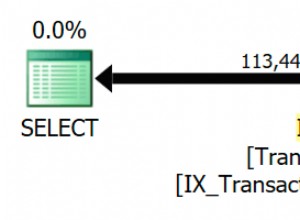
Confirmei que o índice funciona conforme o esperado.
Eu recriei os dados aleatórios, só que desta vez configurei
diet_glutenfree para random() > 0.9 então há apenas 10% de chance de um on pedaço. Em seguida, recriei os índices e tentei a consulta novamente.
SELECT RecipeId from RecipeMetadata where diet_glutenfree;
Devoluções:
'Index Scan using idx_recipemetadata_glutenfree on recipemetadata (cost=0.00..135.15 rows=1030 width=16)'
' Index Cond: (diet_glutenfree = true)'
E:
SELECT RecipeId from RecipeMetadata where NOT diet_glutenfree;
Devoluções:
'Seq Scan on recipemetadata (cost=0.00..214.26 rows=8996 width=16)'
' Filter: (NOT diet_glutenfree)'
Parece que minha primeira tentativa foi poluída, pois o PG estima que é mais rápido verificar a tabela inteira em vez de atingir o índice se tiver que carregar mais da metade das linhas de qualquer maneira.
No entanto, acho que obteria esses resultados exatos em um índice completo da coluna. Existe uma maneira de verificar o número de linhas indexadas em um índice parcial?
ATUALIZAÇÃO
O índice é em torno de 40k. Eu criei um índice completo da mesma coluna e tem mais de 200k, então parece que é definitivamente parcial.