Um dos principais aspectos da alta disponibilidade é a capacidade de reagir rapidamente a falhas. Não é incomum gerenciar bancos de dados manualmente e fazer com que o software de monitoramento fique de olho na integridade do banco de dados. Em caso de falha, o software de monitoramento envia um alerta para a equipe de plantão. Isso significa que alguém pode precisar acordar, acessar um computador e fazer login nos sistemas e examinar os logs - ou seja, há algum tempo de espera antes que a correção possa começar. Idealmente, todo o processo deve ser automatizado.
Neste blog, veremos como implantar um sistema totalmente automatizado que detecta quando o banco de dados primário falha e inicia procedimentos de failover promovendo um banco de dados secundário. Usaremos o ClusterControl para realizar o failover automático do banco de dados Moodle PostgreSQL.
Vantagem do failover automático
- Menos tempo para recuperar o serviço de banco de dados
- Maior tempo de atividade do sistema
- Menos dependência do DBA ou do administrador que configurou a alta disponibilidade para o banco de dados
Arquitetura
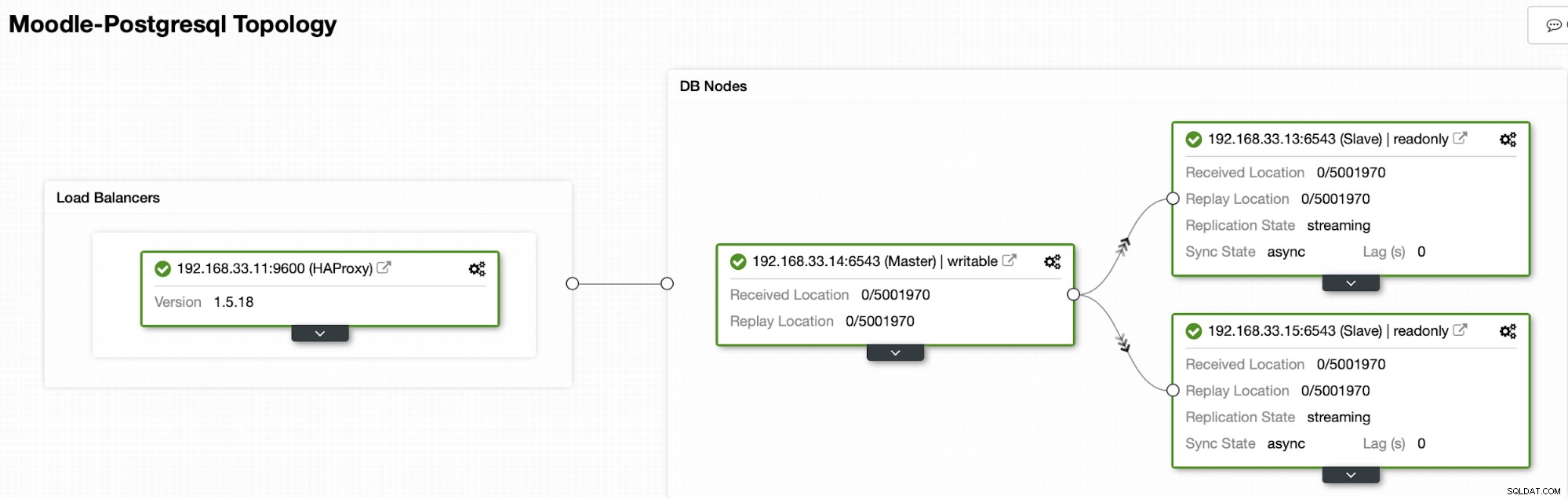
Atualmente temos um servidor principal Postgres e dois servidores secundários no balanceador de carga HAProxy que envia o tráfego do Moodle para o nó primário do PostgreSQL. A recuperação de cluster e a recuperação automática de nó no ClusterControl são as configurações importantes para executar o processo de failover automático.

Controlando para qual servidor fazer failover
O ClusterControl oferece whitelisting e blacklisting de um conjunto de servidores que você deseja que participem do failover ou excluam como candidato.
Existem duas variáveis que você pode definir na configuração do cmon,
- replication_failover_whitelist :contém uma lista de IPs ou nomes de host de servidores secundários que devem ser usados como possíveis candidatos primários. Se esta variável for definida, apenas esses hosts serão considerados.
