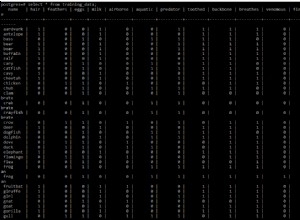
O MySQL escolhe uma linha arbitrariamente. Na prática, os mecanismos de armazenamento MySQL comumente usados retornam os valores do primeiro linha no grupo, em relação ao armazenamento físico.
create table foo (id serial primary key, category varchar(10));
insert into foo (category) values
('foo'), ('foo'), ('foo'), ('bar'), ('bar'), ('bar');
select * from foo group by category;
+----+----------+
| id | category |
+----+----------+
| 4 | bar |
| 1 | foo |
+----+----------+
Outras pessoas estão corretas que o MySQL permite que você execute esta consulta mesmo que tenha resultados arbitrários e potencialmente enganosos. O padrão SQL e a maioria dos outros fornecedores de RDBMS não permitem esse tipo de consulta GROUP BY ambígua. Isso é chamado de Regra de valor único :todas as colunas na lista de seleção devem fazer parte explicitamente dos critérios GROUP BY, ou então dentro de uma função agregada, por exemplo
COUNT() , MAX() , etc MySQL suporta um modo SQL
ONLY_FULL_GROUP_BY
que faz o MySQL retornar um erro se você tentar executar uma consulta que viole a semântica padrão do SQL. AFAIK, SQLite é o único outro RDBMS que permite colunas ambíguas em uma consulta agrupada. SQLite retorna valores do último linha no grupo:
select * from foo group by category;
6|bar
3|foo
Podemos imaginar consultas que não seriam ambíguas, mas ainda assim violariam a semântica padrão do SQL.
SELECT foo.*, parent_of_foo.*
FROM foo JOIN parent_of_foo
ON (foo.parent_id = parent_of_foo.parent_id)
GROUP BY foo_id;
Não há nenhuma maneira lógica de produzir resultados ambíguos. Cada linha em foo recebe seu próprio grupo, se GROUP BY a chave primária de foo. Portanto, qualquer coluna de foo pode ter apenas um valor no grupo. Mesmo ingressar em outra tabela referenciada por uma chave estrangeira em foo pode ter apenas um valor por grupo, se os grupos forem definidos pela chave primária de foo.
MySQL e SQLite confiam em você para projetar consultas logicamente inequívocas. Formalmente, cada coluna na lista de seleção deve ser uma dependência funcional das colunas nos critérios GROUP BY. Se você não aderir a isso, a culpa é sua. :-)
O SQL padrão é mais estrito e não permite algumas consultas que poderiam ser inequívoco - provavelmente porque seria muito complexo para o RDBMS ter certeza em geral.