A replicação híbrida, ou seja, combinando o Galera e a replicação assíncrona do MySQL na mesma configuração, tornou-se muito mais fácil desde que o GTID foi introduzido no MySQL 5.6. Embora fosse bastante simples replicar de um servidor MySQL autônomo para um Galera Cluster, fazer o contrário (Galera → MySQL autônomo) era um pouco mais desafiador. Pelo menos até a chegada do GTID.
Existem algumas boas razões para anexar um escravo assíncrono a um Galera Cluster. Por um lado, consultas do tipo OLAP/relatórios de longa execução em um nó Galera podem diminuir a velocidade de um cluster inteiro, se a carga de relatórios for tão intensa que o nó tenha que gastar um esforço considerável para lidar com isso. Assim, as consultas de relatórios podem ser enviadas para um servidor autônomo, isolando efetivamente o Galera da carga de relatórios. Em uma abordagem de cintos e suspensórios, um escravo assíncrono também pode servir como um backup remoto ao vivo.
Nesta postagem do blog, mostraremos como replicar um Galera Cluster para um servidor MySQL com GTID e como fazer failover da replicação caso o nó mestre falhe.
Replicação híbrida no MySQL 5.5
No MySQL 5.5, retomar uma replicação quebrada requer que você determine o último arquivo de log binário e a posição, que são distintos em todos os nós Galera se o log binário estiver habilitado. Podemos ilustrar essa situação com a figura a seguir:
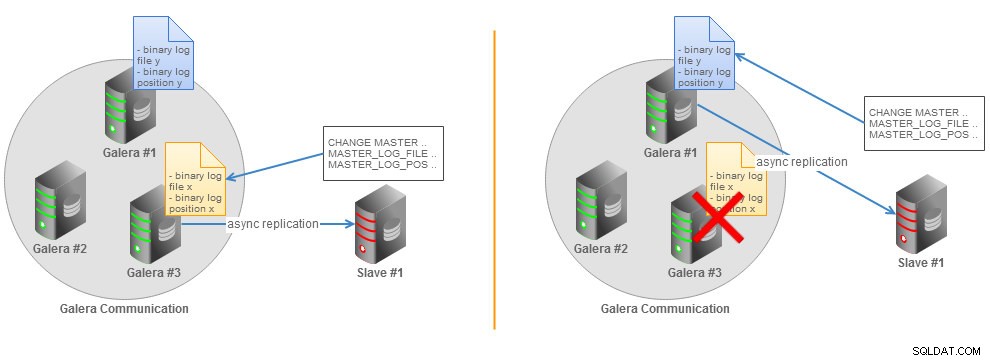 Topologia slave assíncrona de cluster Galera sem GTID
Topologia slave assíncrona de cluster Galera sem GTID Se o mestre MySQL falhar, a replicação será interrompida e o escravo precisará mudar para outro mestre. Você precisará escolher um novo nó Galera e determinar manualmente um novo arquivo de log binário e a posição da última transação executada pelo escravo. Outra opção é despejar os dados do novo nó mestre, restaurá-los no escravo e iniciar a replicação com o novo nó mestre. Essas opções são obviamente factíveis, mas não muito práticas na produção.
Como o GTID resolve o problema
GTID (Global Transaction Identifier) fornece um melhor mapeamento de transações entre nós e é suportado no MySQL 5.6. No Galera Cluster, todos os nós irão gerar diferentes arquivos binlog. Os eventos de log binário são os mesmos e na mesma ordem, mas os nomes e os deslocamentos dos arquivos de log binário podem variar. Com o GTID, os escravos podem ver uma única transação vinda de vários mestres e isso pode ser facilmente mapeado na lista de execução do escravo se precisar reiniciar ou retomar a replicação.
