Duas sérias vulnerabilidades de segurança (codinome Meltdown e Spectre) foram reveladas há algumas semanas. Os testes iniciais sugeriram que o impacto no desempenho das mitigações (adicionadas no kernel) pode ser de até ~30% para algumas cargas de trabalho, dependendo da taxa de syscall.
Essas estimativas iniciais tiveram que ser feitas rapidamente e, portanto, foram baseadas em quantidades limitadas de testes. Além disso, as correções no kernel evoluíram e melhoraram ao longo do tempo, e agora também temos
retpoline que deve abordar o Spectre v2. Este post apresenta dados de testes mais completos, fornecendo estimativas mais confiáveis para cargas de trabalho típicas do PostgreSQL. Comparado com a avaliação inicial das correções do Meltdown que Simon postou em 10 de janeiro, os dados apresentados neste post são mais detalhados, mas em geral, os resultados das partidas apresentados nesse post.
Esta postagem é focada em cargas de trabalho do PostgreSQL e, embora possa ser útil para outros sistemas com altas taxas de comutação de syscall/contexto, certamente não é de alguma forma universalmente aplicável. Se você estiver interessado em uma explicação mais geral das vulnerabilidades e avaliação de impacto, Brendan Gregg publicou um excelente artigo KPTI/KAISER Meltdown Initial Performance Regressions alguns dias atrás. Na verdade, pode ser útil lê-lo primeiro e depois continuar com este post.
Observação: Esta postagem não pretende desencorajá-lo a instalar as correções, mas dar uma ideia de qual pode ser o impacto no desempenho. Você deve instalar todas as correções para que seu ambiente fique seguro e usar esta postagem para decidir se você precisa atualizar o hardware etc.
Que testes faremos?
Veremos dois tipos de carga de trabalho básicos usuais – OLTP (pequenas transações simples) e OLAP (consultas complexas que processam grandes quantidades de dados). A maioria dos sistemas PostgreSQL pode ser modelada como uma mistura desses dois tipos de carga de trabalho.
Para o OLTP, usamos o pgbench, uma ferramenta de benchmarking bem conhecida fornecida com o PostgreSQL. Testamos tanto em somente leitura (
-S ) e leitura-gravação (-N ), com três escalas diferentes – cabendo em shared_buffers, em RAM e maior que RAM. Para o caso OLAP, usamos o benchmark dbt-3, que é bastante próximo ao TPC-H, com dois tamanhos de dados diferentes – 10 GB que cabe na RAM e 50 GB que é maior que a RAM (considerando índices etc.).
Todos os números apresentados vêm de um servidor com 2x Xeon E5-2620v4, 64GB de RAM e Intel SSD 750 (400GB). O sistema estava rodando o Gentoo com kernel 4.15.3, compilado com GCC 7.3 (necessário para habilitar o
retpoline completo consertar). Os mesmos testes foram realizados também em um sistema mais antigo/menor com CPU i5-2500k, 8 GB de RAM e 6x SSD Intel S3700 (em RAID-0). Mas o comportamento e as conclusões são praticamente os mesmos, então não vamos apresentar os dados aqui. Como de costume, scripts/resultados completos para ambos os sistemas estão disponíveis no github.
Esta postagem é sobre o impacto da mitigação no desempenho, portanto, não vamos nos concentrar em números absolutos e, em vez disso, analisar o desempenho em relação ao sistema não corrigido (sem as mitigações do kernel). Todos os gráficos na seção OLTP mostram
(throughput with patches) / (throughput without patches)
Esperamos números entre 0% e 100%, com valores mais altos sendo melhores (menor impacto das mitigações), 100% significando “sem impacto”.
Observação: O eixo y começa em 75%, para tornar as diferenças mais visíveis.
