Embora no futuro a maioria dos servidores de banco de dados (particularmente aqueles que lidam com cargas de trabalho do tipo OLTP) usarão um armazenamento baseado em flash, ainda não chegamos lá - o armazenamento em flash ainda é consideravelmente mais caro do que os discos rígidos tradicionais, e muitos sistemas usam uma mistura de unidades SSD e HDD. No entanto, isso significa que precisamos decidir como dividir o banco de dados – o que deve ir para a ferrugem giratória (HDD) e qual é um bom candidato para o armazenamento flash que é mais caro, mas muito melhor para lidar com E/S aleatória.
Existem soluções que tentam lidar com isso automaticamente no nível de armazenamento usando SSDs automaticamente como cache, mantendo automaticamente a parte ativa dos dados no SSD. Dispositivos de armazenamento / SANs geralmente fazem isso internamente, existem unidades SATA/SAS híbridas com HDD grande e SSD pequeno em um único pacote e, claro, soluções para fazer isso diretamente no host - por exemplo, há dm-cache no Linux, LVM também obteve essa capacidade (construída em cima do dm-cache) em 2014 e, claro, o ZFS possui L2ARC.
Mas vamos ignorar todas essas opções automáticas e digamos que temos dois dispositivos conectados diretamente ao sistema – um baseado em HDDs, o outro baseado em flash. Como você deve dividir o banco de dados para obter o máximo benefício do flash caro? Um padrão comumente usado é fazer isso por tipo de objeto, particularmente tabelas versus índices. O que faz sentido em geral, mas geralmente vemos pessoas colocando índices no armazenamento SSD, pois os índices estão associados a E/S aleatória. Embora isso possa parecer razoável, acontece que é exatamente o oposto do que você deveria estar fazendo.
Deixe-me mostrar uma referência…
Deixe-me demonstrar isso em um sistema com armazenamento HDD (RAID10 construído a partir de 4 unidades SAS de 10k) e um único dispositivo SSD (Intel S3700). O sistema tem 16GB de RAM, então vamos usar o pgbench com escalas 300 (=4,5GB) e 3000 (=45GB), ou seja, um que cabe facilmente na RAM e um múltiplo de RAM. Em seguida, vamos colocar tabelas e índices em diferentes sistemas de armazenamento (usando tablespaces) e medir o desempenho. O cluster de banco de dados foi razoavelmente configurado (buffers compartilhados, limites WAL etc.) com relação aos recursos de hardware. O WAL foi colocado em um dispositivo SSD separado, conectado a um controlador RAID compartilhado com as unidades SAS.
No conjunto de dados pequeno (4,5 GB), os resultados são assim (observe que o eixo y começa em 3000 tps):
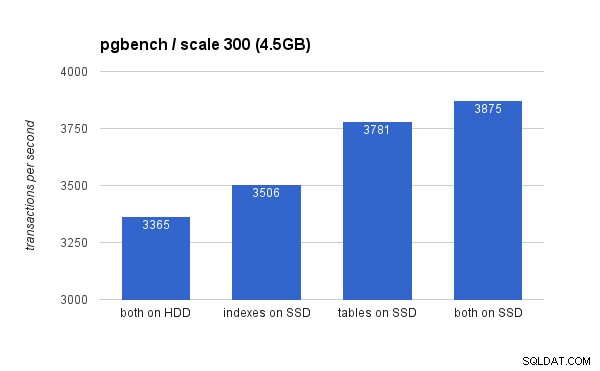
Claramente, colocar os índices no SSD oferece um benefício menor em comparação com o uso do SSD para tabelas. Embora o conjunto de dados se encaixe facilmente na RAM, as alterações precisam eventualmente ser gravadas no disco e, embora o controlador RAID tenha um cache de gravação, ele não pode competir com o armazenamento flash. Os novos controladores RAID provavelmente teriam um desempenho um pouco melhor, mas também as novas unidades SSD.
No grande conjunto de dados, as diferenças são muito mais significativas (desta vez, o eixo y começa em 0):
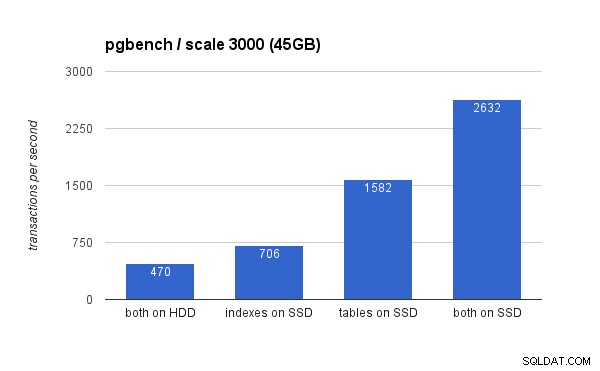
Colocar os índices no SSD resulta em ganho de desempenho significativo (quase 50%, tomando o armazenamento HDD como linha de base), mas mover as tabelas para o SSD superou isso facilmente, ganhando mais de 200%. É claro que, se você colocar tabelas e índices em SSDs, melhorará ainda mais o desempenho - mas se puder fazer isso, não precisará se preocupar com os outros casos.
Mas por quê?
Obter um melhor desempenho ao colocar tabelas em SSDs pode parecer um pouco contra-intuitivo, então por que se comporta assim? Bem, provavelmente é uma combinação de vários fatores:
- os índices geralmente são muito menores que as tabelas e, portanto, cabem na memória com mais facilidade
- as páginas em níveis de índices (na árvore) geralmente são bastante quentes e, portanto, permanecem na memória
- ao digitalizar e indexar, grande parte da E/S real é sequencial por natureza (especialmente para páginas de folha)
A consequência disso é que uma quantidade surpreendente de E/S contra índices não acontece (graças ao cache) ou é sequencial. Por outro lado, os índices são uma ótima fonte de E/S aleatória nas tabelas.
Mas é mais complicado…
Claro, este foi apenas um exemplo simples, e as conclusões podem ser diferentes para cargas de trabalho substancialmente diferentes, por exemplo. Da mesma forma, como os SSDs são mais caros, os sistemas tendem a ter mais espaço em disco nas unidades HDD do que nas unidades SSD, portanto, as tabelas podem não caber no SSD enquanto os índices caberiam. Nesses casos, é necessário um posicionamento mais elaborado - por exemplo, considerando não apenas o tipo do objeto, mas também a frequência com que ele é usado (e apenas movendo as tabelas muito usadas para SSDs), ou mesmo subconjuntos de tabelas (por exemplo, movendo gradualmente dados de SSD para HDD).