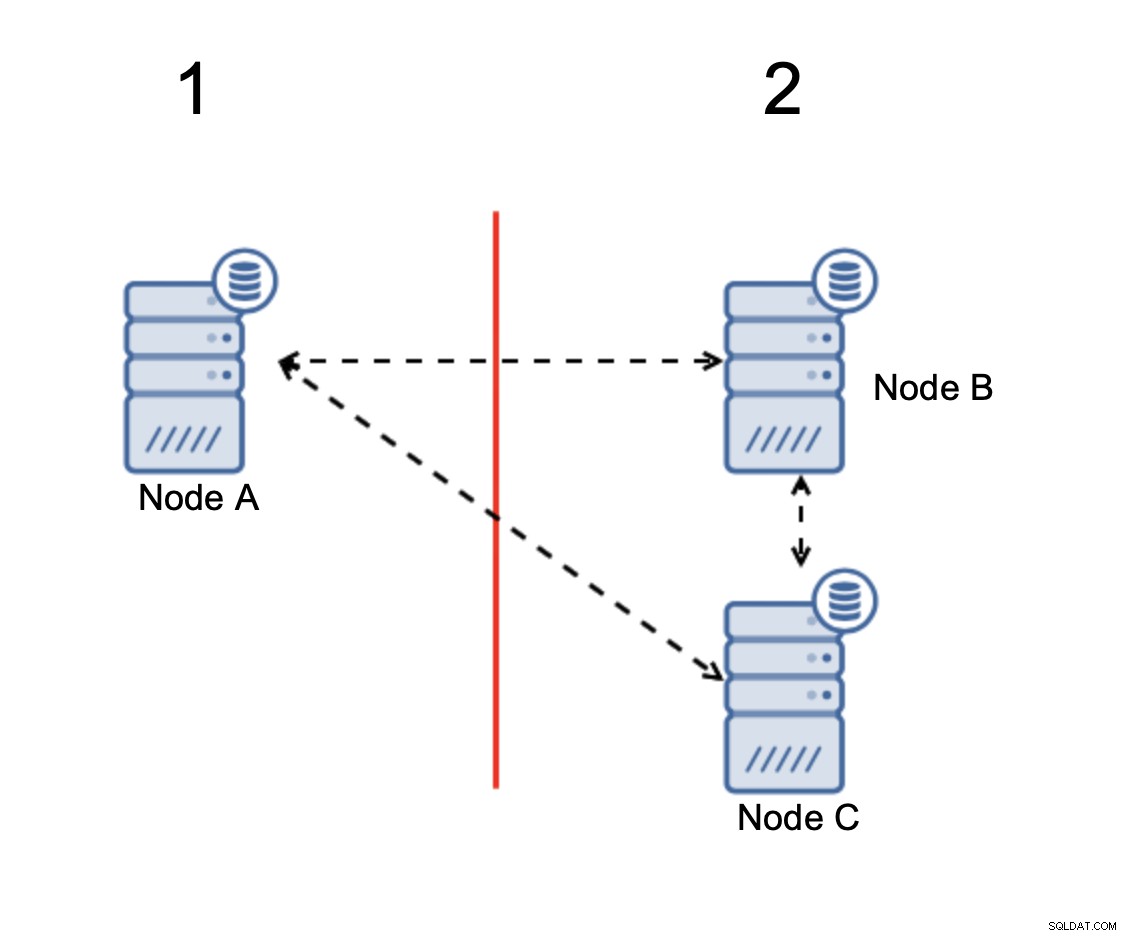
Os nós B e C têm a maioria:essa parte consiste em dois nós fora de três, assim, ele pode continuar a operar. Por outro lado, o nó A representa apenas 33% dos nós do cluster, portanto, não possui maioria e deixará de lidar com o tráfego para evitar o cérebro dividido.
Com tal implementação, é muito improvável que o split-brain aconteça (ele teria que ser introduzido através de alguns estados de rede estranhos e inesperados, condições de corrida ou erros simples no código de cluster. Embora não seja impossível encontrar Nessas condições, usar uma das soluções baseadas em quorum é a melhor opção para evitar o split-brain que existe neste momento.