OLTP/somente leitura
Primeiro, vamos ver os resultados para pgbench somente leitura, executado por este comando
pgbench -n -c 16 -j 16 -S -T 1800 test
e ilustrado pelo gráfico a seguir:
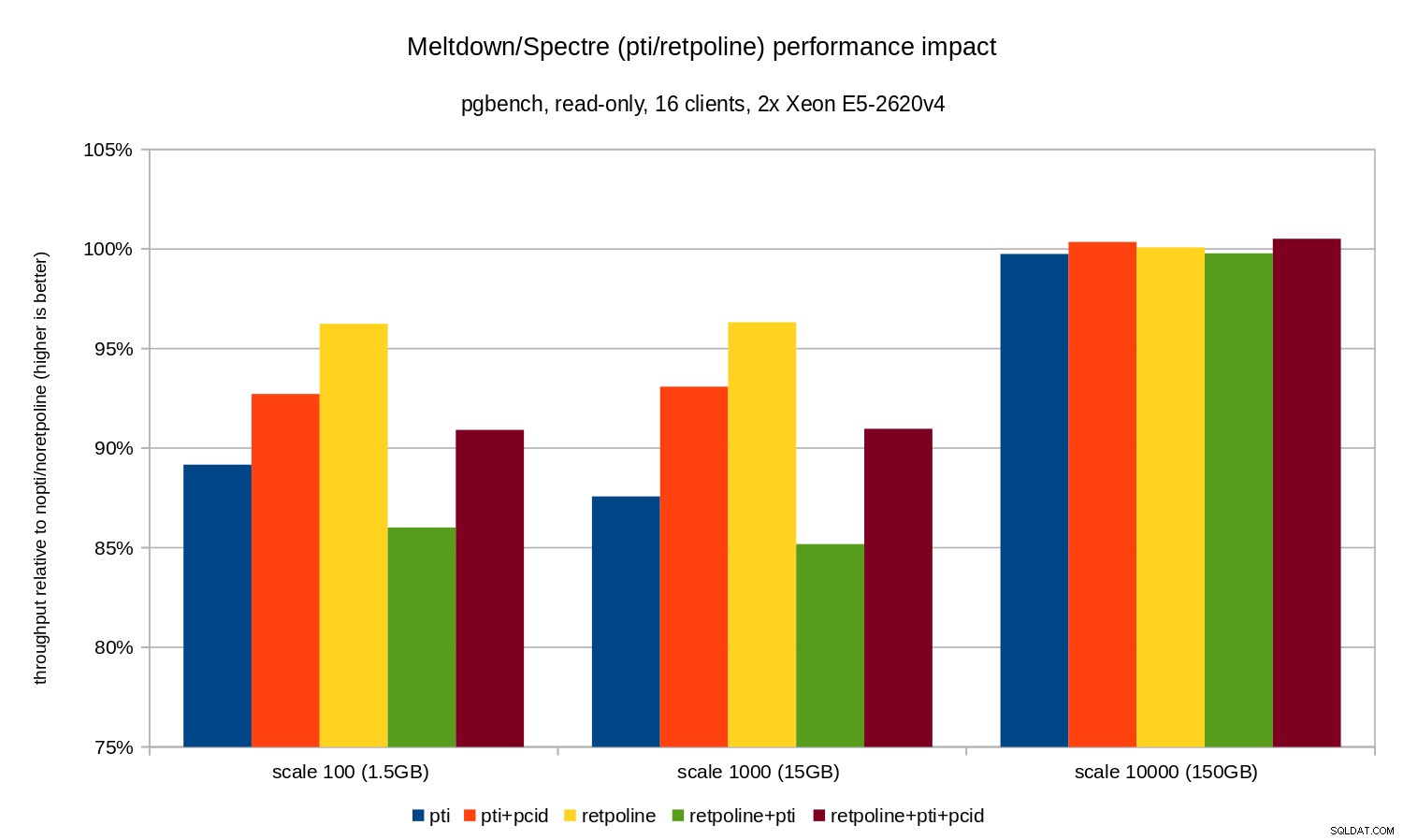
Como você pode ver, o impacto no desempenho de
pti para escalas que cabem na memória é de aproximadamente 10 a 12% e quase não mensurável quando a carga de trabalho se torna limitada por E/S. Além disso, a regressão é significativamente reduzida (ou desaparece completamente) quando pcid está ativado. Isso é consistente com a afirmação de que o PCID agora é um recurso crítico de desempenho/segurança no x86. O impacto de retpoline é muito menor – menos de 4% no pior caso, o que pode facilmente ser devido ao ruído. OLTP/leitura-escrita
Os testes de leitura e escrita foram realizados por um
pgbench comando semelhante a este:pgbench -n -c 16 -j 16 -N -T 3600 test
A duração foi longa o suficiente para cobrir vários pontos de verificação e
