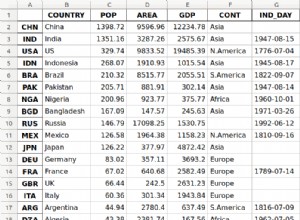
A dificuldade especial desta tarefa:você não pode apenas escolher pontos de dados dentro do seu intervalo de tempo, mas deve considerar os mais recentes ponto de dados antes o intervalo de tempo e o mais cedo ponto de dados depois o intervalo de tempo adicionalmente. Isso varia para cada linha e cada ponto de dados pode ou não existir. Requer uma consulta sofisticada e dificulta o uso de índices.
Você pode usar tipos de intervalo e operadores (Postgres 9.2+ ) para simplificar os cálculos:
WITH input(a,b) AS (SELECT '2013-01-01'::date -- your time frame here
, '2013-01-15'::date) -- inclusive borders
SELECT store_id, product_id
, sum(upper(days) - lower(days)) AS days_in_range
, round(sum(value * (upper(days) - lower(days)))::numeric
/ (SELECT b-a+1 FROM input), 2) AS your_result
, round(sum(value * (upper(days) - lower(days)))::numeric
/ sum(upper(days) - lower(days)), 2) AS my_result
FROM (
SELECT store_id, product_id, value, s.day_range * x.day_range AS days
FROM (
SELECT store_id, product_id, value
, daterange (day, lead(day, 1, now()::date)
OVER (PARTITION BY store_id, product_id ORDER BY day)) AS day_range
FROM stock
) s
JOIN (
SELECT daterange(a, b+1) AS day_range
FROM input
) x ON s.day_range && x.day_range
) sub
GROUP BY 1,2
ORDER BY 1,2;
Observe que eu uso o nome da coluna
day em vez de date . Eu nunca uso nomes de tipos básicos como nomes de colunas. Na subconsulta
sub Eu busco o dia da próxima linha para cada item com a função de janela lead() , usando a opção interna para fornecer "hoje" como padrão onde não há próxima linha.Com isso eu formo um
daterange e combine-o com a entrada com o operador de sobreposição && , calculando o intervalo de datas resultante com o operador de interseção * . Todos os intervalos aqui são com exclusivo borda superior. É por isso que adiciono um dia ao intervalo de entrada. Dessa forma, podemos simplesmente subtrair
lower(range) de upper(range) para obter o número de dias. Presumo que "ontem" seja o último dia com dados confiáveis. "Hoje" ainda pode mudar em uma aplicação da vida real. Conseqüentemente, eu uso "hoje" (
now()::date ) como borda superior exclusiva para intervalos abertos. Apresento dois resultados:
-
your_resultconcorda com os resultados exibidos.
Você divide pelo número de dias em seu intervalo de datas incondicionalmente. Por exemplo, se um item estiver listado apenas no último dia, você obtém uma "média" muito baixa (enganosa!).
-
my_resultcalcula números iguais ou maiores.
Eu divido pelo real número de dias em que um item é listado. Por exemplo, se um item estiver listado apenas para o último dia, devolvo o valor listado como média.
Para entender a diferença, adicionei o número de dias em que o item foi listado:
days_in_range SQL Fiddle .
Índice e desempenho
Para esse tipo de dados, as linhas antigas normalmente não mudam. Isso seria um excelente argumento para uma visão materializada :
CREATE MATERIALIZED VIEW mv_stock AS
SELECT store_id, product_id, value
, daterange (day, lead(day, 1, now()::date) OVER (PARTITION BY store_id, product_id
ORDER BY day)) AS day_range
FROM stock;
Em seguida, você pode adicionar um índice GiST que suporta o operador relevante
&&
:CREATE INDEX mv_stock_range_idx ON mv_stock USING gist (day_range);
Grande caso de teste
Fiz um teste mais realista com 200k linhas. A consulta usando o MV foi cerca de 6 vezes mais rápida, que por sua vez foi ~ 10x mais rápida que a consulta do @Joop. O desempenho depende muito da distribuição de dados. Um MV ajuda mais com grandes tabelas e alta frequência de entradas. Além disso, se a tabela tiver colunas que não sejam relevantes para essa consulta, um MV poderá ser menor. Uma questão de custo versus ganho.
Eu coloquei todas as soluções postadas até agora (e adaptei) em um grande violino para brincar:
SQL Fiddle com grande caso de teste.
SQL Fiddle com apenas 40 mil linhas - para evitar o tempo limite em sqlfiddle.com