Replicação assíncrona
Embora não seja a escolha ideal quando se trata de dividir o cérebro, a replicação assíncrona ainda é uma opção viável. Há várias coisas que você deve considerar antes de implementar um banco de dados multinuvem com replicação assíncrona.
Primeiro, failover. A replicação assíncrona vem com um gravador - somente o mestre deve ser gravável e outros nós devem servir apenas tráfego somente leitura. O desafio é como lidar com a falha do mestre?
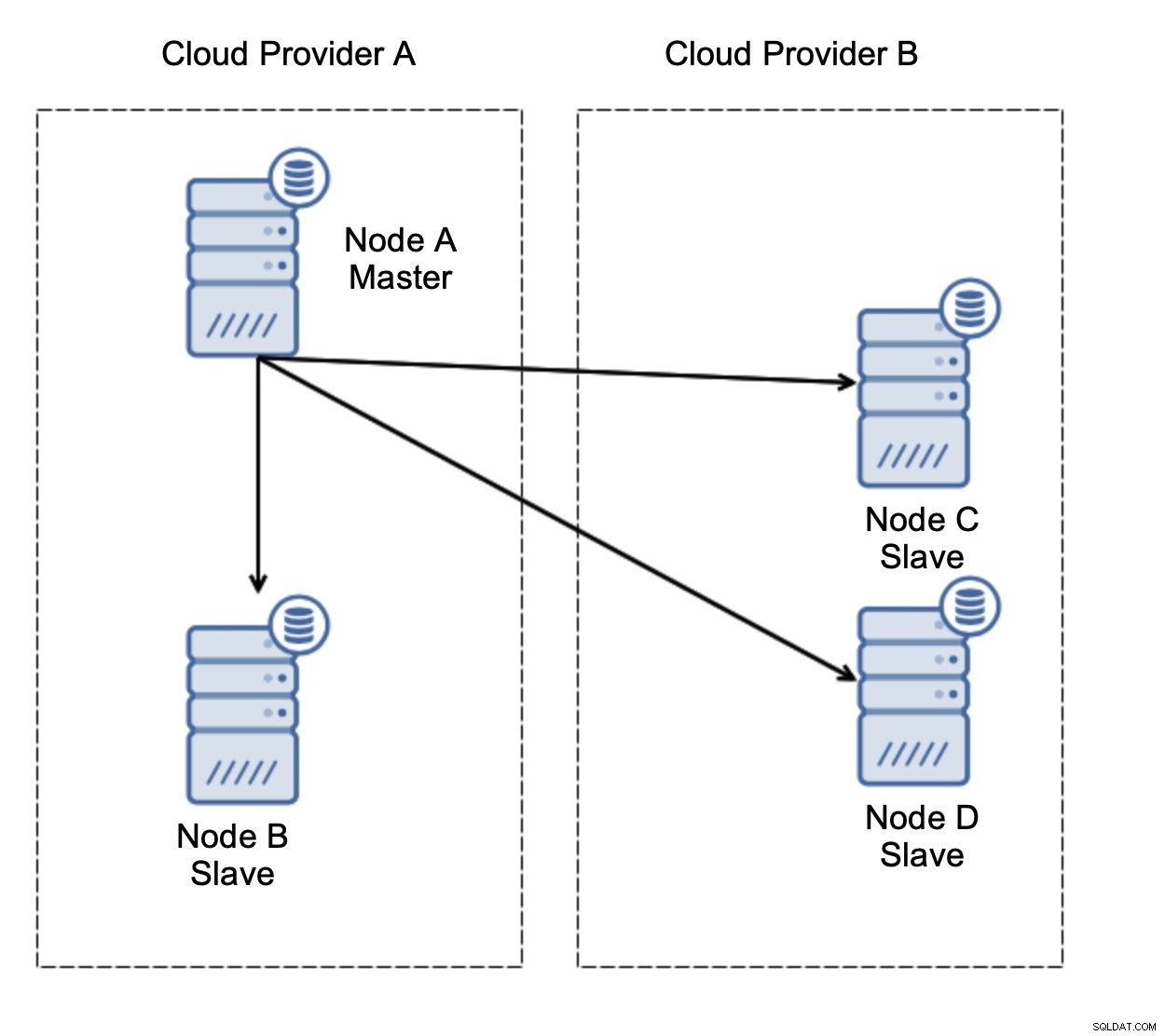
Vamos considerar a configuração como no diagrama acima. Temos dois provedores de nuvem, dois nós em cada. O provedor A hospeda também o mestre. O que deve acontecer se o mestre falhar? Um dos escravos deve ser promovido para garantir que o banco de dados continue operacional. Idealmente, deve ser um processo automatizado para reduzir o tempo necessário para trazer o banco de dados ao estado operacional. O que aconteceria, porém, se houvesse um particionamento de rede? Como se espera que verifiquemos o estado do cluster?
