Benjamin Nevarez é um consultor independente com sede em Los Angeles, Califórnia, especializado em ajuste e otimização de consultas do SQL Server. Ele é o autor de “SQL Server 2014 Query Tuning &Optimization” e “Inside the SQL Server Query Optimizer” e coautor de “SQL Server 2012 Internals”. Com mais de 20 anos de experiência em bancos de dados relacionais, Benjamin também foi palestrante em muitas conferências do SQL Server, incluindo o PASS Summit, SQL Server Connections e SQLBits. O blog de Benjamin pode ser encontrado em https://www.benjaminnevarez.com e ele também pode ser contatado por e-mail em admin em benjaminnevarez ponto com e no twitter em @BenjaminNevarez.
Embora a maioria das informações, blogs e documentação sobre o SQL Server 2014 tenham se concentrado no Hekaton e em outros novos recursos, poucos detalhes foram fornecidos sobre o novo estimador de cardinalidade. Atualmente, o BOL fala sobre isso apenas indiretamente na seção Novidades (Mecanismo de Banco de Dados), dizendo que o SQL Server 2014 “inclui melhorias substanciais no componente que cria e otimiza os planos de consulta” e o
ALTER DATABASE instrução mostra como habilitar ou desabilitar seu comportamento. Felizmente, podemos obter algumas informações adicionais lendo o artigo de pesquisa Testing Cardinality Estimation Models in SQL Server, de Campbell Fraser et al. Embora o foco do artigo seja o processo de garantia de qualidade do novo modelo de estimativa, ele também oferece uma introdução básica ao novo estimador de cardinalidade e a motivação de seu redesenho. Então, o que é um estimador de cardinalidade? Um estimador de cardinalidade é o componente do processador de consultas cujo trabalho é estimar o número de linhas retornadas por operações relacionais em uma consulta. Essas informações, juntamente com alguns outros dados, são usadas pelo otimizador de consulta para selecionar um plano de execução eficiente. A estimativa de cardinalidade é inerentemente inexata, pois é um modelo matemático que se baseia em informações estatísticas. Baseia-se também em vários pressupostos que, embora não documentados, são conhecidos ao longo dos anos – alguns deles incluem os pressupostos de uniformidade, independência, contenção e inclusão. Segue uma breve descrição dessas suposições.
- Uniformidade . Usado quando a distribuição de um atributo é desconhecida, por exemplo, dentro das linhas do intervalo em uma etapa do histograma ou quando um histograma não está disponível.
- Independência . Usado quando os atributos em uma relação são independentes, a menos que uma correlação entre eles seja conhecida.
- Contenção . Usado quando dois atributos podem ser iguais, eles são considerados iguais.
- Inclusão . Usado ao comparar um atributo com uma constante, assume-se que sempre há uma correspondência.
É interessante que recentemente falei sobre algumas das limitações dessas suposições em minha última palestra no PASS Summit, chamada Defeating the Limitations of the Query Optimizer. No entanto, fiquei surpreso ao ler no artigo que os autores admitem que, de acordo com sua experiência na prática, essas suposições são “frequentemente incorretas”.
O estimador de cardinalidade atual foi escrito junto com todo o processador de consultas para SQL Server 7.0, que foi lançado em dezembro de 1998. Obviamente, este componente enfrentou várias mudanças durante vários anos e várias versões do SQL Server, incluindo correções, ajustes e extensões para acomodar a estimativa de cardinalidade para novos recursos T-SQL. Então você pode estar pensando, por que substituir um componente que foi usado com sucesso por cerca de 15 anos?
Por que um novo estimador de cardinalidade
O artigo explica algumas das razões do redesenho, incluindo:
- Para acomodar o estimador de cardinalidade aos novos padrões de carga de trabalho.
- As alterações feitas no estimador de cardinalidade ao longo dos anos tornaram o componente difícil de "depurar, prever e entender".
- Tentar melhorar o modelo atual era difícil usando a arquitetura atual, então um novo design foi criado, focado na separação de tarefas de (a) decidir como calcular uma determinada estimativa e (b) realmente realizar o cálculo .
Não tenho certeza se mais detalhes sobre o novo estimador de cardinalidade serão publicados pela Microsoft. Afinal, nunca foram publicados tantos detalhes sobre o antigo estimador de cardinalidade em 15 anos; por exemplo, como alguma estimativa de cardinalidade específica é calculada. Por outro lado, existem novos eventos estendidos que podemos usar para solucionar problemas com a estimativa de cardinalidade ou apenas para explorar como ela funciona. Esses eventos incluem
query_optimizer_estimate_cardinality , inaccurate_cardinality_estimate , query_optimizer_force_both_cardinality_estimation_behaviors e query_rpc_set_cardinality . Planejar regressões
Uma grande preocupação que vem à mente com uma mudança tão grande dentro do otimizador de consulta são as regressões de plano. O medo de regressões de planos tem sido considerado o maior obstáculo para melhorias no otimizador de consultas. Regressões são problemas introduzidos após uma correção ter sido aplicada ao otimizador de consulta e às vezes referidas como o clássico “dois erros fazem um acerto”. Isso pode acontecer quando duas estimativas ruins, por exemplo, uma superestimando um valor e a segunda subestimando-o, se anulam, felizmente dando uma boa estimativa. A correção de apenas um desses valores pode agora levar a uma estimativa incorreta que pode impactar negativamente na escolha da seleção do plano, causando uma regressão.