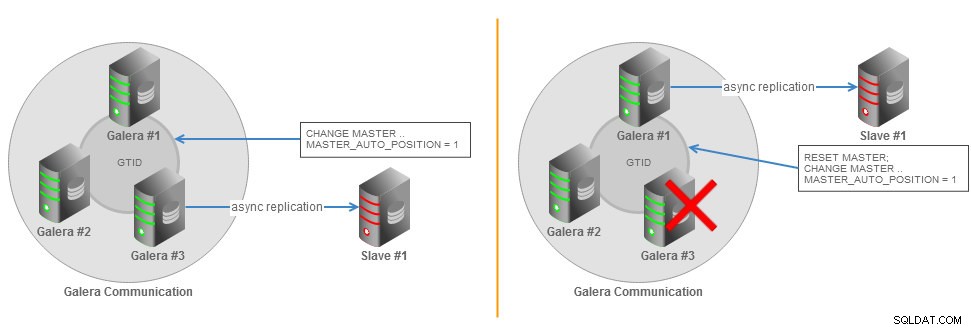 Topologia escravo assíncrona de cluster Galera com failover GTID
Topologia escravo assíncrona de cluster Galera com failover GTID Todas as informações necessárias para a sincronização com o mestre são obtidas diretamente do fluxo de replicação. Isso significa que, ao usar GTIDs para replicação, você não precisa incluir as opções MASTER_LOG_FILE ou MASTER_LOG_POS na instrução CHANGE MASTER TO. Em vez disso, é necessário apenas habilitar a opção MASTER_AUTO_POSITION. Você pode encontrar mais detalhes sobre o GTID na página de documentação do MySQL.
Configurando a replicação híbrida manualmente
Certifique-se de que os nós Galera (mestres) e escravos estejam rodando no MySQL 5.6 antes de prosseguir com esta configuração. Temos um banco de dados chamado sbtest no Galera, que iremos replicar para o nó escravo.
1. Habilite as opções de replicação necessárias especificando as seguintes linhas dentro do my.cnf de cada nó de banco de dados (incluindo o nó escravo):
Para nós mestres (Galera):
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=1 # 1 for master1, 2 for master2, 3 for master3
binlog_format=ROWPara nó escravo:
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=101 # 101 for slave
binlog_format=ROW
replicate_do_db=sbtest
slave_net_timeout=602. Execute uma reinicialização contínua de cluster do Galera Cluster (a partir da UI do ClusterControl> Gerenciar> Atualizar> Reinicialização contínua). Isso recarregará cada nó com as novas configurações e habilitará o GTID. Reinicie o escravo também.
3. Crie um usuário de replicação escravo e execute a seguinte instrução em um dos nós do Galera:
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slavepassword';4. Faça login no slave e faça dump do banco de dados sbtest de um dos nós Galera:
$ mysqldump -uroot -p -h192.168.0.201 --single-transaction --skip-add-locks --triggers --routines --events sbtest > sbtest.sql5. Restaure o arquivo de despejo no servidor escravo:
$ mysql -uroot -p < sbtest.sql6. Inicie a replicação no nó escravo:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.201', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Para verificar se a replicação está funcionando corretamente, examine a saída do status do escravo:
mysql> SHOW SLAVE STATUS\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...Configurando a replicação híbrida usando o ClusterControl
No parágrafo anterior descrevemos todos os passos necessários para habilitar os logs binários, reiniciar o cluster nó por nó, copiar os dados e então configurar a replicação. O procedimento é uma tarefa tediosa e você pode facilmente cometer erros em uma dessas etapas. No ClusterControl automatizamos todos os passos necessários.
