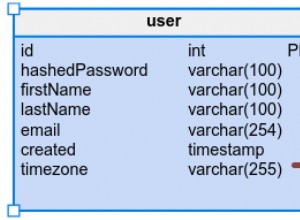
Índices
Crie índices em
x.id e y.id - que você provavelmente já tem se essas forem suas chaves primárias.Um índice de várias colunas também pode ajudar, especialmente com scans somente de índice na página 9.2+:
CREATE INDEX y_mult_idx ON y (id DESC, val)
No entanto, em meus testes, esse índice não foi usado inicialmente. Tive que adicionar (de outra forma inútil)
val para ORDER BY para convencer o planejador de consultas de que a ordem de classificação corresponde. Consulte a consulta 3 . O índice faz pouca diferença nesta configuração sintética. Mas para tabelas com mais colunas, recuperando
val da tabela torna-se cada vez mais caro, tornando o índice de "cobertura" mais atrativo. Consultas
1) Simples
SELECT DISTINCT ON (x.id)
x.id, y.val
FROM x
JOIN y ON y.id <= x.id
ORDER BY x.id, y.id DESC;
SQL Fiddle.
Mais explicações para a técnica com
DISTINCT nesta resposta relacionada:Fiz alguns testes porque tinha minhas suspeitas de que a primeira consulta não seria bem dimensionada. É rápido com uma mesa pequena, mas não é bom com mesas maiores. O Postgres não otimiza o plano e começa com uma junção cruzada (limitada), com um custo de
O(N²) . 2) Rápido
Esta consulta ainda é bastante simples e escala excelentemente:
SELECT x.id, y.val
FROM x
JOIN (SELECT *, lead(id, 1, 2147483647) OVER (ORDER BY id) AS next_id FROM y) y
ON x.id >= y.id
AND x.id < y.next_id
ORDER BY 1;
A função de janela
lead()
é instrumental. Eu uso a opção de fornecer um padrão para cobrir a caixa de canto da última linha:2147483647 é o maior inteiro possível
. Adapte-se ao seu tipo de dados. 3) Muito simples e quase tão rápido
SELECT x.id
,(SELECT val FROM y WHERE id <= x.id ORDER BY id DESC, val LIMIT 1) AS val
FROM x;Normalmente, subconsultas correlacionadas tendem a ser lentos. Mas este pode apenas escolher um valor do índice (de cobertura) e é tão simples que pode competir.
O
ORDER BY adicional item val (ênfase em negrito) parece inútil. Mas adicioná-lo convence o planejador de consultas de que não há problema em usar o índice de várias colunas y_mult_idx de cima, porque a ordem de classificação corresponde. Note o no
EXPLAIN resultado. Caso de teste
Após um debate animado e várias atualizações, coletei todas as consultas postadas até agora e fiz um caso de teste para uma visão geral rápida. Eu uso apenas 1000 linhas para que o SQLfiddle não atinja o tempo limite com as consultas mais lentas. Mas os 4 primeiros (Erwin 2, Clodoaldo, a_horse, Erwin 3) escalam linearmente em todos os meus testes locais. Atualizado mais uma vez para incluir minha última adição, melhorar o formato e ordenar por desempenho agora:
Big SQL Fiddle comparando o desempenho.