- replication_failover_blacklist :contém uma lista de hosts que nunca serão considerados como candidatos primários. Você pode usá-lo para listar os servidores secundários usados para backups ou consultas analíticas. Se o hardware variar entre os servidores secundários, você pode querer colocar aqui os servidores que usam hardware mais lento.
Processo de failover automático
Etapa 1
Iniciamos o carregamento de dados no servidor primário (192.168.33.14) usando a ferramenta sysbench.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Etapa 2
Vamos parar o servidor primário do Postgres (192.168.33.14). No ClusterControl, o parâmetro (enable_cluster_autorecovery) é habilitado para promover o próximo primário adequado.
# service postgresql-12 stopEtapa 3
O ClusterControl detecta falhas no primário e promove um secundário com os dados mais atuais como um novo primário. Ele também funciona no restante dos servidores secundários para que sejam replicados a partir do novo primário.

No nosso caso, o (192.168.33.13) é um novo servidor primário e os servidores secundários agora são replicados a partir desse novo servidor primário. Agora o HAProxy roteia o tráfego do banco de dados dos servidores Moodle para o servidor primário mais recente.
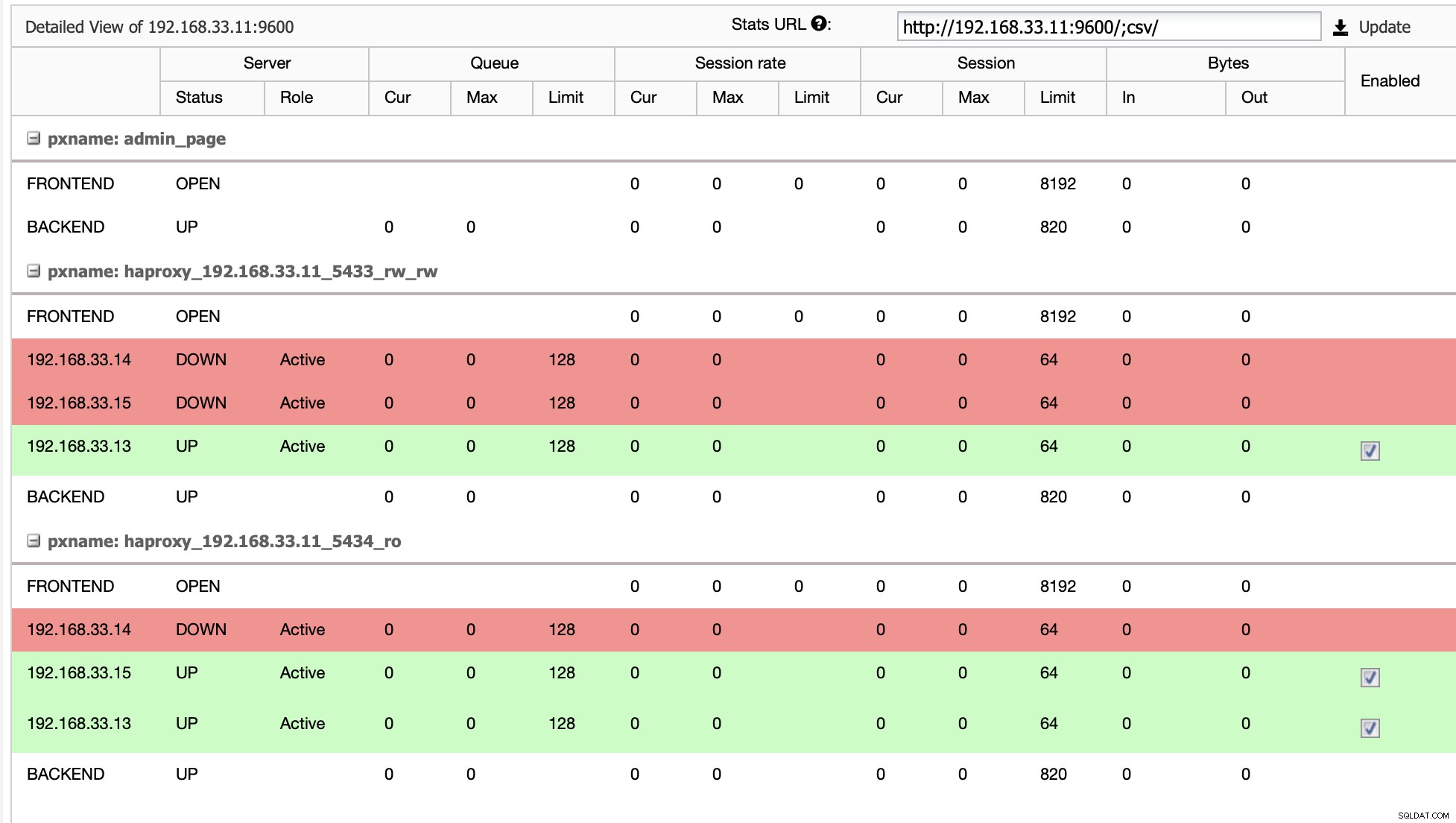
De (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)De (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Topologia atual
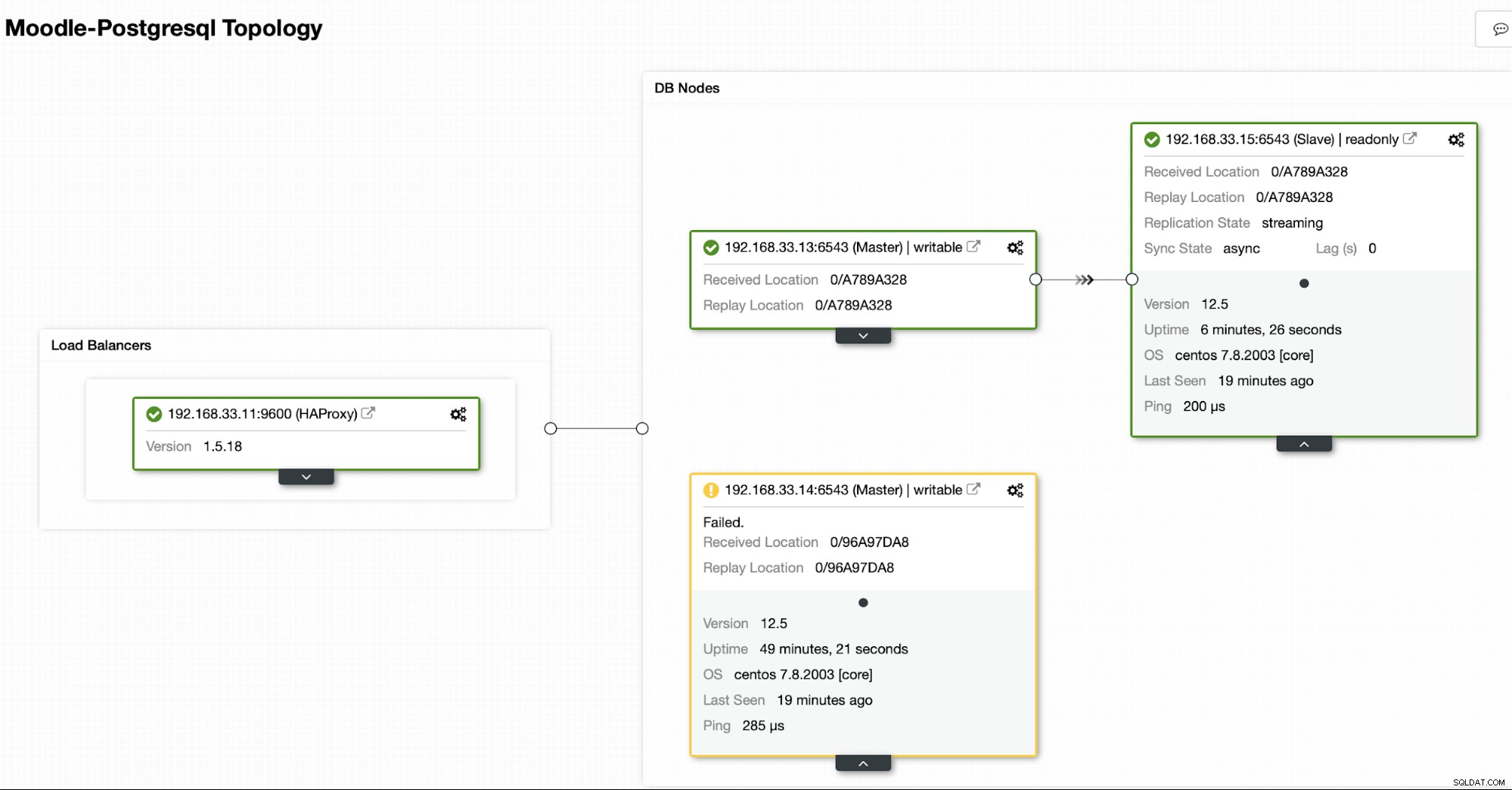
Quando o HAProxy detecta que um de nossos nós, primário ou réplica, está não acessível, marca-o automaticamente como offline. O HAProxy não enviará nenhum tráfego do aplicativo Moodle para ele. Essa verificação é feita por scripts de verificação de integridade configurados pelo ClusterControl no momento da implantação.