Para ajudar a evitar regressões relacionadas ao novo estimador de cardinalidade, o SQL Server fornece uma maneira de habilitá-lo ou desabilitá-lo, pois depende do nível de compatibilidade do banco de dados. Isso pode ser alterado usando o
ALTER DATABASE declaração, como indicado anteriormente. Definir um banco de dados para o nível de compatibilidade 120 usará o novo estimador de cardinalidade, enquanto um nível de compatibilidade inferior a 120 usará o antigo estimador de cardinalidade. Além disso, uma vez que você está usando um estimador de cardinalidade específico, há dois sinalizadores de rastreamento que você pode usar para mudar para o outro. Embora no momento eu não veja os sinalizadores de rastreamento documentados em nenhum lugar, eles são mencionados como parte da descrição do query_optimizer_force_both_cardinality_estimation_behaviors evento estendido. O sinalizador de rastreamento 2312 pode ser usado para habilitar o novo estimador de cardinalidade, enquanto o sinalizador de rastreamento 9481 pode ser usado para desativá-lo. Você pode até usar os sinalizadores de rastreamento para uma consulta específica usando o QUERYTRACEON dica (embora ainda não esteja documentado se isso também será suportado). Exemplos
Por fim, o artigo também menciona alguns cenários testados, como a chave primária superpovoada, a junção simples ou o problema da chave ascendente. Também mostra como os autores experimentaram vários cenários (ou variações de modelo) e em alguns casos “relaxaram” algumas das suposições feitas pelo estimador de cardinalidade, por exemplo, no caso da suposição de independência, indo de independência completa para correlação completa e algo intermediário até que bons resultados fossem encontrados.
Embora nenhum detalhe seja fornecido no artigo, decido começar a testar alguns desses cenários para tentar entender como funciona o novo estimador de cardinalidade. Por enquanto vou mostrar um exemplo usando a suposição de independência e chaves ascendentes. Também testei a suposição de uniformidade, mas até agora não consegui encontrar nenhuma diferença na estimativa.
Vamos começar com o exemplo da suposição de independência. Primeiro vamos ver o comportamento atual. Para isso, certifique-se de estar usando o antigo estimador de cardinalidade executando a seguinte instrução no banco de dados AdventureWorks2012:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110;
Então corra:
SELECT * FROM Person.Address WHERE City = 'Burbank';
Obtemos uma estimativa de 196 registros como mostrado a seguir:

De maneira semelhante, a seguinte declaração terá uma estimativa de 194:
SELECT * FROM Person.Address WHERE PostalCode = '91502';
Se usarmos os dois predicados temos a seguinte consulta, que terá um número estimado de linhas de 1,93862 (arredondado para 2 linhas se estiver usando o SQL Sentry Plan Explorer):
SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
Esse valor é calculado assumindo a independência total de ambos os predicados, que usa a fórmula (196 * 194) / 19614.0 (onde 19614 é o número total de linhas na tabela). Usar uma correlação total deve nos dar uma estimativa de 194, já que todos os registros com código postal 91502 pertencem a Burbank. O novo estimador de cardinalidade estima um valor que não assume independência total ou correlação total. Altere para o novo estimador de cardinalidade usando a seguinte instrução:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502';
A execução da mesma instrução novamente fornecerá uma estimativa de 19,3931 linhas, que você pode ver como um valor entre assumir independência total e correlação total (arredondado para 19 linhas no Plan Explorer). A fórmula usada é seletividade do filtro mais seletivo * SQRT(seletividade do próximo filtro mais seletivo) ou (194/19614,0) * SQRT(196/19614,0) * 19614 que dá 19,393:

Se você ativou o novo estimador de cardinalidade no nível do banco de dados, compre para desativá-lo para uma consulta específica para evitar uma regressão do plano, use o sinalizador de rastreamento 9481 conforme explicado anteriormente:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM Person.Address WHERE City = 'Burbank' AND PostalCode = '91502' OPTION (QUERYTRACEON 9481);
Observação:a dica de consulta QUERYTRACEON é usada para aplicar um sinalizador de rastreamento no nível da consulta e, atualmente, só é compatível com um número limitado de cenários. Para obter mais informações sobre a dica de consulta QUERYTRACEON, consulte https://support.microsoft.com/kb/2801413.
