Comecei a escrever sobre a ferramenta (pglupgrade) que desenvolvi para realizar atualizações automatizadas de tempo de inatividade quase zero de clusters PostgreSQL. Neste post, falarei sobre a ferramenta e discutirei seus detalhes de design.
Você pode conferir a primeira parte da série aqui: Atualizações automatizadas de tempo de inatividade quase zero de clusters PostgreSQL na nuvem (Parte I).

A ferramenta é escrita em Ansible. Tenho experiência anterior em trabalhar com o Ansible e atualmente também trabalho com ele no 2ndQuadrant , e é por isso que foi uma opção confortável para mim. Dito isto, você pode implementar a lógica de atualização de tempo de inatividade mínimo, que será explicada mais adiante neste post, com sua ferramenta de automação favorita.
Leitura adicional:postagens do blog Ansible Loves PostgreSQL , PostgreSQL Planet in Ansible Galaxy e apresentação Gerenciando PostgreSQL com Ansible.
Manual do Pglupgrade
No Ansible, manuais são os principais scripts desenvolvidos para automatizar os processos, como provisionar instâncias de nuvem e atualizar clusters de banco de dados. Os manuais podem conter uma ou mais reproduções . Os manuais também podem conter variáveis , funções , e manipuladores se definido.
A ferramenta consiste em dois manuais principais. O primeiro manual é
provision.yml que automatiza o processo de criação de máquinas Linux em nuvem, de acordo com as especificações (Este é um playbook opcional escrito apenas para provisionar instâncias de nuvem e não diretamente relacionado com a atualização ). O segundo (e principal) manual é o pglupgrade.yml que automatiza o processo de atualização de clusters de banco de dados. O playbook Pglupgrade tem oito execuções para orquestrar a atualização. Cada uma das jogadas, use um arquivo de configuração (
config.yml ), execute algumas tarefas nos hosts ou grupos de hosts definidos no host arquivo de inventário (host.ini ). Arquivo de Inventário
Um arquivo de inventário permite que o Ansible saiba quais servidores ele precisa se conectar usando SSH, quais informações de conexão ele requer e, opcionalmente, quais variáveis estão associadas a esses servidores. Abaixo, você pode ver um arquivo de inventário de amostra, que foi usado para executar atualizações automatizadas de cluster para um dos estudos de caso projetados para a ferramenta. Discutiremos esses estudos de caso nos próximos posts desta série.
[old-primary] 54.171.211.188 [new-primary] 54.246.183.100 [old-standbys] 54.77.249.81 54.154.49.180 [new-standbys:children] old-standbys [pgbouncer] 54.154.49.180
Arquivo de inventário (host.ini )
O arquivo de inventário de amostra contém cinco hosts menos de cinco grupos de anfitriões que incluem old-primary , new-primary , old-standbys , new-standbys e pgbouncer . Um servidor pode pertencer a mais de um grupo. Por exemplo, os old-standbys é um grupo que contém os new-standbys group, o que significa os hosts que são definidos em old-standbys O grupo (54.77.249.81 e 54.154.49.180) também pertence ao grupo new-standbys grupo. Em outras palavras, os new-standbys grupo é herdado de (filhos de) old-standbys grupo. Isso é feito usando o :children especial sufixo.
Quando o arquivo de inventário estiver pronto, o playbook do Ansible poderá ser executado por meio do ansible-playbook comando apontando para o arquivo de inventário (se o arquivo de inventário não estiver localizado no local padrão, caso contrário, ele usará o arquivo de inventário padrão) conforme mostrado abaixo:
$ ansible-playbook -i hosts.ini pglupgrade.yml
Executando um manual do Ansible
Arquivo de configuração
O playbook do Pglupgrade usa um arquivo de configuração (
config.yml ) que permite que os usuários especifiquem valores para as variáveis de atualização lógicas. Conforme mostrado abaixo, o
config.yml armazena principalmente variáveis específicas do PostgreSQL que são necessárias para configurar um cluster do PostgreSQL, como postgres_old_datadir e postgres_new_datadir para armazenar o caminho do diretório de dados do PostgreSQL para as versões antigas e novas do PostgreSQL; postgres_new_confdir para armazenar o caminho do diretório de configuração do PostgreSQL para a nova versão do PostgreSQL; postgres_old_dsn e postgres_new_dsn para armazenar a string de conexão para o pglupgrade_user para poder se conectar ao pglupgrade_database dos servidores primários novos e antigos. A própria string de conexão é composta pelas variáveis configuráveis para que o usuário (pglupgrade_user ) e o banco de dados (pglupgrade_database ) podem ser alteradas para os diferentes casos de uso. ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user {{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main" Arquivo de configuração (config.yml )
Como uma etapa chave para qualquer atualização, as informações de versão do PostgreSQL podem ser especificadas para a versão atual (postgres_old_version ) e a versão que será atualizada para (postgres_new_version ). Ao contrário da replicação física, onde a replicação é uma cópia do sistema no nível de byte/bloco, a replicação lógica permite a replicação seletiva onde a replicação pode copiar os dados lógicos incluem bancos de dados especificados e as tabelas nesses bancos de dados. Por esse motivo, config.yml permite configurar qual banco de dados replicar via pglupgrade_database variável. Além disso, o usuário de replicação lógica precisa ter privilégios de replicação, e é por isso que pglupgrade_user variável deve ser especificada no arquivo de configuração. Existem outras variáveis relacionadas ao funcionamento interno do pglogical, como subscription_name e replication_set que são usados na função pglogical.
Design de alta disponibilidade da ferramenta Pglupgrade
A ferramenta Pglupgrade foi projetada para dar flexibilidade em termos de propriedades de Alta Disponibilidade (HA) ao usuário para os diferentes requisitos do sistema. Os
initial_standbys variável (consulte config.yml ) é a chave para designar as propriedades de HA do cluster enquanto a operação de atualização está ocorrendo. Por exemplo, se
initial_standbys é definido como 1 (pode ser definido como qualquer número permitido pela capacidade do cluster), o que significa que haverá 1 espera criada no cluster atualizado junto com o mestre antes do início da replicação. Em outras palavras, se você tiver 4 servidores e definir initial_standbys como 1, terá 1 servidor primário e 1 em espera na nova versão atualizada, bem como 1 servidor primário e 1 em espera na versão antiga. Esta opção permite reutilizar os servidores existentes enquanto a atualização ainda está acontecendo. No exemplo de 4 servidores, os antigos servidores primários e em espera podem ser reconstruídos como 2 novos servidores em espera após a conclusão da replicação.
Quando
initial_standbys estiver definida como 0, não haverá servidores em espera inicial criados no novo cluster antes do início da replicação. Se os initial_standbys configuração parece confusa, não se preocupe. Isso será explicado melhor na próxima postagem do blog, quando discutirmos dois estudos de caso diferentes.
Finalmente, o arquivo de configuração permite especificar grupos de servidores antigos e novos. Isso pode ser fornecido de duas maneiras. Primeiro, se houver um cluster existente, os endereços IP dos servidores (podem ser servidores bare-metal ou virtuais ) deve ser inserido em hosts.ini arquivo considerando as propriedades de HA desejadas durante a operação de upgrade.
A segunda maneira é executar provision.yml manual (foi como eu provisionei as instâncias de nuvem, mas você pode usar seus próprios scripts de provisionamento ou provisionar instâncias manualmente ) para provisionar servidores Linux vazios na nuvem (instâncias do AWS EC2) e obter os endereços IP dos servidores no hosts.ini Arquivo. De qualquer forma, config.yml obterá informações do host por meio de hosts.ini Arquivo.
Fluxo de trabalho do processo de atualização
Depois de explicar o arquivo de configuração (
config.yml ) que é usado pelo playbook pglupgrade, podemos explicar o fluxo de trabalho do processo de atualização. 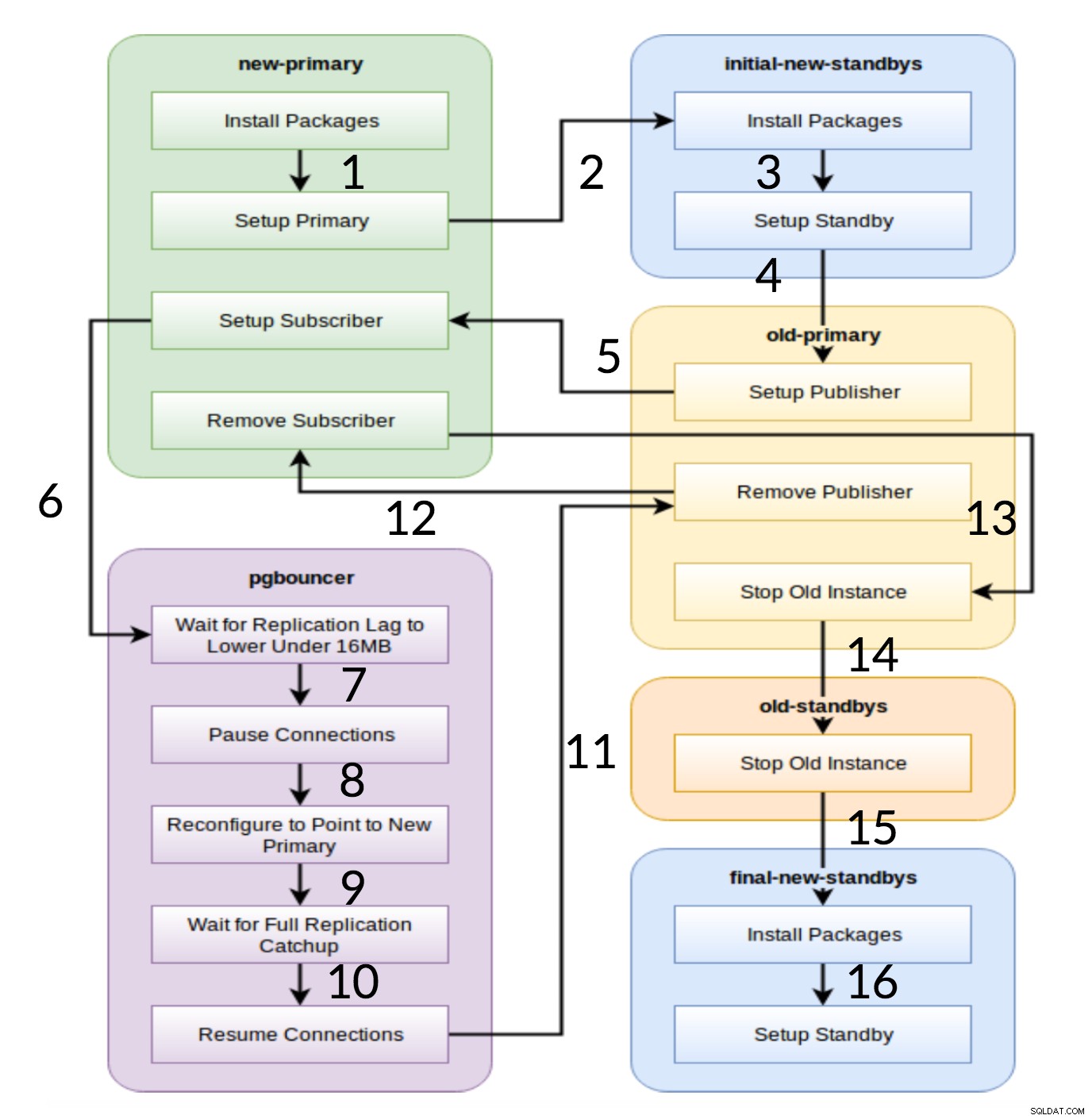
Pglupgrade Workflow
Como é visto no diagrama acima, existem seis grupos de servidores que são gerados no início com base na configuração (ambos hosts.ini e o config.yml ). O new-primary e old-primary os grupos sempre terão um servidor, pgbouncer grupo pode ter um ou mais servidores e todos os grupos de espera podem ter zero ou mais servidores neles. Em termos de implementação, todo o processo é dividido em oito etapas. Cada etapa corresponde a uma jogada no playbook pglupgrade, que executa as tarefas necessárias nos grupos de hosts atribuídos. O processo de atualização é explicado através das seguintes jogadas:
- Crie hosts com base na configuração: Jogo de preparação que constrói grupos internos de servidores com base na configuração. O resultado desta jogada (em combinação com o
hosts.iniconteúdos) são os seis grupos de servidores (ilustrados com cores diferentes no diagrama de fluxo de trabalho) que serão usados pelas sete peças a seguir. - Configurar novo cluster com espera(s) inicial(is): Configura um cluster PostgreSQL vazio com os novos standbys primários e iniciais (se houver algum definido). Ele garante que não haja restos das instalações do PostgreSQL do uso anterior.
- Modifique o primário antigo para oferecer suporte à replicação lógica: Instala a extensão pglogical. Em seguida, defina o editor adicionando todas as tabelas e sequências à replicação.
- Replicar para o novo primário: Configura o assinante no novo mestre que atua como um gatilho para iniciar a replicação lógica. Esta reprodução termina de replicar os dados existentes e começa a recuperar o que mudou desde que iniciou a replicação.