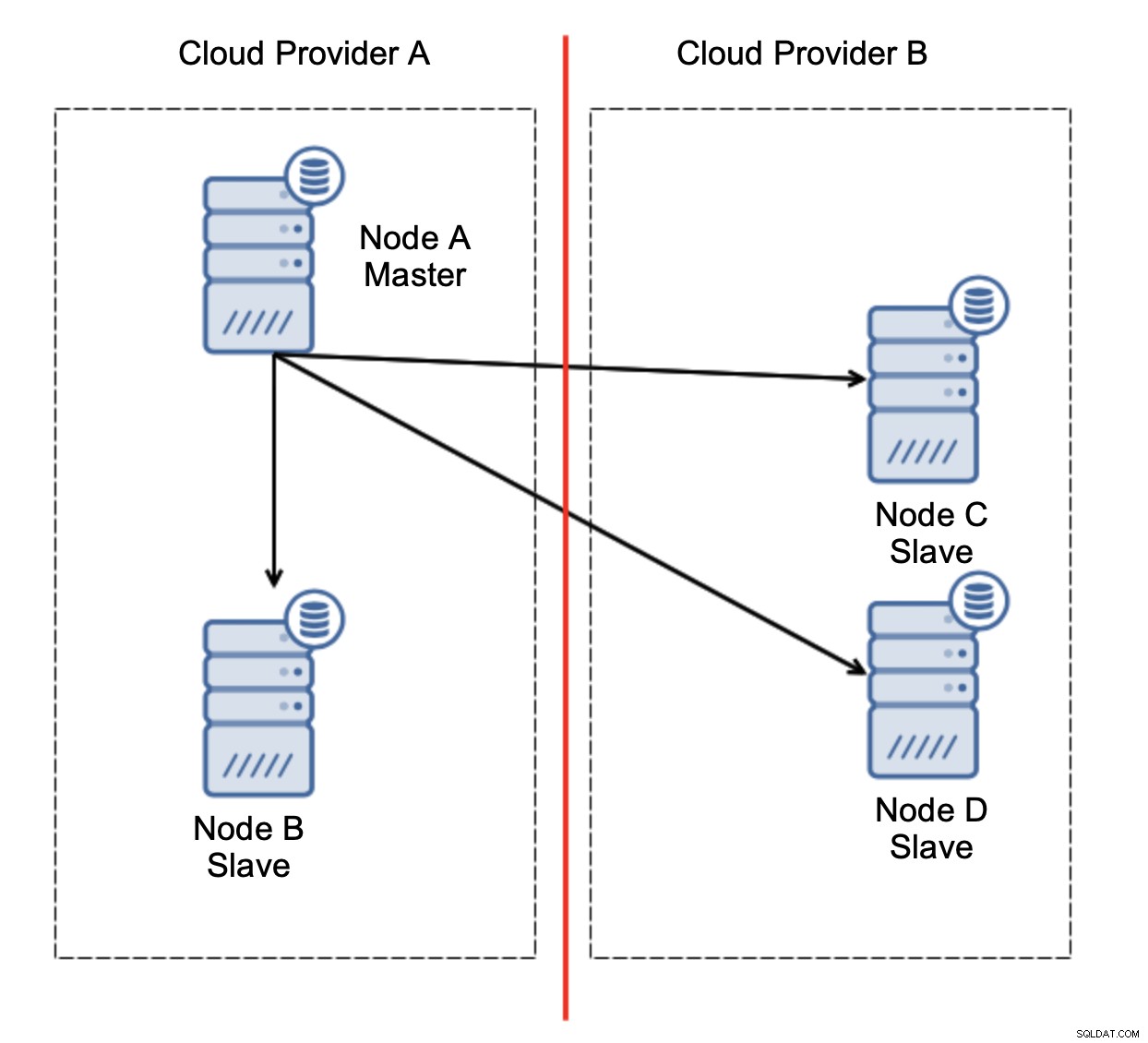
Aqui está o desafio. A conectividade de rede é perdida entre dois provedores de nuvem. Do ponto de vista dos nós C e D, tanto o nó B quanto o mestre, o nó A estão offline. O nó C ou D deve ser promovido a mestre? Mas o antigo mestre ainda está ativo - não travou, simplesmente não é acessível pela rede. Se promovermos um dos nós localizados no provedor B, terminaremos com dois mestres graváveis, dois conjuntos de dados e cérebro dividido:
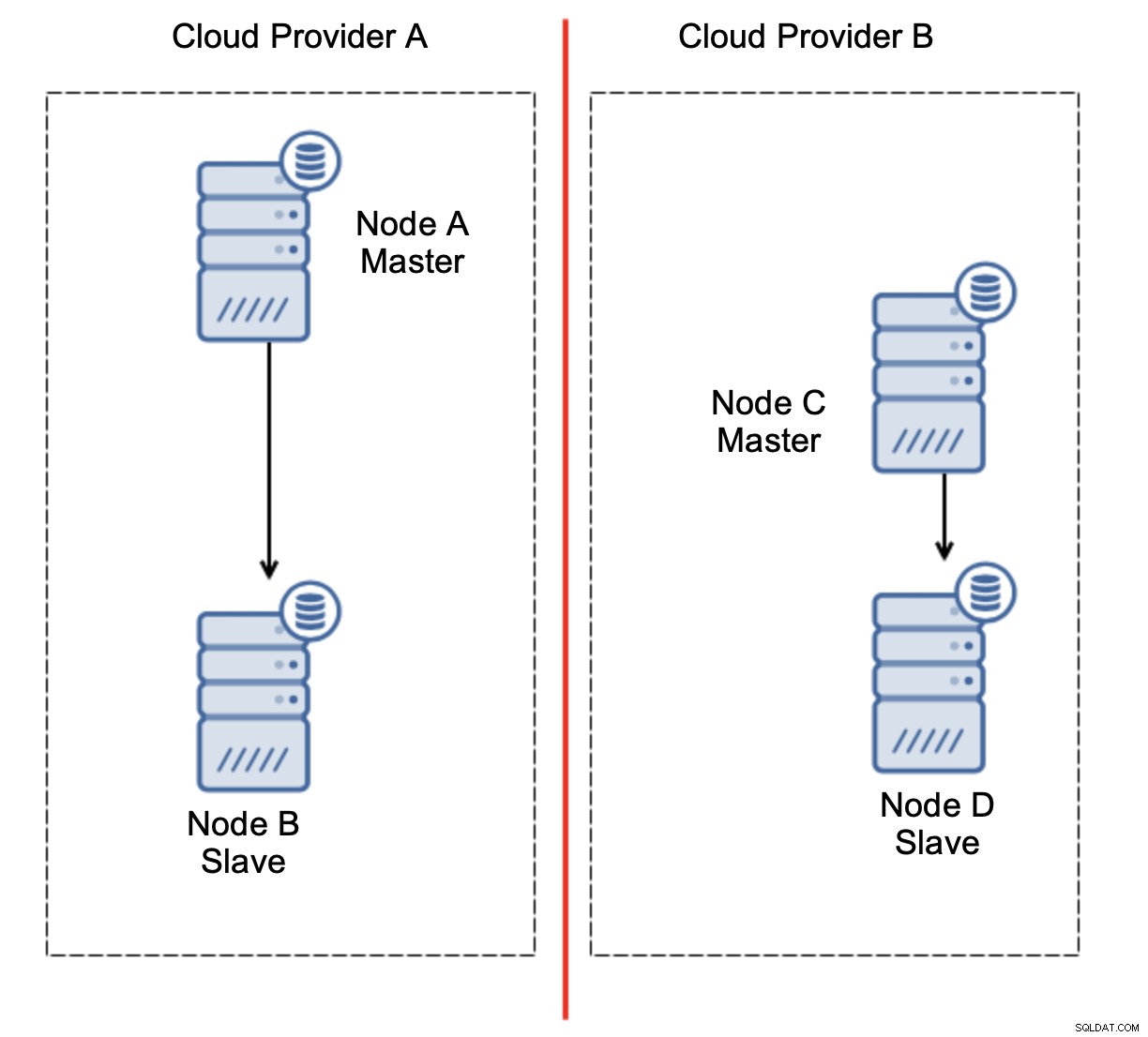
Isso definitivamente não é algo que queremos. Existem algumas opções aqui. Primeiro, podemos definir regras de failover de forma que o failover ocorra apenas em um dos segmentos da rede, onde o