1. Para usuários do ClusterControl, você pode acessar os nós na página Nós e habilitar o log binário.
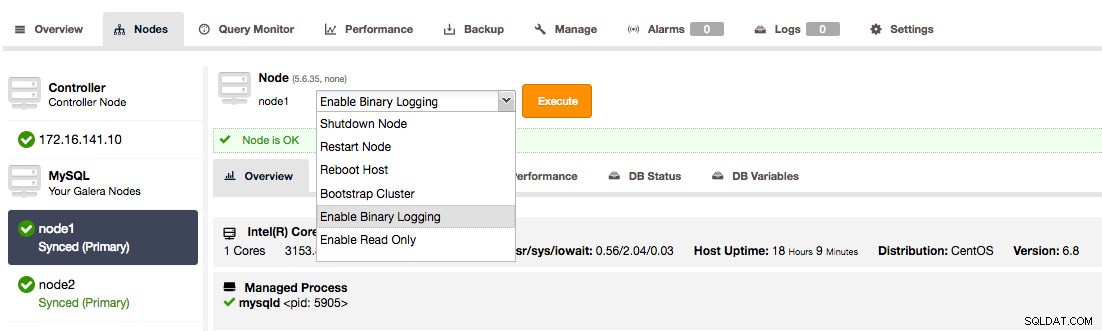 Ativar log binário no cluster Galera usando ClusterControl
Ativar log binário no cluster Galera usando ClusterControl Isso abrirá uma caixa de diálogo que permite definir a expiração do log binário, habilitar o GTID e reiniciar automaticamente.
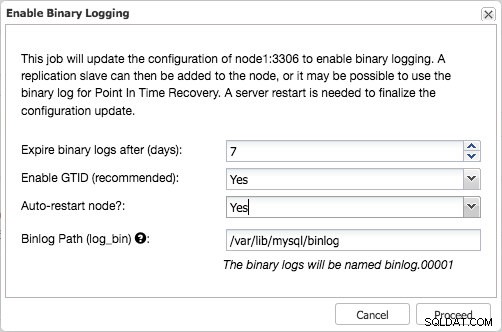 Ativar log binário com GTID ativado
Ativar log binário com GTID ativado Isso inicia um trabalho, que gravará com segurança essas alterações na configuração, criará usuários de replicação com as concessões adequadas e reiniciará o nó com segurança.
 Descrição da foto
Descrição da foto Repita esse processo para cada nó Galera no cluster, até que todos os nós indiquem que são mestres.
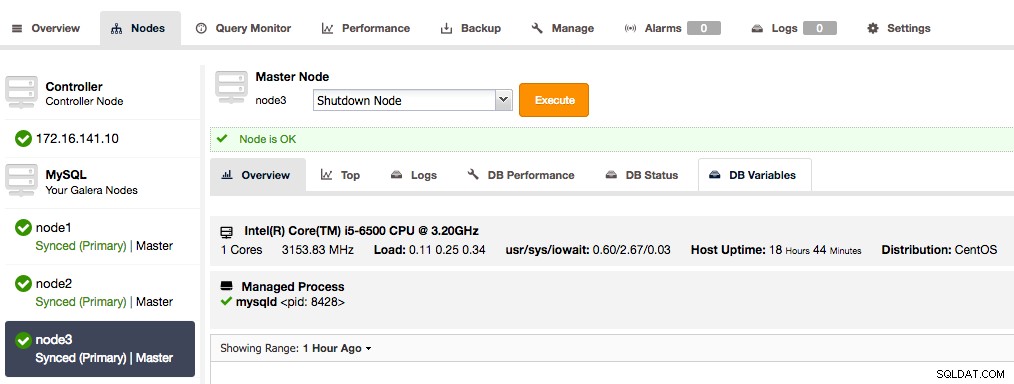 Todos os nós do Galera Cluster agora são mestres
Todos os nós do Galera Cluster agora são mestres 2. Adicione o escravo de replicação assíncrona ao cluster
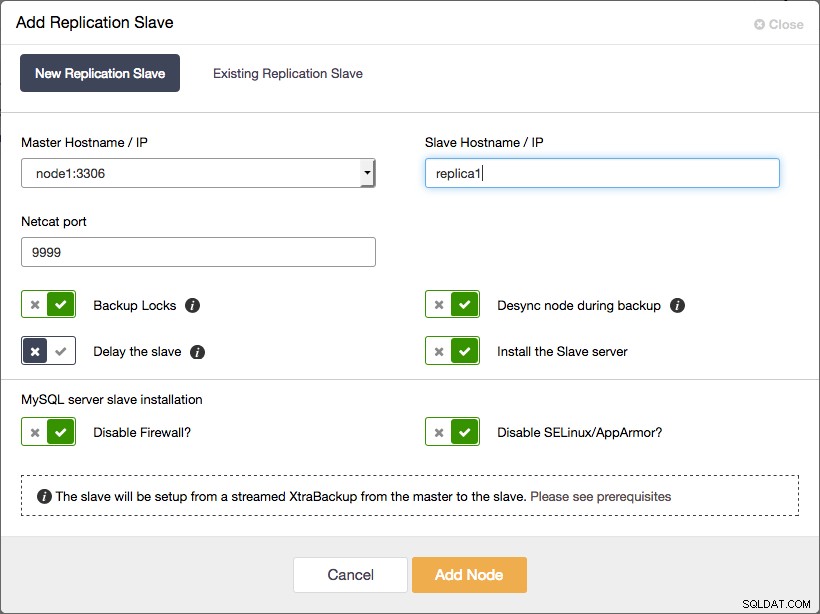 Adicionar um escravo de replicação assíncrona ao Galera Cluster usando ClusterControl
Adicionar um escravo de replicação assíncrona ao Galera Cluster usando ClusterControl E isso é tudo que você tem que fazer. Todo o processo descrito no parágrafo anterior foi automatizado pelo ClusterControl.
Alterando Mestre
Se o mestre designado cair, o escravo tentará se reconectar novamente no valor slave_net_timeout (nossa configuração é 60 segundos - o padrão é 1 hora). Você deve ver o seguinte erro no status do escravo:
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 1Como estamos usando Galera com GTID habilitado, o failover mestre é suportado via ClusterControl quando Recuperação automática de cluster e nó foi habilitado. Se o mestre falhar devido à conectividade de rede ou por qualquer outro motivo, o ClusterControl fará automaticamente o failover para o outro nó mestre mais adequado no cluster.
