Este é o segundo artigo de uma série de artigos sobre OLTP na memória do SQL Server.
O artigo introdutório — SQL Server In-Memory OLTP, apresentou brevemente os conceitos básicos do novo mecanismo Hekaton. Nesta parte, vamos nos concentrar na prática. Para ser mais específico, veremos como criar bancos de dados e tabelas otimizados In-Memory e também como avaliá-los com a ajuda do T-SQL.
Pré-requisitos para começar a usar bancos de dados com otimização de memória
O OLTP na memória é instalado automaticamente com uma edição Enterprise ou Developer de 64 bits do SQL Server 2014 ou SQL Server 2016. A edição de 32 bits do SQL Server não fornece componentes OLTP na memória.
Assim, se você tiver a edição Developer de 64 bits do SQL Server instalada em seu computador, poderá começar a criar bancos de dados e estruturas de dados que armazenarão dados com otimização de memória sem configuração de adições.
Cada banco de dados que contém tabelas com otimização de memória deve conter um grupo de arquivos MEMORY_OPTIMIZED_DATA. Este grupo de arquivos contém um ou vários contêineres. Cada contêiner armazena dados e/ou arquivos delta. O SQL Server usa esses arquivos para recuperar as tabelas com otimização de memória. Os contêineres podem ser colocados em diferentes matrizes de disco,
de maneira semelhante aos grupos de arquivos FILESTREAM.
A sintaxe para criar um grupo de arquivos com otimização de memória é quase a mesma de um grupo de arquivos FILESTREAM tradicional, com várias diferenças:
- Apenas um grupo de arquivos com otimização de memória pode ser criado para um banco de dados.
- A opção CONTAINS MEMORY_OPTIMIZED_DATA deve ser especificada explicitamente.
Você pode criar o grupo de arquivos no processo de criação de um banco de dados:
CREATE DATABASE InMemoryDemo ON PRIMARY ( NAME = N'InMemoryDemo', FILENAME = N'D:\Data\InMemoryOLTPDemo.mdf' ), FILEGROUP IMOFG CONTAINS MEMORY_OPTIMIZED_DATA ( NAME = N'InMemoryDemo_Data', FILENAME = N'D:\IMOFG\InMemoryDemo_Data.mdf' )
Como alternativa, você pode adicionar o grupo de arquivos MEMORY_OPTIMIZED_DATA a um banco de dados existente e, em seguida, adicionar arquivos a esse grupo de arquivos.
-- Adding the containers ALTER DATABASE DemoDB ADD FILE ( NAME = 'DemoDB_Mod', FILENAME = 'D:\Data\DemoDB_Mod' ) TO FILEGROUP DemoDB_Mod
Internamente, o OLTP In-Memory usa um mecanismo de streaming baseado na tecnologia FILESTREAM, que é bem adaptado para acesso de E/S sequencial.
Criando tabelas com otimização de memória
Agora, temos tudo o que precisamos para começar a criar objetos com otimização de memória. Vamos criar uma tabela com otimização de memória.
A sintaxe para criar tabelas otimizadas na memória é muito semelhante a uma para criar tabelas baseadas em disco. No entanto, existem algumas extensões e restrições:
- A cláusula MEMORY_OPTIMIZED =ON identifica uma tabela como otimizada na memória.
- As tabelas otimizadas na memória não são compatíveis com todos os tipos de dados compatíveis com as tabelas tradicionais. Os seguintes tipos de dados não são suportados:
- deslocamento de data e hora
- geografia
- geometria
- hierarquia
- versão de linha
- XML
- sql_variant
- Tipos definidos pelo usuário
Uma tabela com otimização de memória pode ser criada com os seguintes valores de durabilidade:SCHEMA_AND_DATA ou SCHEMA_ONLY. SCHEMA_AND_DATA é o valor padrão.
Caso você especifique SCHEMA_ONLY, todas as alterações na tabela não serão registradas e os dados da tabela não serão armazenados no disco.
Cada tabela com otimização de memória deve conter pelo menos um índice. Observe que a restrição PRIMARY KEY cria implicitamente um índice. Uma tabela com otimização de memória durável sempre requer uma restrição PRIMARY KEY.
CREATE TABLE dbo.Person ( [Name] VARCHAR(32) NOT NULL PRIMARY KEY NONCLUSTERED ,[City] VARCHAR(32) NULL ,[Country] VARCHAR(32) NULL ,[State_Province] VARCHAR(32) NULL ,[LastModified] DATETIME NOT NULL ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Índices compostos podem ser adicionados quando todas as colunas tiverem sido criadas:
CREATE TABLE dbo.Person ( [Name] VARCHAR(32) NOT NULL PRIMARY KEY NONCLUSTERED ,[City] VARCHAR(32) NULL ,[Country] VARCHAR(32) NULL ,[State_Province] VARCHAR(32) NULL ,[LastModified] DATETIME NOT NULL ,INDEX T1_INDX_C1C2 NONCLUSTERED ([Name], [City]) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA);
Quando você cria a tabela otimizada na memória, o mecanismo OLTP na memória cria rotinas DML para poder acessar essa tabela. Ele carrega rotinas como arquivos DLL. Para uma operação específica, o SQL Server chama um arquivo DLL necessário.
Alterando tabelas e índices
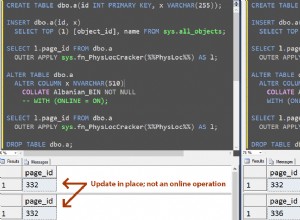
Era impossível ALTERAR tabelas antes do SQL Server 2016. Para fazer alterações no esquema, você precisava descartar e recriar a tabela na memória.
Na nova versão do SQL Server, ALTER TABLE é parcialmente suportado.
O SQL Server 2016 oferece a capacidade de realizar operações off-line:adicionar e descartar (modificar) colunas, índices e restrições. Além disso, agora é possível trabalhar com tabelas na memória usando o designer de tabelas SSMS ou o editor de tabelas dbForge Studio for SQL Server.
Observe que ALTER TABLE requer a reconstrução da tabela. É por isso que você precisa ter certeza de que tem memória suficiente antes de executar esta operação. Durante a operação de reconstrução, cada linha é reinserida na nova tabela e a tabela não fica disponível enquanto a operação ALTER está sendo executada.
Você pode introduzir várias alterações em uma única tabela e combiná-las em uma única instrução ALTER TABLE. Você pode ADICIONAR colunas, índices e restrições e pode DROP colunas, índices e restrições. Observe que você não pode combinar os comandos ADD e DROP em uma única ALTER TABLE.
-- index operations -- change hash index bucket count ALTER TABLE dbo.TableName ALTER INDEX IX_Name REBUILD WITH (BUCKET_COUNT = 131072); GO -- add index ALTER TABLE dbo.TableName ADD INDEX IX_Name NONCLUSTERED (ColName); GO -- drop index ALTER TABLE dbo.TableName DROP INDEX IX_Name; GO -- add multiple indexes ALTER TABLE dbo.TableName ADD INDEX IX_Name NONCLUSTERED (ColName), INDEX IX_Name2 NONCLUSTERED (ColName2); GO -- Add a new column and an index ALTER TABLE dbo.TableName ADD Date DATETIME, INDEX IX_Name NONCLUSTERED (ColName); GO -- Drop a column ALTER TABLE dbo.TableName DROP COLUMN ColName; GO
Tipos de tabela e variáveis de tabela
O SQL Server 2016 oferece a capacidade de criar tipos de tabela com otimização de memória que você pode usar ao definir uma variável de tabela:
CREATE TYPE TypeName AS TABLE ( Col1 SMALLINT NOT NULL, Col2 INT NOT NULL, Col3 INT NOT NULL, Col4 INT NOT NULL, INDEX IX_Col1 NONCLUSTERED HASH (Col1) WITH (BUCKET_COUNT = 131072), INDEX IX_Col1 NONCLUSTERED (Col2)) WITH (MEMORY_OPTIMIZED = ON); GO DECLARE @VariableName TypeName; GO
Esta variável é armazenada apenas na memória. Tabelas e tipos de tabela otimizados na memória usam as mesmas estruturas de dados, portanto, o acesso aos dados será mais eficiente em comparação com as variáveis de tabela baseadas em disco.
Para obter mais detalhes, consulte a seguinte postagem de blog do MSDN:Melhorando o desempenho da tabela temporária e da variável de tabela usando a otimização de memória
Resumo
O OLTP In-Memory é uma tecnologia relativamente jovem projetada para funcionar com sistemas OLTP enormes e muito ocupados que suportam centenas ou mesmo milhares de usuários simultâneos. Ele foi introduzido no SQL Server 2014 e evoluiu no SQL Server 2016.
Ao mesmo tempo, a tecnologia contém uma série de restrições e limitações.
Nem todos os recursos e tipos de dados T-SQL suportados por memória- tabelas otimizadas, tais tabelas não podem conter linhas que excedam 8060 bytes e também não suportam armazenamento
ROW-OVERFLOW e LOB. Você não pode alterar tabelas e índices (no SQL Server 2014), uma vez que a tabela é criada.
Apesar disso, esperamos que versões posteriores do OLTP In-Memory tenham menos limitações!
Leia também:
Usando índices em tabelas com otimização de memória do SQL Server