Depois que o ClusterControl promove um servidor de réplica para primário, nosso HAProxy marca o primário antigo como offline e coloca o nó promovido online.
Quando o antigo primário estiver online novamente, ele não será sincronizado automaticamente com o novo servidor primário. Precisamos deixá-lo de volta na topologia, e isso pode ser feito através da interface ClusterControl. Isso evitará a possibilidade de perda ou inconsistência de dados, caso queiramos investigar por que esse servidor falhou em primeiro lugar.
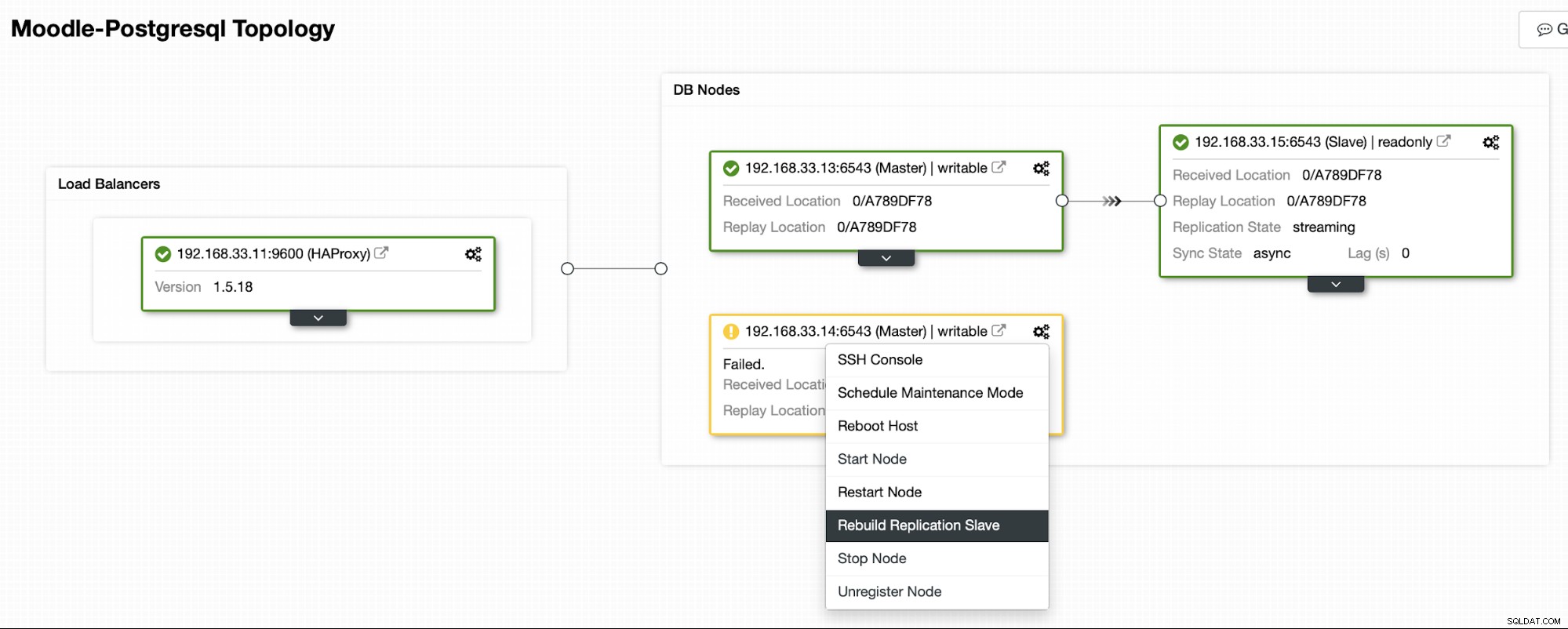
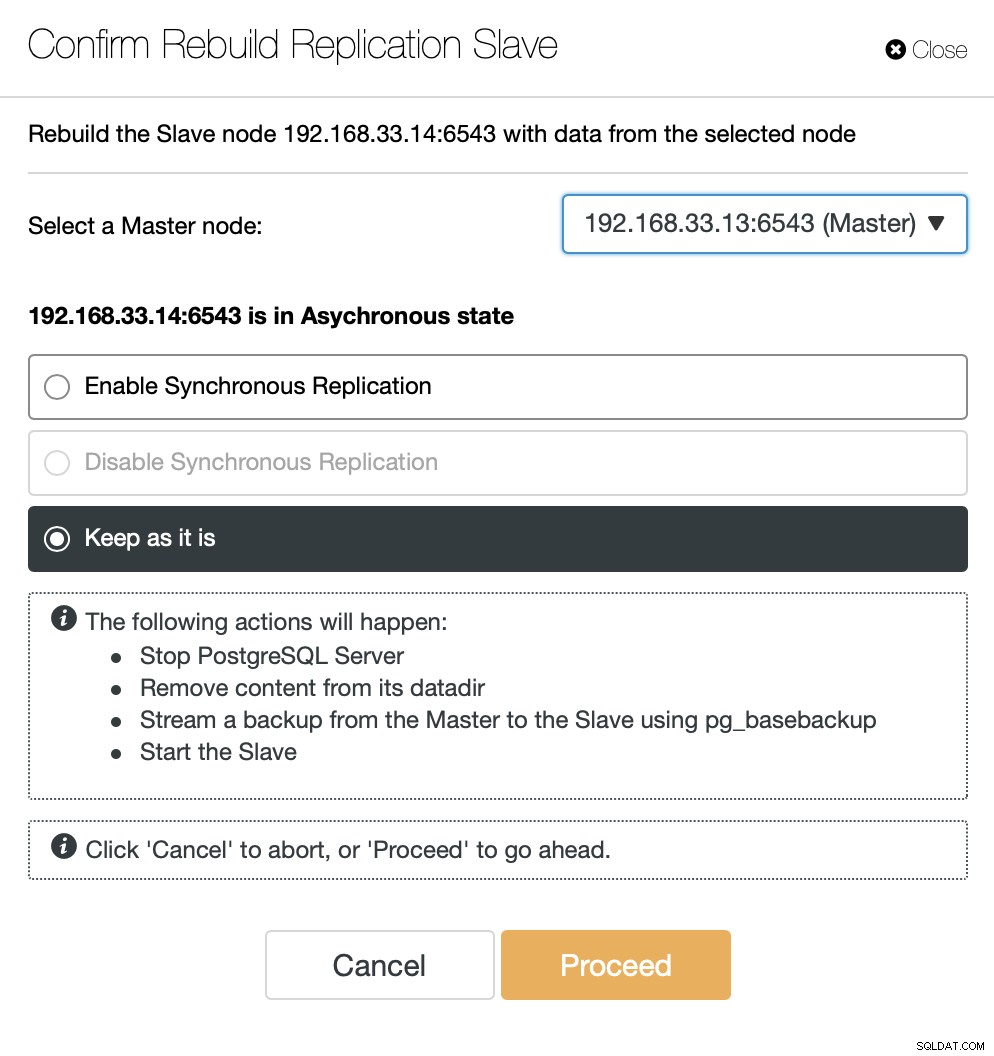
O ClusterControl transmitirá o backup do novo servidor primário e configurará a replicação.
Conclusão
O failover automático é uma parte importante de qualquer banco de dados de produção do Moodle. Ele pode reduzir o tempo de inatividade quando um servidor fica inativo, mas também ao executar tarefas comuns de manutenção ou migrações. É importante acertar, pois é importante que o software de failover tome as decisões corretas.