mestre está localizado. No nosso caso, isso significaria que apenas o nó B poderia ser promovido automaticamente para se tornar um mestre. Dessa forma, podemos garantir que o failover automatizado ocorrerá se o nó A estiver inativo, mas nenhuma ação será tomada se houver um particionamento de rede. Algumas das ferramentas que podem ajudá-lo a lidar com failovers automatizados (como ClusterControl) suportam listas brancas e negras, permitindo que os usuários definam quais nós podem ser considerados candidatos para failover e quais nunca devem ser usados como mestres.
Outra opção seria implementar algum tipo de solução de “consciência de topologia”. Por exemplo, pode-se tentar verificar o estado do mestre usando serviços externos, como balanceadores de carga.
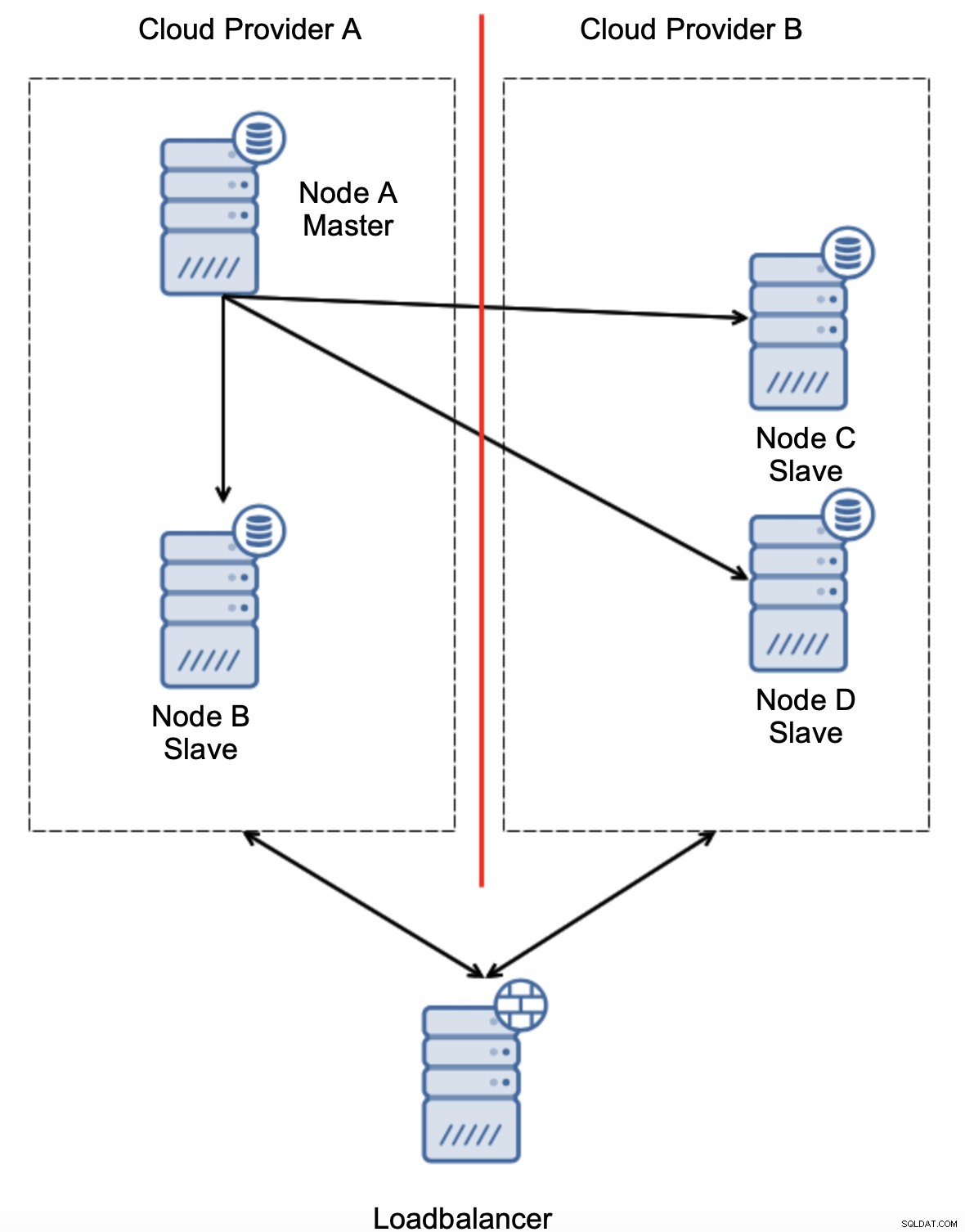
Se a automação de failover puder verificar o estado da topologia conforme visto pelo balanceador de carga, pode ser que o balanceador de carga, localizado em um terceiro local, possa realmente alcançar os dois datacenters e deixar claro que os nós no provedor de nuvem A não estão inativos, eles simplesmente não podem ser alcançados pelo provedor de nuvem B. Tal uma camada adicional de verificações é implementada no ClusterControl.
Finalmente, qualquer que seja a ferramenta que você usa para implementar o failover automatizado, ela também pode ser projetada para ter reconhecimento de quorum. Então, com três nós em três locais, você pode facilmente dizer qual parte da infraestrutura deve ser mantida ativa e qual não deve.
