Nos últimos meses, nós do 2ndQuadrant temos trabalhado na fusão do PostgreSQL 9.6 no Postgres-XL, o que acabou sendo bastante desafiador por vários motivos e levou mais tempo do que o planejado inicialmente devido a várias mudanças invasivas no upstream. Se você estiver interessado, veja o repositório oficial aqui (veja o branch “master” por enquanto).
Ainda há muito trabalho a ser feito - mesclando alguns bits restantes do upstream, corrigindo bugs conhecidos e falhas de regressão, testes, etc. Se você está pensando em contribuir para o Postgres-XL, esta é uma oportunidade ideal e-mail e eu te ajudo com os primeiros passos).
Mas, no geral, o Postgres-XL 9.6 é claramente um grande passo à frente em várias áreas importantes.
Novos recursos no Postgres-XL 9.6
Então, quais novos recursos o Postgres-XL ganha com a mesclagem do PostgreSQL 9.6? Eu poderia simplesmente apontar para as notas de versão upstream – a maioria das melhorias se aplica diretamente ao XL 9.6, com exceção daquelas relacionadas a recursos não suportados no XL.
A principal melhoria visível ao usuário no PostgreSQL 9.6 foi claramente a consulta paralela, e isso também se aplica ao Postgres-XL 9.6.
Paralelismo intra-nó
Antes do PostgreSQL 9.6, o Postgres-XL era uma das maneiras de obter consultas paralelas (colocando vários nós Postgres-XL na mesma máquina). Desde o PostgreSQL 9.6 isso não é mais necessário, mas também significa que o Postgres-XL ganha capacidade de paralelismo intra-nó.
Para comparação, isso é o que o Postgres-XL 9.5 permitiu que você fizesse – distribuir uma consulta para vários nós de dados, mas cada nó de dados ainda estava sujeito ao limite de “um backend por consulta”, assim como o PostgreSQL simples.
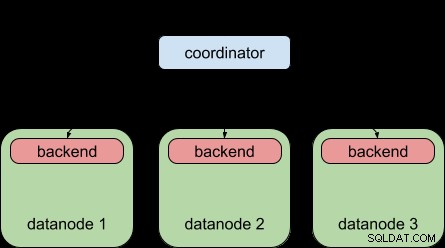
Graças ao recurso de consulta paralela do PostgreSQL 9.6, o Postgres-XL 9.6 agora pode fazer isso:
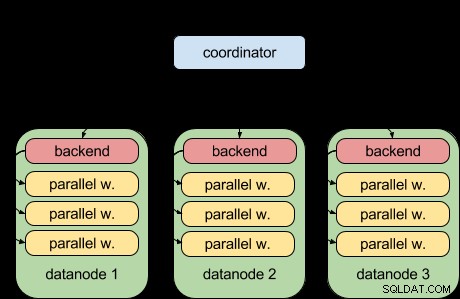
Ou seja, cada nó de dados agora pode executar sua parte da consulta em paralelo, usando a infraestrutura de consulta paralela upstream. Isso é ótimo e torna o Postgres-XL muito mais poderoso quando se trata de cargas de trabalho analíticas.
Manter uma bifurcação
Mencionei que essa fusão acabou sendo mais desafiadora do que esperávamos inicialmente, por vários motivos.
Em primeiro lugar, manter forks em geral é difícil, principalmente quando o projeto upstream está se movendo tão rápido quanto o PostgreSQL. Você precisa desenvolver recursos específicos para o seu fork, e é por isso que os forks existem em primeiro lugar. Mas você também quer acompanhar o upstream, caso contrário, você fica irremediavelmente para trás. É por isso que alguns dos forks existentes ainda estão presos no PostgreSQL 8.x, faltando todos os itens confirmados desde então.
Em segundo lugar, a fusão foi feita em um grande bloco, assim como todos os anteriores (9,5, 9,2, …). Ou seja, todos os commits upstream foram mesclados em um único comando git merge. Isso é bastante garantido para causar muitos conflitos de mesclagem, na medida em que o código nem compila, sem mencionar a execução de testes de regressão ou algo assim.
