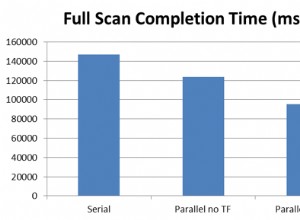
Dói quando você faz isso, então não faça isso.
No Oracle, os cursores são ensinados como parte da programação 101. Em muitos (se não na maioria) casos, os cursores são a primeira coisa que o desenvolvedor Oracle aprende. A primeira classe geralmente começa com:“Existem 13 estruturas lógicas, a primeira das quais é o loop, que é assim…”
O PostgreSQL, por outro lado, não depende muito de cursores. Sim, eles existem. Existem vários sabores de sintaxe para como usá-los. Vou cobrir todos os projetos principais em algum momento desta série de artigos. Mas a primeira lição sobre os cursores do PostgreSQL é que existem algumas (e muito melhores) alternativas algorítmicas ao uso de cursores no PostgreSQL. Na verdade, em uma carreira de 23 anos com o PostgreSQL, só encontrei a necessidade de usar cursores duas vezes. E eu me arrependo de um desses.
Os cursores são um hábito caro.
Iterar é melhor do que fazer loop. “Qual é a diferença?”, você pode perguntar. Bem, a diferença é de cerca de O(N) vs. O(N^2). Ok, eu vou dizer isso novamente em inglês. A complexidade de usar cursores é que eles percorrem conjuntos de dados usando o mesmo padrão de um loop for aninhado. Cada conjunto de dados adicional aumenta a complexidade do total por exponenciação. Isso ocorre porque cada conjunto de dados adicional cria efetivamente outro loop mais interno. Dois conjuntos de dados são O(N^2), três conjuntos de dados são O(N^3) e assim por diante. Adquirir o hábito de usar cursores quando há algoritmos melhores para escolher pode ser caro.
Eles fazem isso sem nenhuma das otimizações que estariam disponíveis para funções de nível inferior do próprio banco de dados. Ou seja, eles não podem usar índices de maneira significativa, não podem se transformar em subseleções, puxar para cima em junções ou usar leituras paralelas. Eles também não se beneficiarão de nenhuma otimização futura que o banco de dados tenha disponível. Espero que você seja um codificador de grande mestre que sempre obtenha o algoritmo correto e o codifique perfeitamente na primeira vez, porque você acabou de derrotar um dos benefícios mais importantes de um banco de dados relacional. Desempenho confiando nas melhores práticas, ou pelo menos no código de outra pessoa.
Todos são melhores que você. Talvez não individualmente, mas coletivamente quase certamente. Além do argumento declarativo versus imperativo, codificar em uma linguagem que é removida uma vez da biblioteca de funções subjacente permite que todos tentem fazer seu código funcionar mais rápido, melhor e mais eficientemente sem consultá-lo. E isso é muito, muito bom para você.
Vamos criar alguns dados para brincar.
Começaremos configurando alguns dados para brincar nos próximos artigos.
Conteúdo de cursors.bash:
set -o nounset # Treat unset variables as an error
# This script assumes that you have PostgreSQL running locally,
# that you have a database with the same name as the local user,
# and that you can create all this structure.
# If not, then:
# sudo -iu postgres createuser -s $USER
# createdb
# Clean up from the last run
[[ -f itisPostgreSql.zip ]] && rm itisPostgreSql.zip
subdirs=$(ls -1 itisPostgreSql* | grep : | sed -e 's/://')
for sub in ${subdirs[@]}
do
rm -rf $sub
done
# Get the newest file
wget https://www.itis.gov/downloads/itisPostgreSql.zip
# Unpack it
unzip itisPostgreSql.zip
# This makes a directory with the stupidest f-ing name possible
# itisPostgreSqlDDMMYY
subdir=$(\ls -1 itisPostgreSql* | grep : | sed -e 's/://')
# The script wants to create an "ITIS" database. Let's just make that a schema.
sed -i $subdir/ITIS.sql -e '/"ITIS"/d' # Cut the lines about making the db
sed -i $subdir/ITIS.sql -e '/-- PostgreSQL database dump/s/.*/CREATE SCHEMA IF NOT EXISTS itis;/'
sed -i $subdir/ITIS.sql -e '/SET search_path = public, pg_catalog;/s/.*/SET search_path TO itis;/'