Agora vamos olhar para o problema da chave ascendente, um tópico que expliquei com mais detalhes neste post. A recomendação tradicional da Microsoft para corrigir esse problema é atualizar manualmente as estatísticas após o carregamento dos dados, conforme explicado aqui – que descreve o problema da seguinte maneira:
Estatísticas em colunas de chave crescentes ou decrescentes, como IDENTITY ou colunas de carimbo de data/hora em tempo real, podem exigir atualizações de estatísticas mais frequentes do que as executadas pelo otimizador de consulta. As operações de inserção acrescentam novos valores às colunas ascendentes ou descendentes. O número de linhas adicionadas pode ser muito pequeno para acionar uma atualização de estatísticas. Se as estatísticas não estiverem atualizadas e as consultas forem selecionadas nas linhas adicionadas mais recentemente, as estatísticas atuais não terão estimativas de cardinalidade para esses novos valores. Isso pode resultar em estimativas de cardinalidade imprecisas e desempenho de consulta lento. Por exemplo, uma consulta que seleciona a partir das datas de pedidos de vendas mais recentes terá estimativas de cardinalidade imprecisas se as estatísticas não forem atualizadas para incluir estimativas de cardinalidade para as datas de pedidos de vendas mais recentes.
A recomendação em meu artigo foi usar os sinalizadores de rastreamento 2389 e 2390, que foram publicados pela primeira vez por Ian Jose em seu artigo Ascending Keys and Auto Quick Corrected Statistics. Você pode ler meu artigo para obter uma explicação e um exemplo sobre como usar esses sinalizadores de rastreamento para evitar esse problema. Esses sinalizadores de rastreamento ainda funcionam no SQL Server 2014 CTP2. Mas ainda melhor, eles não são mais necessários se você estiver usando o novo estimador de cardinalidade.
Usando o mesmo exemplo no meu post:
CREATE TABLE dbo.SalesOrderHeader (
SalesOrderID int NOT NULL,
RevisionNumber tinyint NOT NULL,
OrderDate datetime NOT NULL,
DueDate datetime NOT NULL,
ShipDate datetime NULL,
Status tinyint NOT NULL,
OnlineOrderFlag dbo.Flag NOT NULL,
SalesOrderNumber nvarchar(25) NOT NULL,
PurchaseOrderNumber dbo.OrderNumber NULL,
AccountNumber dbo.AccountNumber NULL,
CustomerID int NOT NULL,
SalesPersonID int NULL,
TerritoryID int NULL,
BillToAddressID int NOT NULL,
ShipToAddressID int NOT NULL,
ShipMethodID int NOT NULL,
CreditCardID int NULL,
CreditCardApprovalCode varchar(15) NULL,
CurrencyRateID int NULL,
SubTotal money NOT NULL,
TaxAmt money NOT NULL,
Freight money NOT NULL,
TotalDue money NOT NULL,
Comment nvarchar(128) NULL,
rowguid uniqueidentifier NOT NULL,
ModifiedDate datetime NOT NULL
); Insira alguns dados:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate < '2008-07-20 00:00:00.000'; CREATE INDEX IX_OrderDate ON SalesOrderHeader(OrderDate);
Desde que criamos um índice temos apenas novas estatísticas. A execução da consulta a seguir criará uma boa estimativa de 35 linhas:
SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-19 00:00:00.000';
Se inserirmos novos dados:
INSERT INTO dbo.SalesOrderHeader SELECT * FROM Sales.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
Você pode ver a estimativa com o antigo estimador de cardinalidade, conforme mostrado a seguir:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 110; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';

Como o pequeno número de registros inseridos não foi suficiente para acionar uma atualização automática do objeto de estatísticas, o histograma atual não reconhece os novos registros adicionados e o otimizador de consultas usa uma estimativa de 1 linha. Opcionalmente, você pode usar os sinalizadores de rastreamento 2389 e 2390 para ajudar a obter uma estimativa melhor. Mas se você tentar a mesma consulta com o novo estimador de cardinalidade, obterá a seguinte estimativa:
ALTER DATABASE AdventureWorks2012 SET COMPATIBILITY_LEVEL = 120; GO SELECT * FROM dbo.SalesOrderHeader WHERE OrderDate = '2008-07-20 00:00:00.000';
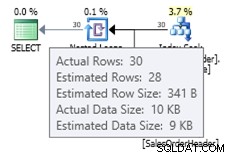
Nesse caso, obtemos uma estimativa melhor do que o antigo estimador de cardinalidade (ou obtemos a mesma estimativa usando os sinalizadores de rastreamento 2389 ou 2390). O valor estimado de 27,9631 (novamente arredondado para 28 pelo Plan Explorer) é calculado usando as informações de densidade do objeto de estatísticas multiplicadas pelo número de linhas da tabela; ou seja, 0,0008992806 * 31095. O valor da densidade pode ser obtido usando:
DBCC SHOW_STATISTICS('dbo.SalesOrderHeader', 'IX_OrderDate'); Por fim, lembre-se de que nada mencionado neste artigo está documentado e esse é o comportamento que observei até agora no SQL Server 2014 CTP2. Tudo isso pode mudar em uma versão CTP ou RTM posterior do produto.