Portanto, o primeiro lote de correções é para colocá-lo em um estado compilável, o próximo lote é para executá-lo sem falhas de segmentação imediatas e, finalmente, a correção “regular” é iniciada (executar testes de regressão, corrigir problemas, enxaguar e repetir) .
Essas complexidades são inerentes à manutenção do fork (e uma razão pela qual você provavelmente deveria reconsiderar iniciar outro fork e, em vez disso, contribuir diretamente para o Postgres e/ou Postgres-XL).
Mas existem maneiras de reduzir significativamente o impacto – por exemplo, planejamos fazer a próxima mesclagem (com o PostgreSQL 10) em partes menores. Isso deve minimizar a extensão dos conflitos de mesclagem e nos permitir resolver as falhas muito mais rapidamente.
Mais perto do PostgreSQL
Curiosamente, a adoção do paralelismo do upstream também nos permitiu nos livrar de muito código da base de código XL – um excelente exemplo disso é o código agregado paralelo, que substituiu facilmente o código específico do XL.
Outro exemplo de uma mudança upstream que afetou significativamente o código XL é a “patificação” do planejador superior, lançada no final do ciclo de desenvolvimento 9.6. Isso acabou sendo uma mudança muito invasiva (na verdade, vários dos bugs abertos provavelmente estão relacionados a ela), mas no final nos permitiu simplificar o código de planejamento (essencialmente construir caminhos adequados em vez de ajustar o plano resultante).
Quando digo que a mesclagem nos permitiu simplificar o código XL e aproximá-lo do PostgreSQL, o que quero dizer com isso? A maneira mais simples de quantificar a mudança é fazer “git diff –stat” em relação ao branch upstream correspondente e comparar os números. Para as ramificações 9.5 e 9.6, os resultados são assim:
| versão | arquivos alterados | adições | exclusões |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3%) | -33351 (-14,2%) | -709 (-3,8%) |
Claramente, a mesclagem 9.6 reduz significativamente o delta em relação ao upstream (em ~ 14% no total). De onde vem essa diferença?
Em primeiro lugar, parte dessa redução se deve a uma genuína simplificação do código. Um excelente exemplo disso é a agregação paralela, que é praticamente uma substituição 1:1 da implementação original do Postgres-XL. Então, acabamos de tirar isso e usar a implementação upstream. Esperamos encontrar mais lugares assim no futuro e usar a implementação upstream em vez de manter a nossa.
Em segundo lugar, grande parte da redução vem da remoção de código morto. Não apenas reduzimos alguns bits de código mortos/inalcançáveis, como também descobrimos alguns arquivos de origem que nem foram compilados e assim por diante.
O que vem a seguir?
Neste ponto, mesclamos as alterações até b5bce6c1, que é o local onde o PostgreSQL 9.6 se separou do master. Portanto, para acompanhar o PostgreSQL 9.6.2, precisamos mesclar as alterações restantes na ramificação 9.6. Considerando que deve haver principalmente apenas correções de bugs, isso deve ser um trabalho (espero) bastante simples em comparação com a mesclagem completa.
Claro, haverá bugs. Na verdade, ainda existem alguns testes de regressão com falha neste momento. Isso precisa ser corrigido antes de fazer um lançamento oficial do XL 9.6. E precisamos fazer mais testes, então se você estiver interessado em ajudar o Postgres-XL, isso seria extremamente benéfico.
Um aborrecimento que continuamos ouvindo são os pacotes, ou a falta deles. Você deve ter notado que os últimos pacotes disponíveis são bastante antigos, e há apenas .rpm, nada mais. Planejamos resolver isso e começar a oferecer pacotes atualizados em vários sabores (por exemplo, .rpm e .deb).
Também planejamos fazer algumas mudanças na forma como o processo de desenvolvimento é organizado, para facilitar a contribuição e a participação no processo de desenvolvimento. Esse é realmente um tópico separado não relacionado ao branch 9.6, então postarei mais detalhes sobre isso em alguns dias.