-N foi usado para eliminar a contenção de bloqueio em linhas na tabela de ramificações (minúsculas). O desempenho relativo é ilustrado por este gráfico: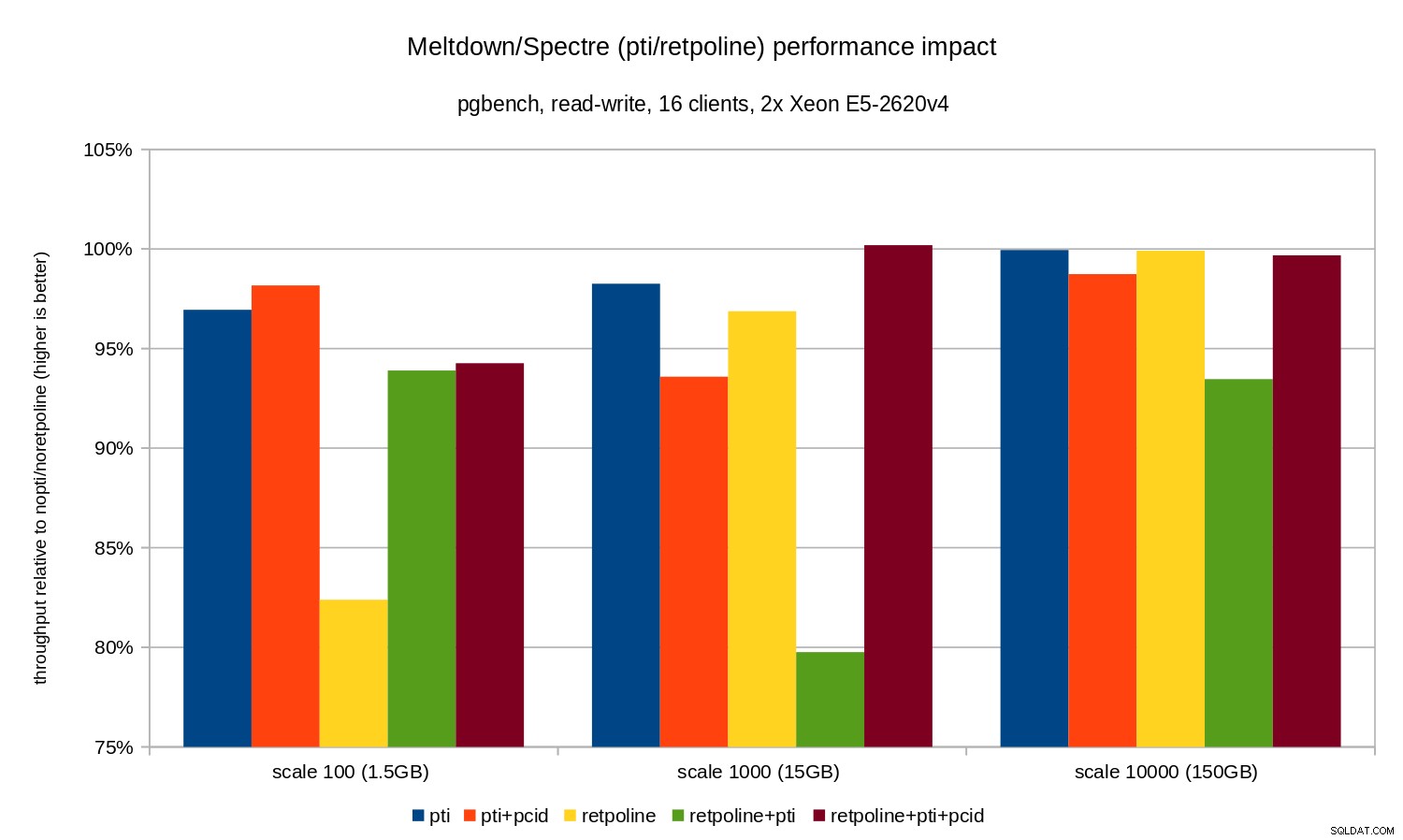
As regressões são um pouco menores do que no caso somente leitura – menos de 8% sem
pcid e menos de 3% com pcid ativado. Esta é uma consequência natural de gastar mais tempo executando E/S enquanto grava dados no WAL, liberando buffers modificados durante o ponto de verificação, etc. Existem dois bits estranhos, no entanto. Em primeiro lugar, o impacto de
retpoline é inesperadamente grande (perto de 20%) para escala 100, e o mesmo aconteceu para retpoline+pti na escala 1000. As razões não são muito claras e exigirão investigação adicional. OLAP
A carga de trabalho de análise foi modelada pelo benchmark dbt-3. Primeiro, vamos ver os resultados de escala de 10 GB, que se encaixam inteiramente na RAM (incluindo todos os índices etc.). Da mesma forma que o