# ok, we have a schema to put the data in, let's do the import.
# timeout if we can't connect, fail on error.
PG_TIMEOUT=5 psql -v "ON_ERROR_STOP=1" -f $subdir/ITIS.sql
Isso nos dá um pouco mais de 600 mil registros para brincar na tabela itis.hierarchy, que contém uma taxonomia do mundo natural. Usaremos esses dados para ilustrar vários métodos de lidar com interações de dados complexas.
A primeira alternativa.
Meu padrão de design para percorrer conjuntos de registros ao fazer operações caras é o Common Table Expression (CTE).
Aqui está um exemplo do formulário básico:
WITH RECURSIVE fauna AS (
SELECT tsn, parent_tsn, tsn::text taxonomy
FROM itis.hierarchy
WHERE parent_tsn = 0
UNION ALL
SELECT h1.tsn, h1.parent_tsn, f.taxonomy || '.' || h1.tsn
FROM itis.hierarchy h1
JOIN fauna f
ON h1.parent_tsn = f.tsn
)
SELECT *
FROM fauna
ORDER BY taxonomy;
O que produz os seguintes resultados:
┌─────────┬────────┬──────────────────────────────────────────────────────────┐
│ tsn │ parent │ taxonomy │
│ │ tsn │ │
├─────────┼────────┼──────────────────────────────────────────────────────────┤
│ 202422 │ 0 │202422 │
│ 846491 │ 202422 │202422.846491 │
│ 660046 │ 846491 │202422.846491.660046 │
│ 846497 │ 660046 │202422.846491.660046.846497 │
│ 846508 │ 846497 │202422.846491.660046.846497.846508 │
│ 846553 │ 846508 │202422.846491.660046.846497.846508.846553 │
│ 954935 │ 846553 │202422.846491.660046.846497.846508.846553.954935 │
│ 5549 │ 954935 │202422.846491.660046.846497.846508.846553.954935.5549 │
│ 5550 │ 5549 │202422.846491.660046.846497.846508.846553.954935.5549.5550│
│ 954936 │ 846553 │202422.846491.660046.846497.846508.846553.954936 │
│ 954904 │ 660046 │202422.846491.660046.954904 │
│ 846509 │ 954904 │202422.846491.660046.954904.846509 │
│ 11473 │ 846509 │202422.846491.660046.954904.846509.11473 │
│ 11474 │ 11473 │202422.846491.660046.954904.846509.11473.11474 │
│ 11475 │ 11474 │202422.846491.660046.954904.846509.11473.11474.11475 │
│ ... │ │...snip... │
└─────────┴────────┴──────────────────────────────────────────────────────────┘
(601187 rows)
Esta consulta é facilmente modificável para realizar quaisquer cálculos. Isso inclui enriquecimento de dados, funções complexas ou qualquer outra coisa que seu coração deseje.
