Na postagem anterior do blog, expliquei brevemente como obtivemos os números de desempenho publicados no anúncio do pglogical. Nesta postagem do blog, gostaria de discutir os limites de desempenho das soluções de replicação lógica em geral e também como eles se aplicam ao pglogical.
replicação física
Primeiramente, vamos ver como funciona a replicação física (embutida no PostgreSQL desde a versão 9.0). Uma figura um tanto simplificada do com dois apenas dois nós se parece com isso:
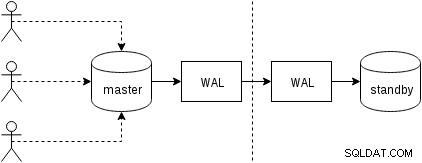
Os clientes executam consultas no nó mestre, as alterações são gravadas em um log de transações (WAL) e copiadas pela rede para WAL no nó de espera. A recuperação no processo de espera no modo de espera lê as alterações do WAL e as aplica aos arquivos de dados exatamente como durante a recuperação. Se o modo de espera estiver no modo “hot_standby”, os clientes poderão emitir consultas somente leitura no nó enquanto isso estiver acontecendo.
Isso é muito eficiente porque há muito pouco processamento adicional – as alterações são transferidas e gravadas no modo de espera como um blob binário opaco. Claro, a recuperação não é gratuita (tanto em termos de CPU quanto de E/S), mas é difícil ficar mais eficiente do que isso.
Os gargalos em potencial óbvios com a replicação física são a largura de banda da rede (transferindo o WAL do mestre para o standby) e também a E/S no standby, que pode ser saturada pelo processo de recuperação que geralmente emite muitas solicitações aleatórias de E/S ( em alguns casos mais do que o mestre, mas não vamos entrar nisso).
replicação lógica
A replicação lógica é um pouco mais complicada, pois não lida com fluxo WAL binário opaco, mas com um fluxo de alterações “lógicas” (imagine instruções INSERT, UPDATE ou DELETE, embora isso não seja perfeitamente correto, pois estamos lidando com representação estruturada de os dados). Ter as mudanças lógicas permite fazer coisas interessantes como resolução de conflitos, replicar apenas tabelas selecionadas, para um esquema diferente ou entre diferentes versões (ou até bancos de dados diferentes).
Existem diferentes maneiras de obter as alterações – a abordagem tradicional é usar gatilhos que gravam as alterações em uma tabela e permitir que um processo personalizado leia continuamente essas alterações e as aplique no modo de espera executando consultas SQL. E tudo isso é conduzido por um processo de daemon externo (ou possivelmente vários processos, rodando em ambos os nós), conforme ilustrado na próxima figura

Isso é o que slony ou londiste fazem e, embora tenha funcionado muito bem, significa muita sobrecarga - por exemplo, requer capturar as alterações de dados e gravar os dados várias vezes (na tabela original e em uma tabela de "log" e também para WAL para ambas as tabelas). Discutiremos outras fontes de sobrecarga mais tarde. Embora o pglogical precise atingir os mesmos objetivos, ele os atinge de maneira diferente, graças a vários recursos adicionados às versões recentes do PostgreSQL (portanto, não disponíveis quando as outras ferramentas foram implementadas):

Ou seja, em vez de manter um log de alterações separado, o pglogical conta com o WAL – isso é possível graças a uma decodificação lógica disponível no PostgreSQL 9.4, que permite extrair alterações lógicas do log do WAL. Graças a isso, o pglogical não precisa de gatilhos caros e geralmente pode evitar gravar os dados duas vezes no mestre (exceto para grandes transações que podem vazar para o disco).
Após decodificar cada transação, ela é transferida para o standby e o processo de aplicação aplica suas alterações ao banco de dados standby. O pglogical não aplica as alterações executando consultas SQL regulares, mas em um nível inferior, ignorando a sobrecarga associada à análise e planejamento de consultas SQL. Isso dá ao pglogical uma vantagem significativa sobre as soluções existentes que passam pela camada SQL (compensando assim a análise e o planejamento).
potenciais gargalos
Claramente, a replicação lógica é suscetível aos mesmos gargalos da replicação física, ou seja, é possível saturar a rede ao transferir as alterações e I/O no modo de espera ao aplicá-las no modo de espera. Há também uma quantidade razoável de sobrecarga devido a etapas adicionais não presentes em uma replicação física.
Precisamos de alguma forma coletar as mudanças lógicas, enquanto a replicação física simplesmente encaminha o WAL como fluxo de bytes. Como já mencionado, as soluções existentes geralmente contam com gatilhos que gravam as alterações em uma tabela de “log”. O pglogical, em vez disso, depende do log de gravação antecipada (WAL) e da decodificação lógica para obter a mesma coisa, o que é mais barato que os gatilhos e também não precisa gravar os dados duas vezes na maioria dos casos (com o bônus adicional de aplicarmos automaticamente as alterações na ordem de confirmação).
Isso não quer dizer que não haja oportunidades para melhorias adicionais – por exemplo, a decodificação atualmente só acontece quando a transação é confirmada, portanto, com grandes transações, isso pode aumentar o atraso da replicação. A replicação física simplesmente transmite as alterações do WAL para o outro nó e, portanto, não tem essa limitação. Grandes transações também podem se espalhar para o disco, causando gravações duplicadas, porque o upstream precisa armazená-las até que sejam confirmadas e possam ser enviadas para o downstream.
O trabalho futuro está planejado para permitir que o pglogical comece a transmitir grandes transações enquanto elas ainda estão em andamento no upstream, reduzindo a latência entre o commit upstream e o downstream e reduzindo a amplificação de gravação upstream.
Depois que as alterações são transferidas para o modo de espera, o processo de aplicação precisa realmente aplicá-las de alguma forma. Conforme mencionado na seção anterior, as soluções existentes faziam isso construindo e executando comandos SQL, enquanto o pglogical ignora inteiramente a camada SQL e a sobrecarga associada.
Ainda assim, isso não torna a aplicação totalmente gratuita, pois ainda precisa executar pesquisas de chave primária, atualizar índices, executar gatilhos e realizar várias outras verificações. Mas é significativamente mais barato do que a abordagem baseada em SQL. De certa forma, funciona muito como COPY e é especialmente rápido em tabelas simples sem gatilhos, chaves estrangeiras etc.
Em todas as soluções de replicação lógica, cada uma dessas etapas (decodificação e aplicação) acontece em um único processo, portanto, há uma quantidade bastante limitada de tempo de CPU. Este é provavelmente o gargalo mais premente em todas as soluções existentes, porque você pode ter uma máquina bastante robusta com dezenas ou até centenas de clientes executando consultas em paralelo, mas tudo isso precisa passar por um único processo de decodificação dessas alterações (no master) e um processo aplicando essas mudanças (no modo de espera).
A limitação de "processo único" pode ser um pouco relaxada usando bancos de dados separados, pois cada banco de dados é tratado por um processo separado. Quando se trata de um único banco de dados, o trabalho futuro está planejado para paralelizar a aplicação por meio de um pool de trabalhadores em segundo plano para aliviar esse gargalo.