OLTP, não estamos realmente interessados em números absolutos, que neste caso seriam a duração de consultas individuais. Em vez disso, veremos a lentidão em comparação com o
nopti/noretpoline , isso é:(duration without patches) / (duration with patches)
Supondo que as mitigações resultem em desaceleração, obteremos valores entre 0% e 100%, onde 100% significa “sem impacto”. Os resultados ficam assim:
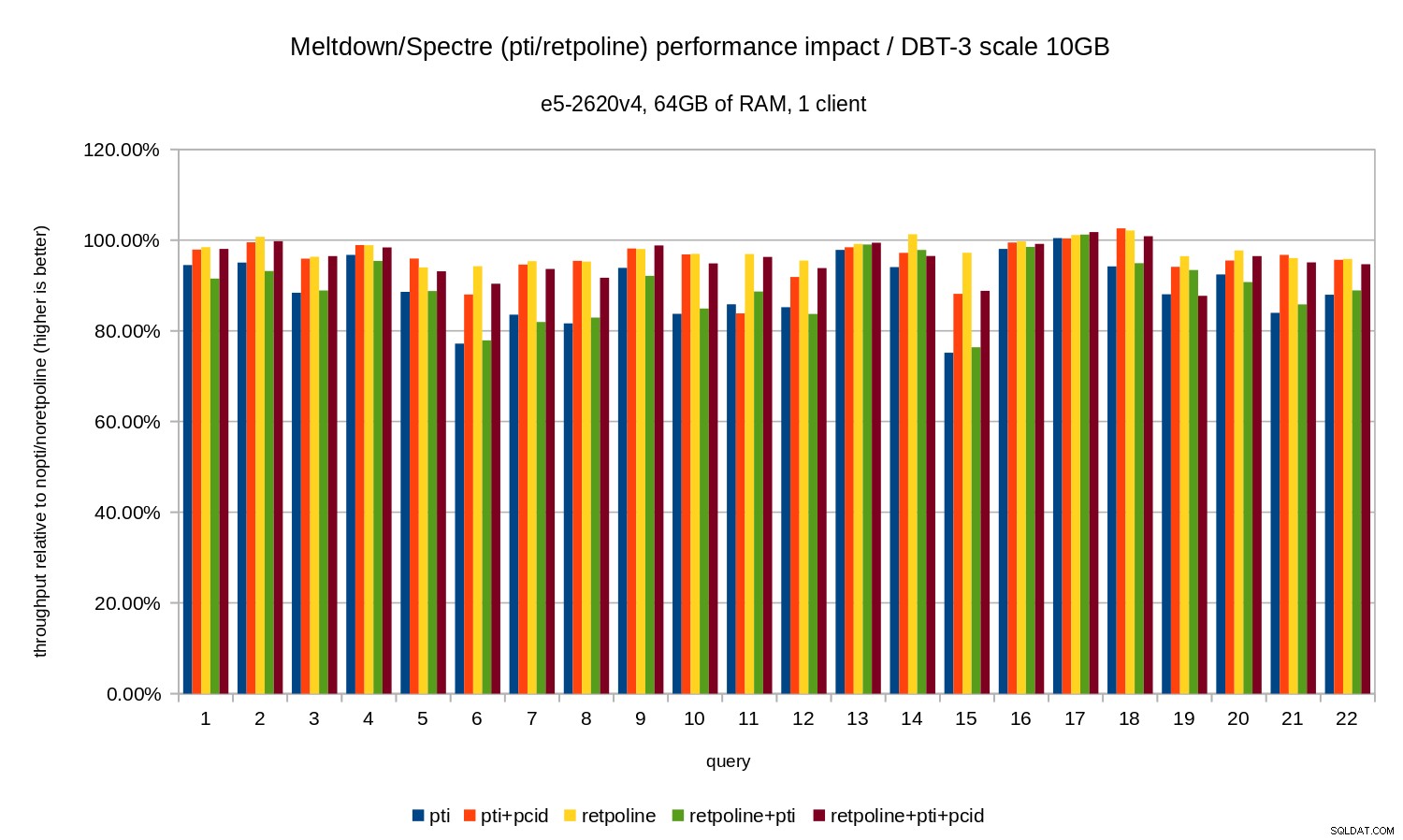
Ou seja, sem o
pcid a regressão geralmente está na faixa de 10 a 20%, dependendo da consulta. E com pcid a regressão cai para menos de 5% (e geralmente perto de 0%). Mais uma vez, isso confirma a importância do pcid característica. Para o conjunto de dados de 50 GB (que é cerca de 120 GB com todos os índices etc.), o impacto é assim:
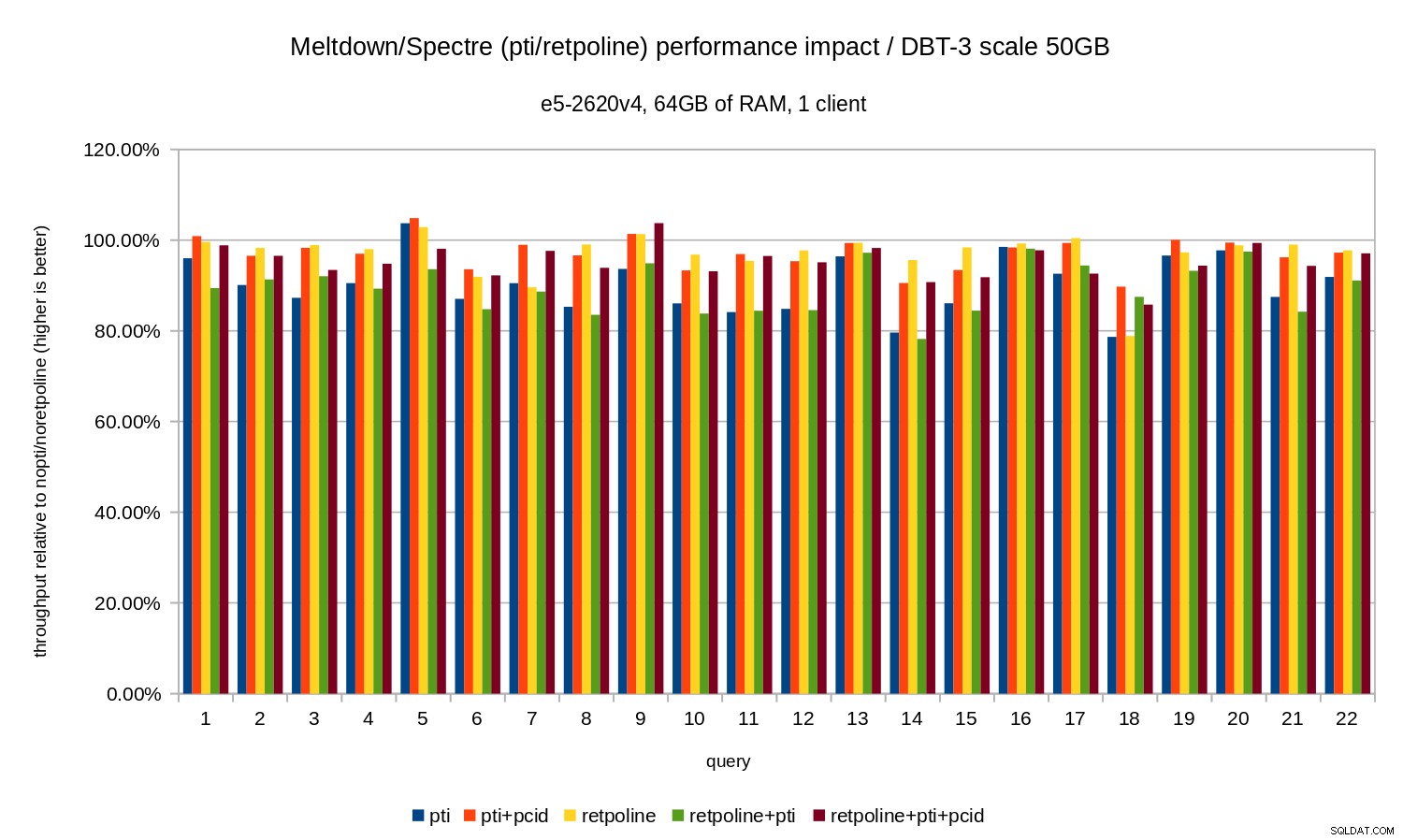
Assim como no caso de 10 GB, as regressões estão abaixo de 20% e