“Mas olhe!”, você exclama. "Diz
RECURSIVE ali no nome! Não está fazendo exatamente o que você disse para não fazer? Bem, na verdade não. Sob o capô, ele não usa recursão no sentido aninhado ou loop para executar a “recursão”. É apenas uma leitura linear da tabela até que a consulta subordinada não retorne novos resultados. E também funciona com índices. Vejamos o plano de execução:
┌──────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├──────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ Sort (cost=211750.51..211840.16 rows=35858 width=40) │
│ Output: fauna.tsn, fauna.parent_tsn, fauna.taxonomy │
│ Sort Key: fauna.taxonomy │
│ CTE fauna │
│ -> Recursive Union (cost=1000.00..208320.69 rows=35858 width=40) │
│ -> Gather (cost=1000.00..15045.02 rows=18 width=40) │
│ Output: hierarchy.tsn, hierarchy.parent_tsn, ((hierarchy.tsn)::text) │
│ Workers Planned: 2 │
│ -> Parallel Seq Scan on itis.hierarchy (cost=0.00..14043.22 rows=8 width=40) │
│ Output: hierarchy.tsn, hierarchy.parent_tsn, (hierarchy.tsn)::text │
│ Filter: (hierarchy.parent_tsn = 0) │
│ -> Hash Join (cost=5.85..19255.85 rows=3584 width=40) │
│ Output: h1.tsn, h1.parent_tsn, ((f.taxonomy || '.'::text) || (h1.tsn)::text) │
│ Hash Cond: (h1.parent_tsn = f.tsn) │
│ -> Seq Scan on itis.hierarchy h1 (cost=0.00..16923.87 rows=601187 width=8) │
│ Output: h1.hierarchy_string, h1.tsn, h1.parent_tsn, h1.level, h1.childrencount │
│ -> Hash (cost=3.60..3.60 rows=180 width=36) │
│ Output: f.taxonomy, f.tsn │
│ -> WorkTable Scan on fauna f (cost=0.00..3.60 rows=180 width=36) │
│ Output: f.taxonomy, f.tsn │
│ -> CTE Scan on fauna (cost=0.00..717.16 rows=35858 width=40) │
│ Output: fauna.tsn, fauna.parent_tsn, fauna.taxonomy │
│ JIT: │
│ Functions: 13 │
│ Options: Inlining false, Optimization false, Expressions true, Deforming true │
└──────────────────────────────────────────────────────────────────────────────────────────────────────┘
Vamos em frente e criar um índice e ver como isso funciona.
CREATE UNIQUE INDEX taxonomy_parents ON itis.hierarchy (parent_tsn, tsn);
┌─────────────────────────────────────────────────────────────────────────────┐
│ QUERY PLAN │
├─────────────────────────────────────────────────────────────────────────────┤
│Sort (cost=135148.13..135237.77 rows=35858 width=40) │
│ Output: fauna.tsn, fauna.parent_tsn, fauna.taxonomy │
│ Sort Key: fauna.taxonomy │
│ CTE fauna │
│ -> Recursive Union (cost=4.56..131718.31 rows=35858 width=40) │
│ -> Bitmap Heap Scan on itis.hierarchy (cost=4.56..74.69 rows=18) │
│ Output: hierarchy.tsn, hierarchy.parent_tsn, (hierarchy.tsn) │
│ Recheck Cond: (hierarchy.parent_tsn = 0) │
│ -> Bitmap Index Scan on taxonomy_parents │
│ (cost=0.00..4.56 rows=18) │
│ Index Cond: (hierarchy.parent_tsn = 0) │
│ -> Nested Loop (cost=0.42..13092.65 rows=3584 width=40) │
│ Output: h1.tsn, h1.parent_tsn,((f.taxonomy || '.')||(h1.tsn))│
│ -> WorkTable Scan on fauna f (cost=0.00..3.60 rows=180) │
│ Output: f.tsn, f.parent_tsn, f.taxonomy │
│ -> Index Only Scan using taxonomy_parents on itis.hierarchy │
│ h1 (cost=0.42..72.32 rows=20 width=8) │
│ Output: h1.parent_tsn, h1.tsn │
│ Index Cond: (h1.parent_tsn = f.tsn) │
│ -> CTE Scan on fauna (cost=0.00..717.16 rows=35858 width=40) │
│ Output: fauna.tsn, fauna.parent_tsn, fauna.taxonomy │
│JIT: │
│ Functions: 6 │
└─────────────────────────────────────────────────────────────────────────────┘
Bem, isso foi satisfatório, não foi? E teria sido proibitivamente difícil criar um índice em combinação com um cursor para fazer o mesmo trabalho. Essa estrutura nos leva longe o suficiente para poder percorrer uma estrutura de árvore bastante complexa e usá-la para pesquisas simples.
Na próxima parte, falaremos sobre outro método de obter o mesmo resultado ainda mais rápido. Para o nosso próximo artigo, falaremos sobre a extensão ltree e como analisar dados hierárquicos de forma incrivelmente rápida. Fique atento.