Se você deseja realizar o failover manualmente, basta alterar o nó mestre da seguinte forma:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Em alguns casos, você pode encontrar um erro “Duplicate entry .. for key” após a alteração do nó mestre:
Last_Errno: 1062
Last_Error: Could not execute Write_rows event on table sbtest.sbtest; Duplicate entry '1089775' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysqld-bin.000009, end_log_pos 85789000Em versões mais antigas do MySQL, você pode simplesmente usar SET GLOBAL SQL_SLAVE_SKIP_COUNTER =n para pular instruções, mas não funciona com GTID. Miguel de Percona escreveu um ótimo post no blog sobre como consertar isso injetando transações vazias.
Outra abordagem, para bancos de dados menores, também poderia ser apenas obter um novo dump de qualquer um dos nós Galera disponíveis, restaurá-lo e usar a instrução RESET MASTER:
mysql> STOP SLAVE;
mysql> RESET MASTER;
mysql> DROP SCHEMA sbtest; CREATE SCHEMA sbtest; USE sbtest;
mysql> SOURCE /root/sbtest_from_galera2.sql; -- repeat step #4 above to get this dump
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Você também pode usar pt-table-checksum para verificar a integridade da replicação, mais informações nesta postagem do blog.
Nota:Como na replicação do MySQL o aplicador escravo é, por padrão, ainda single-thread, não espere que o desempenho da replicação assíncrona seja o mesmo da replicação paralela do Galera. Para MySQL 5.6 e 5.7 existem opções para fazer a replicação assíncrona executada em paralelo nos nós escravos, mas em princípio esta replicação ainda depende da ordem correta das transações dentro do mesmo esquema para acontecer. Se a carga de replicação for intensa e contínua, o atraso do escravo continuará crescendo. Vimos casos em que o escravo nunca conseguiu alcançar o mestre.