pcid reduz significativamente - perto de 0% na maioria dos casos. Os gráficos anteriores são um pouco confusos – existem 22 consultas e 5 séries de dados, o que é um pouco demais para um único gráfico. Então aqui está um gráfico mostrando o impacto apenas para todos os três recursos (
pti , pcid e retpoline ), para ambos os tamanhos de conjuntos de dados. 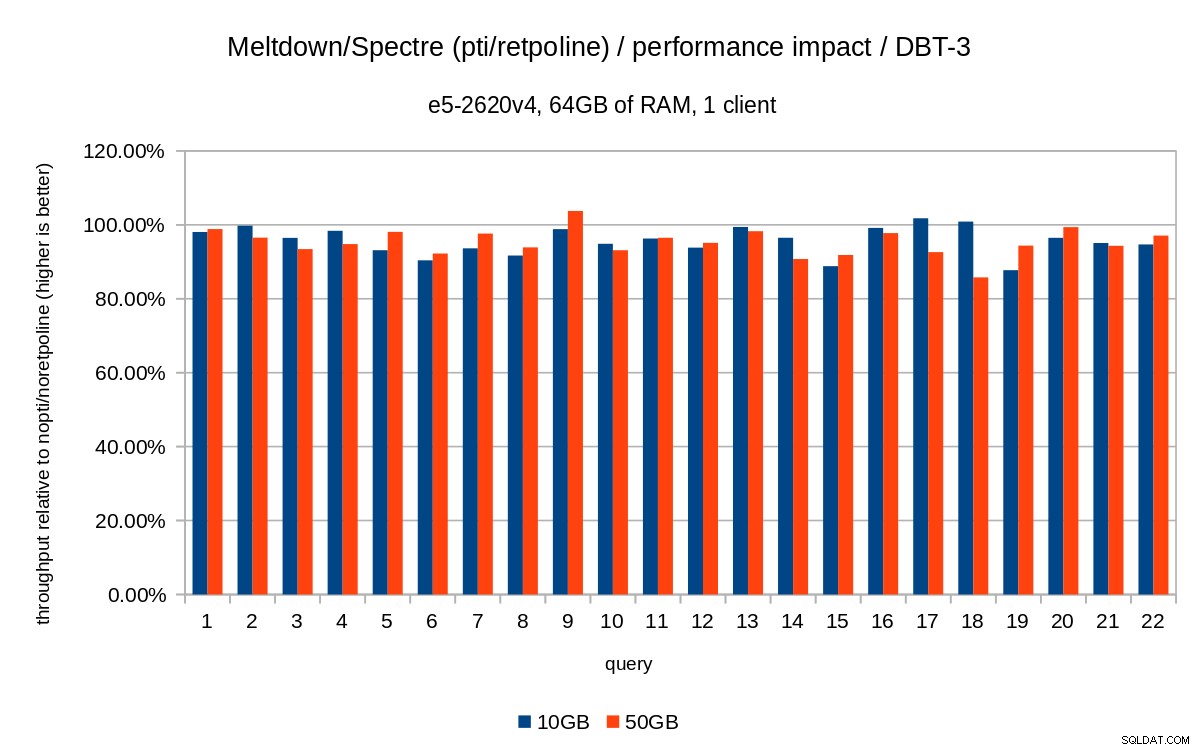
Conclusão
Para resumir brevemente os resultados:
retpolinetem muito pouco impacto no desempenho- OLTP – a regressão é de aproximadamente 10-15% sem o
pcid, e cerca de 1-5% compcid. - OLAP – a regressão é de até 20% sem o
pcid, e cerca de 1-5% compcid. - Para cargas de trabalho vinculadas a E/S (por exemplo, OLTP com o maior conjunto de dados), o Meltdown tem um impacto insignificante.
O impacto parece ser muito menor do que as estimativas iniciais sugeridas (30%), pelo menos para as cargas de trabalho testadas. Muitos sistemas estão operando com 70-80% da CPU nos períodos de pico, e os 30% saturariam totalmente a capacidade da CPU. Mas na prática o impacto parece estar abaixo de 5%, pelo menos quando o
pcid opção é usada. Não me entenda mal, uma queda de 5% ainda é uma regressão séria. Certamente é algo com o qual nos importaríamos durante o desenvolvimento do PostgreSQL, por exemplo. ao avaliar o impacto dos patches propostos. Mas é algo que os sistemas existentes devem lidar muito bem - se um aumento de 5% na utilização da CPU deixar seu sistema acima do limite, você terá problemas mesmo sem o Meltdown/Spectre.
Claramente, este não é o fim das correções do Meltdown/Spectre. Os desenvolvedores do kernel ainda estão trabalhando para melhorar as proteções e adicionar novas, e a Intel e outros fabricantes de CPU estão trabalhando em atualizações de microcódigo. E não sabemos sobre todas as variantes possíveis das vulnerabilidades, pois os pesquisadores conseguiram encontrar novas variantes dos ataques.
Portanto, há mais por vir e será interessante ver qual será o impacto no desempenho.