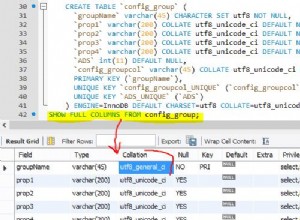
Acho que é por causa de uma “densidade” de registros de mesma chave no disco. Acho que os registros com o mesmo id são armazenados em denso (ou seja, poucos blocos) e aqueles com o mesmo link são armazenados em esparso (ou seja, , distribuído para um grande número de blocos). Se você inseriu registros na ordem de id, essa situação pode acontecer.
Suponha que:1. existem 10.000 registros,2. eles são armazenados na ordem como (id, link) =(1, 1), (1, 2),..., (1, 100), (2, 1)... e3. 50 registros podem ser armazenados em um bloco.
Na suposição acima, o bloco #1~#3 consiste nos registros (1, 1)~(1, 50), (1, 51)~(1, 100) e (2, 1)~(2, 50) respectivamente.
Quando você
SELECT * FROM edges WHERE id=1 , apenas 2 blocos (#1, #2) devem ser carregados e escaneados. Por outro lado, SELECT * FROM edges WHERE link=1 requer 50 blocos (#1, #3, #5,...), mesmo que o número de linhas seja o mesmo.