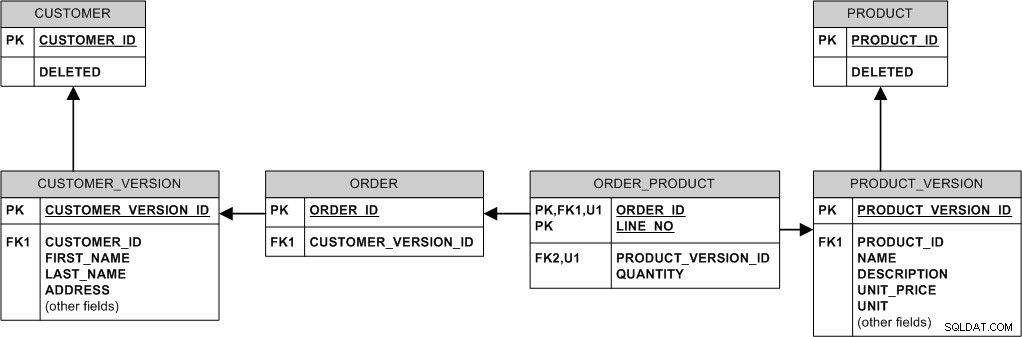
Aqui está uma maneira de fazer isso:
Essencialmente, nunca modificamos ou excluímos os dados existentes. Nós o "modificamos" criando uma nova versão. Nós o "excluímos" definindo o sinalizador DELETED.
Por exemplo:
- Se o preço do produto mudar, inserimos uma nova linha no PRODUCT_VERSION enquanto os pedidos antigos são mantidos conectados ao antigo PRODUCT_VERSION e ao preço antigo.
- Quando o comprador altera o endereço, simplesmente inserimos uma nova linha em CUSTOMER_VERSION e vinculamos novos pedidos a ela, mantendo os pedidos antigos vinculados à versão antiga.
- Se o produto for excluído, não o excluímos realmente - simplesmente definimos o sinalizador PRODUCT.DELETED, para que todos os pedidos feitos historicamente para esse produto permaneçam no banco de dados.
- Se o cliente for excluído (por exemplo, porque ele solicitou o cancelamento do registro), defina o sinalizador CUSTOMER.DELETED.
Ressalvas:
- Se o nome do produto precisar ser exclusivo, isso não poderá ser aplicado declarativamente no modelo acima. Você precisará "promover" o NAME de PRODUCT_VERSION para PRODUCT, torná-lo uma chave e desistir da capacidade de "evoluir" o nome do produto ou impor a exclusividade apenas no PRODUCT_VER mais recente (provavelmente por meio de acionadores).
- Há um possível problema com a privacidade do cliente. Se um cliente for excluído do sistema, pode ser desejável remover fisicamente seus dados do banco de dados e apenas configurar CUSTOMER.DELETED não fará isso. Se isso for uma preocupação, exclua os dados confidenciais de privacidade em todas as versões do cliente ou, alternativamente, desconecte os pedidos existentes do cliente real e reconecte-os a um cliente "anônimo" especial e, em seguida, exclua fisicamente todas as versões do cliente.
Esse modelo usa muitos relacionamentos de identificação. Isso leva a chaves estrangeiras "gordas" e pode ser um problema de armazenamento, já que o MySQL não suporta compressão de índice de ponta (ao contrário, digamos, Oracle), mas por outro lado InnoDB sempre agrupa os dados no PK e esse agrupamento pode ser benéfico para o desempenho. Além disso, JOINs são menos necessários.
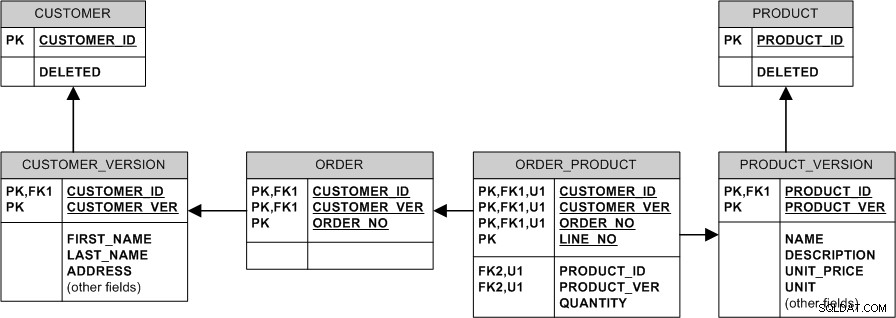
O modelo equivalente com relacionamentos não identificadores e chaves substitutas ficaria assim: