Leia a pergunta com atenção
E:
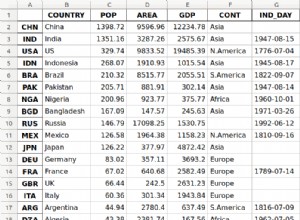
O ponto importante para o desempenho é excluir linhas irrelevantes antecipadamente e computar somente agregações para o subgrupo especificado . Então (assumindo mais do que alguns subgrupos distintos), um índice em
(subgroup) pode ajudar:CREATE INDEX ON foo (subgroup);
Cada uma das consultas a seguir retorna
FALSE se pelo menos dois grupos tiverem somas totais diferentes para o subgrupo fornecido e TRUE em todos outros casos (com uma pequena exceção para a consulta 5, veja abaixo). Consulta 1
SELECT count(DISTINCT total_power) = 1
FROM (
SELECT sum(power) AS total_power
FROM foo
WHERE subgroup = 'Sub_B' -- exclude irrelevant rows early!
GROUP BY grp
) sub;
Consulta 2
SELECT count(*) = 1
FROM (
SELECT true
FROM (
SELECT sum(power) AS total_power
FROM foo
WHERE subgroup = 'Sub_C'
GROUP BY grp
) sub2
GROUP BY total_power
) sub2;
Consulta 3
SELECT count(*) OVER () = 1
FROM (
SELECT sum(power) AS total_power
FROM foo
WHERE subgroup = 'Sub_A'
GROUP BY grp
) sub
GROUP BY total_power
LIMIT 1;
Consulta 4
(
SELECT FALSE
FROM (
SELECT sum(power) AS total_power
FROM foo
WHERE subgroup = 'Sub_A'
GROUP BY grp
) sub
GROUP BY total_power
OFFSET 1
LIMIT 1
)
UNION ALL
SELECT TRUE
LIMIT 1;
Este é especial. Respostas relacionadas com explicação:
- Devolver um valor se nenhum registro for encontrado
- Como tentar vários SELECTs até que um resultado esteja disponível?
Consulta 5
SELECT min(total_power) = max(total_power) -- can fail for NULL values
FROM (
SELECT sum(power) AS total_power
FROM foo
WHERE subgroup = 'Sub_A'
GROUP BY grp
) sub;
O último pode falhar se
NULL valores em poder são permitidos. (Mas você teria que definir os resultados esperados neste caso de qualquer maneira.) Fiz um teste extensivo e descobriu que todas as consultas executavam o mesmo em condições ideais:
db<>fiddle aqui
A consulta 5 tendia a ser um pouco mais rápida que as demais.