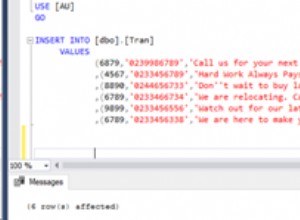
Espero muito resultados mais rápidos com esta abordagem:
1.
Crie um índice GiST com 1 coluna contendo valores concatenados:
CREATE INDEX users_search_idx ON auth_user
USING gist((username || ' ' || first_name || ' ' || last_name) gist_trgm_ops);
Isso pressupõe que todas as 3 colunas sejam definidas
NOT NULL (você não especificou). Caso contrário, você precisa fazer mais.Por que não simplificar com
concat_ws() ? - Combine duas colunas e adicione em uma nova coluna
- Consulta mais rápida com correspondência de padrões em vários campos de texto
- Combine duas colunas e adicione em uma nova coluna
2.
Use um neighbor-neighbor adequado consulta, correspondendo ao índice acima:
SELECT username, email, first_name, last_name
, similarity(username , $1) AS s_username
, similarity(first_name, $1) AS s_first_name
, similarity(last_name , $1) AS s_last_name
, row_number() OVER () AS rank -- greatest similarity first
FROM auth_user
WHERE (username || ' ' || first_name || ' ' || last_name) % $1 -- !!
ORDER BY (username || ' ' || first_name || ' ' || last_name) <-> $1 -- !!
LIMIT $2;
Expressões em
WHERE e ORDER BY deve corresponder à expressão de índice! Em particular
ORDER BY rank (como você teve) sempre terá um desempenho ruim para um pequeno LIMIT escolher de um conjunto muito maior de linhas qualificadas, porque não pode usar um índice diretamente:a expressão sofisticada por trás de rank deve ser calculado para todo linha de qualificação, então todos devem ser classificados antes que a pequena seleção de melhores correspondências possa ser retornada. Isso é muito, muito mais caro do que uma verdadeira consulta de vizinho mais próximo que pode escolher os melhores resultados do índice diretamente sem nem mesmo olhar para o resto. row_number() com definição de janela vazia apenas reflete a ordenação produzida pelo ORDER BY do mesmo SELECT . Respostas relacionadas:
Quanto ao seu item
3. , adicionei uma resposta à pergunta que você fez referência, que deve explicá-la: