A disponibilidade, acessibilidade e desempenho dos dados são vitais para o sucesso dos negócios. O ajuste de desempenho e a otimização de consultas SQL são práticas complicadas, mas necessárias para profissionais de banco de dados. Eles exigem a análise de várias coleções de dados usando eventos estendidos, perfmon, planos de execução, estatísticas e índices para citar alguns. Às vezes, os proprietários de aplicativos pedem para aumentar os recursos do sistema (CPU e memória) para melhorar o desempenho do sistema. No entanto, você pode não precisar desses recursos adicionais e eles podem ter um custo associado a eles. Às vezes, tudo o que é necessário é fazer pequenas melhorias para alterar o comportamento da consulta.
Neste artigo, discutiremos algumas práticas recomendadas de otimização de consulta SQL para aplicar ao escrever consultas SQL.
SELECT * vs SELECT lista de colunas
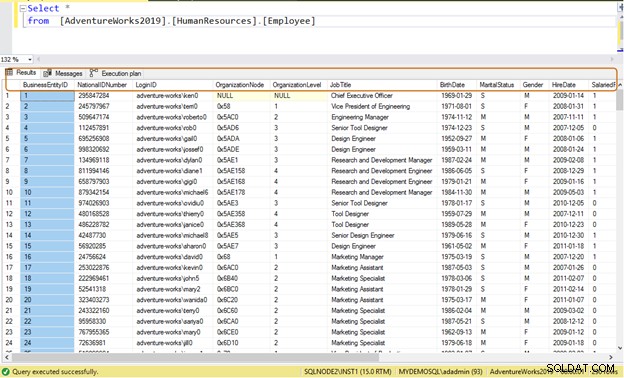
Normalmente, os desenvolvedores usam a instrução SELECT * para ler dados de uma tabela. Ele lê todos os dados disponíveis da coluna na tabela. Suponha que uma tabela [AdventureWorks2019].[HumanResources].[Employee] armazene dados de 290 funcionários e você precise recuperar as seguintes informações:
- Número de identificação nacional do funcionário
- DO
- Sexo
- Data da contratação
Consulta ineficiente: Se você usar a instrução SELECT *, ela retornará todos os dados da coluna para todos os 290 funcionários.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
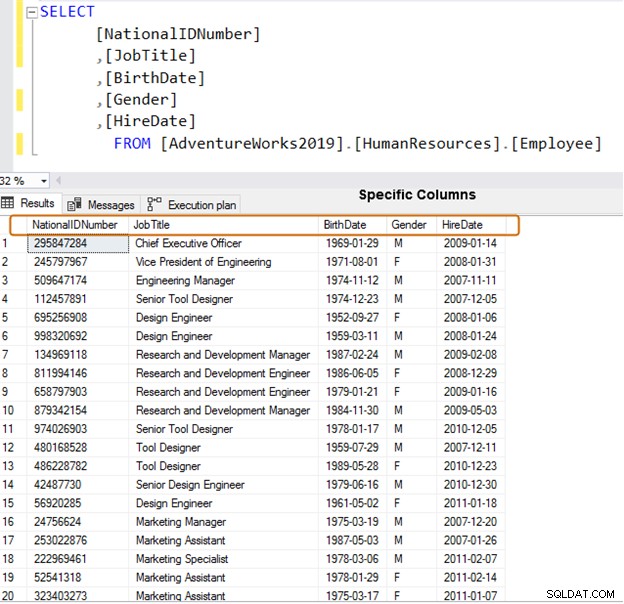
Em vez disso, use nomes de coluna específicos para recuperação de dados.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
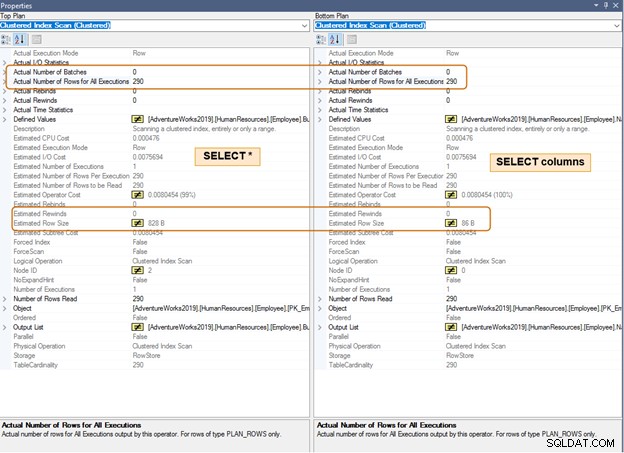
No plano de execução abaixo, observe a diferença no tamanho estimado da linha para o mesmo número de linhas. Você notará uma diferença na CPU e E/S para um grande número de linhas também.
Uso de COUNT() vs. EXISTS
Suponha que você queira verificar se existe um registro específico na tabela SQL. Normalmente, usamos COUNT (*) para verificar o registro e retorna o número de registros na saída.
No entanto, podemos usar a função IF EXISTS() para essa finalidade. Para a comparação, habilitei as estatísticas antes de executar as consultas.
A consulta para COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
A consulta para IF EXISTS()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
Usei o statisticsparser para analisar os resultados das estatísticas de ambas as consultas. Observe os resultados abaixo. A consulta com COUNT(*) possui 276 leituras lógicas enquanto a IF EXISTS() possui 83 leituras lógicas. Você pode até obter uma redução mais significativa nas leituras lógicas com o IF EXISTS(). Portanto, você deve usá-lo para otimizar as consultas SQL para um melhor desempenho.

Evite usar SQL DISTINCT
Sempre que queremos registros exclusivos da consulta, usamos habitualmente a cláusula SQL DISTINCT. Suponha que você tenha unido duas tabelas e, na saída, retorne as linhas duplicadas. Uma solução rápida é especificar o operador DISTINCT que suprime a linha duplicada.
Vamos examinar as instruções SELECT simples e comparar os planos de execução. A única diferença entre as duas consultas é um operador DISTINCT.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Com o operador DISTINCT, o custo da consulta é de 77%, enquanto a consulta anterior (sem DISTINCT) tem apenas 23% do custo do lote.
Você pode usar GROUP BY, CTE ou uma subconsulta para escrever código SQL eficiente em vez de usar DISTINCT para obter valores distintos do conjunto de resultados. Além disso, você pode recuperar colunas adicionais para um conjunto de resultados distinto.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Uso de curingas na consulta SQL
Suponha que você queira pesquisar os registros específicos que contêm nomes que começam com a string especificada. Os desenvolvedores usam um curinga para pesquisar os registros correspondentes.
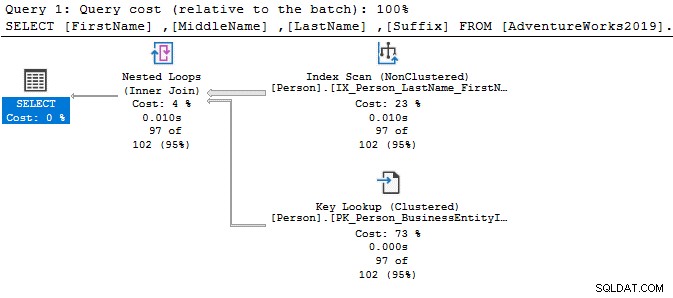
Na consulta abaixo, ele procura a string Ken na coluna do primeiro nome. Esta consulta recupera os resultados esperados de Ken dra e Ken net. Mas também fornece resultados inesperados, por exemplo, Macken zie e Nken ge.
No plano de execução, você vê a verificação de índice e a pesquisa de chave para a consulta acima.
Você pode evitar o resultado inesperado usando o caractere curinga no final da string.
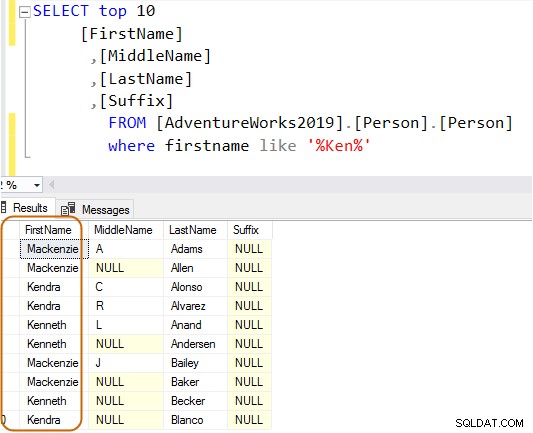
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Agora, você obtém o resultado filtrado com base em seus requisitos.
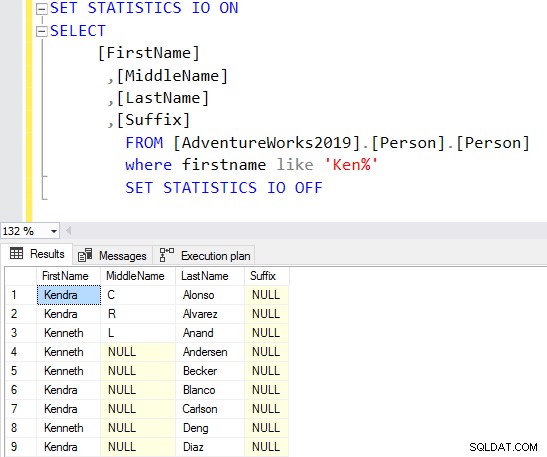
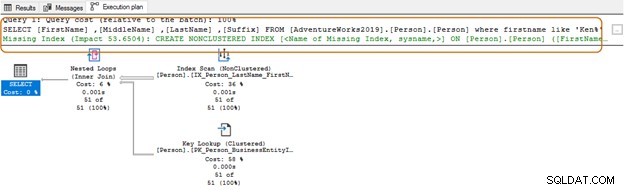
Ao usar o caractere curinga no início, o otimizador de consulta pode não conseguir usar o índice adequado. Conforme mostrado na captura de tela abaixo, com um caractere curinga à direita, o otimizador de consulta também sugere um índice ausente.
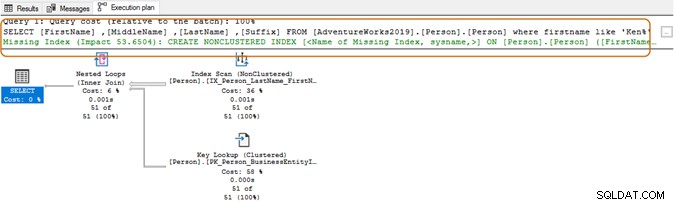
Aqui, você vai querer avaliar seus requisitos de aplicação. Você deve tentar evitar o uso de um caractere curinga nas strings de pesquisa, pois isso pode forçar o otimizador de consulta a usar uma verificação de tabela. Se a tabela for enorme, exigiria recursos de sistema mais altos para E/S, CPU e memória e pode causar problemas de desempenho para sua consulta SQL.
Uso das cláusulas WHERE e HAVING
As cláusulas WHERE e HAVING são usadas como filtros de linha de dados. A cláusula WHERE filtra os dados antes de aplicar a lógica de agrupamento, enquanto a cláusula HAVING filtra as linhas após os cálculos agregados.
Por exemplo, na consulta abaixo, usamos um filtro de dados na cláusula HAVING sem uma cláusula WHERE.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
A consulta a seguir filtra os dados primeiro na cláusula WHERE e, em seguida, usa a cláusula HAVING para o filtro de dados agregados.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Eu recomendo usar a cláusula WHERE para filtragem de dados e a cláusula HAVING para seu filtro de dados agregados como prática recomendada.
Uso das cláusulas IN e EXISTS
Você deve evitar usar a cláusula IN-operator para suas consultas SQL. Por exemplo, na consulta abaixo, primeiro encontramos o ID do produto na tabela [Production].[TransactionHistory]) e, em seguida, procuramos os registros correspondentes na tabela [Production].[Product].
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
Na consulta abaixo, substituímos a cláusula IN por uma cláusula EXISTS.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
Agora, vamos comparar as estatísticas depois de executar as duas consultas.
A cláusula IN usa 504 varreduras, enquanto a cláusula EXISTS usa 1 varredura para a tabela [Production].[TransactionHistory])].
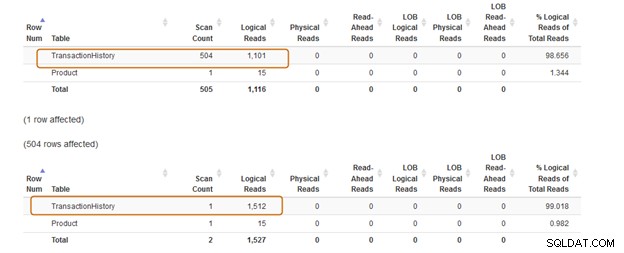
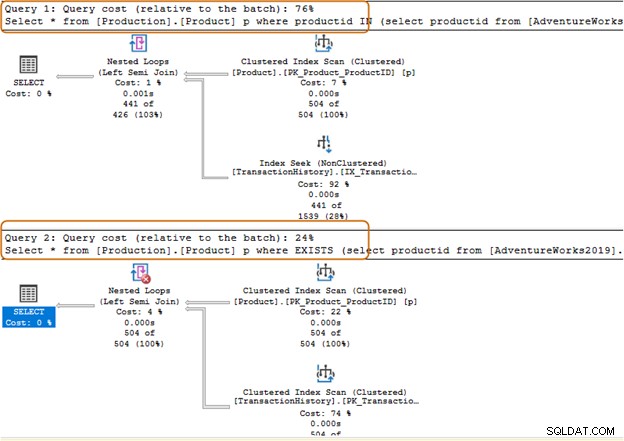
O lote de consulta da cláusula IN custa 74%, enquanto o custo da cláusula EXISTS é de 24%. Portanto, você deve evitar a cláusula IN, especialmente se a subconsulta retornar um grande conjunto de dados.
Índices ausentes
Às vezes, quando executamos uma consulta SQL e procuramos o plano de execução real no SSMS, você recebe uma sugestão sobre um índice que pode melhorar sua consulta SQL.
Como alternativa, você pode usar as exibições de gerenciamento dinâmico para verificar os detalhes dos índices ausentes em seu ambiente.
- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Normalmente, os DBAs seguem o conselho do SSMS e criam os índices. Pode melhorar o desempenho da consulta no momento. No entanto, você não deve criar o índice diretamente com base nessas recomendações. Isso pode afetar o desempenho de outras consultas e diminuir a velocidade de suas instruções INSERT e UPDATE.
- Primeiro, revise os índices existentes para sua tabela SQL.
- Observação, indexação excessiva e insuficiente são ruins para o desempenho da consulta.
- Aplique as recomendações de índice ausentes com o maior impacto após revisar seus índices existentes e implementá-las em seu ambiente inferior. Se sua carga de trabalho funcionar bem após a implementação do novo índice ausente, vale a pena adicioná-lot.
Sugiro que você consulte este artigo para obter as práticas recomendadas de indexação detalhadas:11 Práticas recomendadas do índice do SQL Server para ajuste de desempenho aprimorado.
Dicas de consulta
Os desenvolvedores especificam as dicas de consulta explicitamente em suas instruções t-SQL. Essas dicas de consulta substituem o comportamento do otimizador de consulta e o forçam a preparar um plano de execução com base na dica de consulta. As dicas de consulta usadas com frequência são NOLOCK, Optimize For e Recompile Merge/Hash/Loop. Eles são correções de curto prazo para suas consultas. No entanto, você deve trabalhar na análise de sua consulta, índices, estatísticas e plano de execução para uma solução permanente.
De acordo com as práticas recomendadas, você deve minimizar o uso de qualquer dica de consulta. Você deseja usar as dicas de consulta na consulta SQL depois de primeiro entender as implicações dela e não usá-las desnecessariamente.
Lembretes de otimização de consulta SQL
Conforme discutimos, a otimização de consultas SQL é um caminho sem fim. Você pode aplicar as práticas recomendadas e pequenas correções que podem melhorar muito o desempenho. Considere as seguintes dicas para um melhor desenvolvimento de consultas:
- Sempre observe as alocações de recursos do sistema (discos, CPU, memória)
- Revise seus sinalizadores de rastreamento de inicialização, índices e tarefas de manutenção de banco de dados
- Analise sua carga de trabalho usando eventos estendidos, criador de perfil ou ferramentas de monitoramento de banco de dados de terceiros
- Sempre implemente qualquer solução (mesmo que você esteja 100% confiante) primeiro no ambiente de teste e analise seu impacto; quando estiver satisfeito, planeje as implementações de produção