- Mude o pgbouncer (e aplicativos) para o novo primário: Quando o atraso de replicação converge para zero, pausa o pgbouncer para alternar o aplicativo gradualmente. Em seguida, ele aponta a configuração do pgbouncer para o novo primário e aguarda até que a diferença de replicação chegue a zero. Finalmente, o pgbouncer é retomado e todas as transações em espera são propagadas para o novo primário e começam a ser processadas ali. As esperas iniciais já estão em uso e respondem a solicitações de leitura.
- Limpe a configuração de replicação entre o primário antigo e o novo primário: Encerra a conexão entre o antigo e o novo servidor primário. Como todos os aplicativos são movidos para o novo servidor primário e a atualização é feita, a replicação lógica não é mais necessária. A replicação entre os servidores primário e em espera continua com a replicação física.
- Parar o cluster antigo: O serviço Postgres é interrompido em hosts antigos para garantir que nenhum aplicativo possa se conectar a ele.
- Reconfigure o restante das esperas para o novo primário: Reconstrói outras esperas se houver outros hosts restantes além das esperas iniciais. No segundo estudo de caso, não há servidores em espera restantes para reconstruir. Esta etapa dá a chance de reconstruir o servidor primário antigo como um novo standby se apontado no grupo new-standbys em hosts.ini. A reutilização de servidores existentes (mesmo o primário antigo) é alcançada usando o design de configuração em espera de duas etapas da ferramenta pglupgrade. O usuário pode especificar quais servidores devem se tornar em espera do novo cluster antes da atualização e quais devem se tornar em espera após a atualização.
Conclusão
Neste post, discutimos os detalhes de implementação e o design de alta disponibilidade da ferramenta pglupgrade. Ao fazer isso, também mencionamos alguns conceitos-chave do desenvolvimento do Ansible (ou seja, playbook, inventário e arquivos de configuração) usando a ferramenta como exemplo. Ilustramos o fluxo de trabalho do processo de atualização e resumimos como cada etapa funciona com uma reprodução correspondente. Continuaremos a explicar o pglupgrade mostrando estudos de caso nas próximas postagens desta série.
Obrigado por ler!