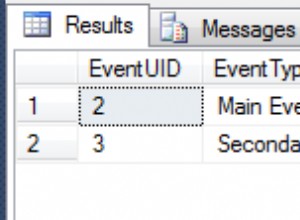
Você precisa de um item de dados por semana e meta (antes de agregar contagens por empresa). Isso é um simples
CROSS JOIN entre generate_series() e goals . A parte (possivelmente) cara é obter o state atual de updates para cada. Curta @Paul já sugeriu
, um LATERAL join parece ser a melhor ferramenta. Faça isso apenas para updates , no entanto, e use uma técnica mais rápida com LIMIT 1 . E simplifique o tratamento de datas com
date_trunc()
. SELECT w_start
, g.company_id
, count(*) FILTER (WHERE u.status = 'green') AS green_count
, count(*) FILTER (WHERE u.status = 'amber') AS amber_count
, count(*) FILTER (WHERE u.status = 'red') AS red_count
FROM generate_series(date_trunc('week', NOW() - interval '2 months')
, date_trunc('week', NOW())
, interval '1 week') w_start
CROSS JOIN goals g
LEFT JOIN LATERAL (
SELECT status
FROM updates
WHERE goal_id = g.id
AND created_at < w_start
ORDER BY created_at DESC
LIMIT 1
) u ON true
GROUP BY w_start, g.company_id
ORDER BY w_start, g.company_id;
Para tornar isso rápido você precisa de um índice de várias colunas :
CREATE INDEX updates_special_idx ON updates (goal_id, created_at DESC, status);
Ordem decrescente para
created_at é o melhor, mas não estritamente necessário. O Postgres pode escanear índices para trás quase com a mesma rapidez. ( No entanto, não se aplica à ordem de classificação invertida de várias colunas.
) Colunas de índice naquele ordem. Por quê?
E a terceira coluna
status é anexado apenas para permitir varreduras somente de índice
rápidas em updates . Caso relacionado:1k metas por 9 semanas (seu intervalo de 2 meses se sobrepõe com pelo menos 9 semanas) requer apenas 9k pesquisas de índice para a 2ª tabela de apenas 1k linhas. Para tabelas pequenas como esta, o desempenho não deve ser um grande problema. Mas uma vez que você tenha mais alguns milhares em cada tabela, o desempenho se deteriorará com varreduras sequenciais.
w_start representa o início de cada semana. Consequentemente, as contagens são para o início da semana. Você pode ainda extrair ano e semana (ou qualquer outro detalhe representa sua semana), se você insistir: EXTRACT(isoyear from w_start) AS year
, EXTRACT(week from w_start) AS week
Melhor com
ISOYEAR
, como @Paul explicou. SQL Fiddle.
Relacionado:
- Qual é a diferença entre LATERAL e uma subconsulta no PostgreSQL?
- Otimize a consulta GROUP BY para recuperar o registro mais recente por usuário
- Selecione primeiro linha em cada grupo GROUP BY?
- PostgreSQL:contagem de linhas em execução para uma consulta 'por minuto'