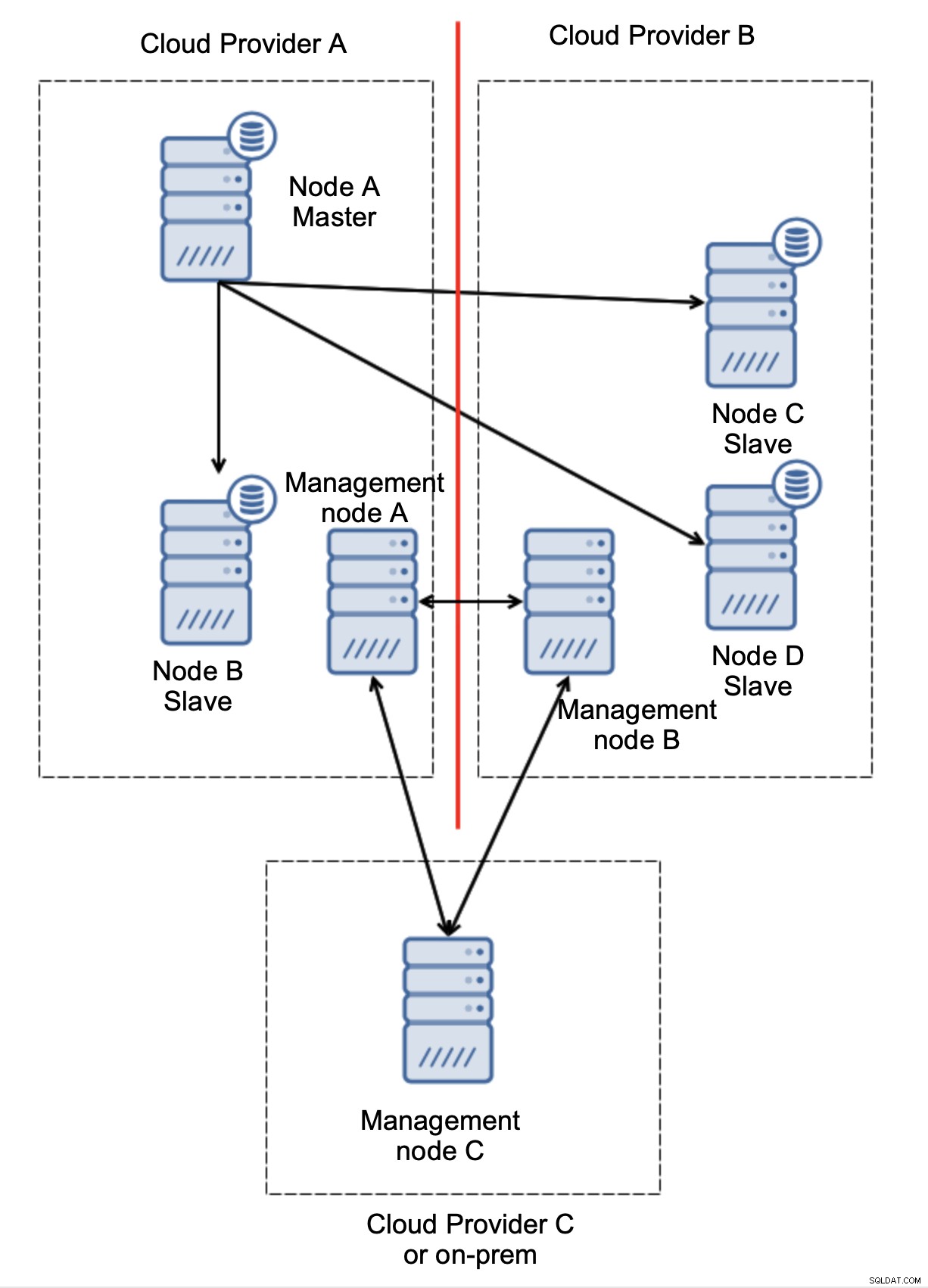
Aqui, podemos ver claramente que o problema está relacionado apenas à conectividade entre os provedores A e B. O nó de gerenciamento C atuará como um relé e, como resultado, nenhum failover deverá ser iniciado. Por outro lado, se um datacenter for totalmente cortado:

Também está bem claro o que aconteceu. O nó de gerenciamento A relatará que não pode alcançar a maioria do cluster, enquanto os nós de gerenciamento B e C formarão a maioria. É possível construir sobre isso e, por exemplo, escrever scripts que irão gerenciar a topologia de acordo com o estado do nó de gerenciamento. Isso pode significar que os scripts executados no provedor de nuvem A detectariam que o nó de gerenciamento A não é a maioria e interromperão todos os nós do banco de dados para garantir que nenhuma gravação ocorra no provedor de nuvem particionado.
ClusterControl, quando implantado no modo de alta disponibilidade, pode ser tratado como os nós de gerenciamento que usamos em nossos exemplos. Três nós ClusterControl, além do protocolo RAFT, podem ajudá-lo a determinar se um determinado segmento de rede está particionado ou não.
Conclusão
Esperamos que esta postagem do blog dê a você uma ideia sobre cenários de cérebro dividido que podem acontecer para implantações do MySQL abrangendo várias plataformas de nuvem.